25
May
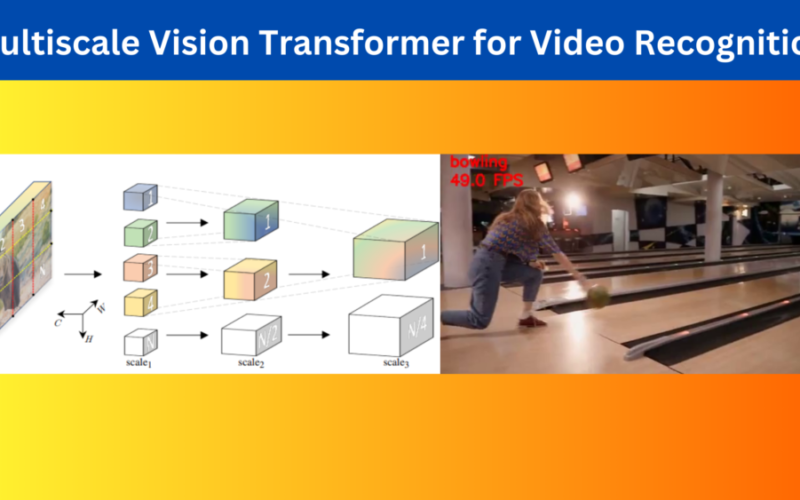
Vision transformers are already good at multiple tasks like image recognition, object detection, and semantic segmentation. However, we can also apply them to data with temporal information like videos. One such use case is using Vision Transformers for video classification. To this end, in this article, we will go over the important parts of the Multiscale Vision Transformer (MViT) paper and also carry out inference using the pretraining model. Figure 1. An example output after passing a bowling video through the Multiscale Vision Transformer model. Although there are several models for this, the Multiscale Vision Transformer model stands out for…