The New Breed of Open Mixture-of-Experts (MoE) Models. In a push to beat the closed-box AI models from the AI Titans, many startups and research orgs have embarked in releasing open MoE-based models. These new breed of MoE-based models introduce many clever architectural tricks, and seek to balance training cost efficiency, output quality, inference performance and much more. For an excellent introduction to MoEs, checkout this long post by the Hugging Face team: Mixture of Experts Explained
We’re starting to see several open MoE-based models achieving near-SOTA or SOTA performance as compared to e.g. OpenAI GPT-4 and Google Gemini 1.5 Pro. And this is great! Here’s a brief summary about four open, powerful MoE-based models introduced in the last ten days.
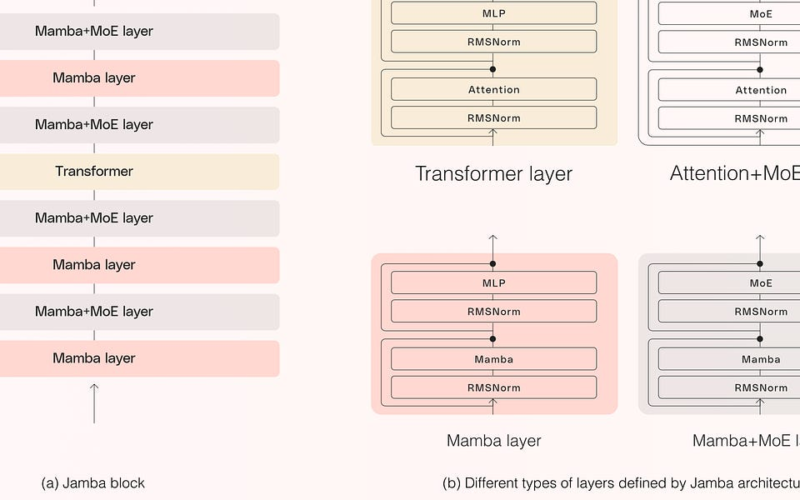
AI21Labs Jamba. Jamba is a model built on top of an SSM-Transformer MoE architecture. The innovation here is to build the model by hybrid interleaving Transformer & SSM layers. Jamba was designed to combinedly address the limitations and benefits of both Transformer and SSM architectures; 1) High quality output, 2) High throughput and 2) low memory requirements. Read more here: Introducing Jamba. Also checkout this iPynb on How to Finetune Jamba.
Alibaba Qwen1.5-MoE-A2.7B. A small MoE model with only 2.7B activated parameters that yet matches the performance of SOTA 7B models like Mistral 7B. The model introduces several architecture innovations -as compared to standard MoE models- for example: combined fine-grained experts, initialisation upcycling, and shared & routing experts. As a result, the model achieves a 75% decrease in training costs and accelerates inference speed by a factor of 1.74, as compared to larger open 7B models, while remaining competitive in most benchmarks. Checkout the paper, repo and demo here: Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters.
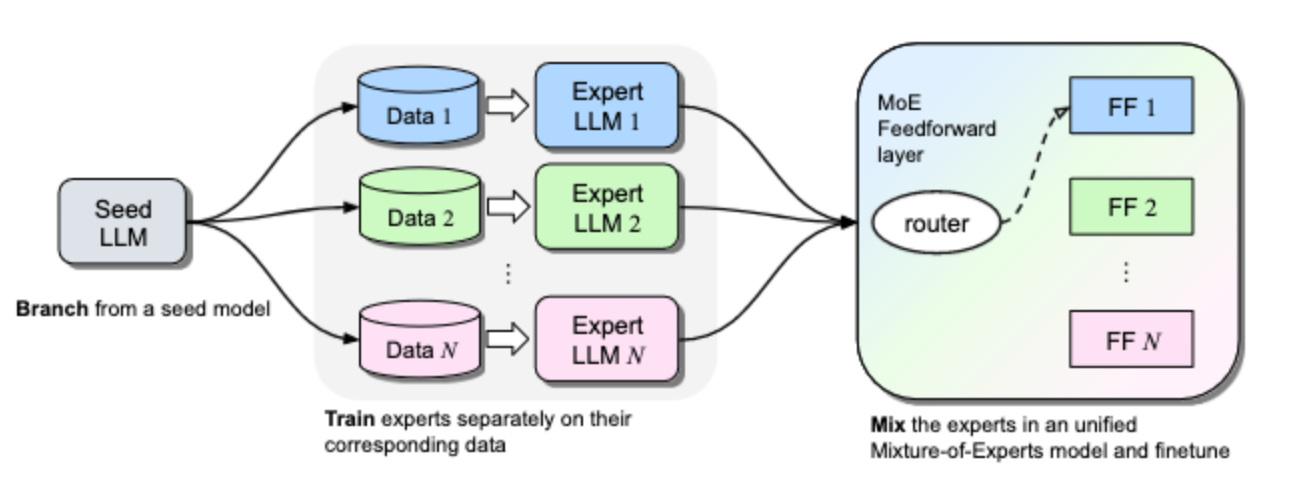
MetaAI BTX method. Similar to Qwen1.5-MoE’s architecture that combines multiple fine-tuned expert LLMs, Meta AI recently introduced a new method called Branch-Train-MiX (BTX). BTX starts from a seed model, which is branched to train experts in embarrassingly parallel fashion with high throughput and reduced communication cost. This produces a super efficient MoE architecture. Paper: Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM.
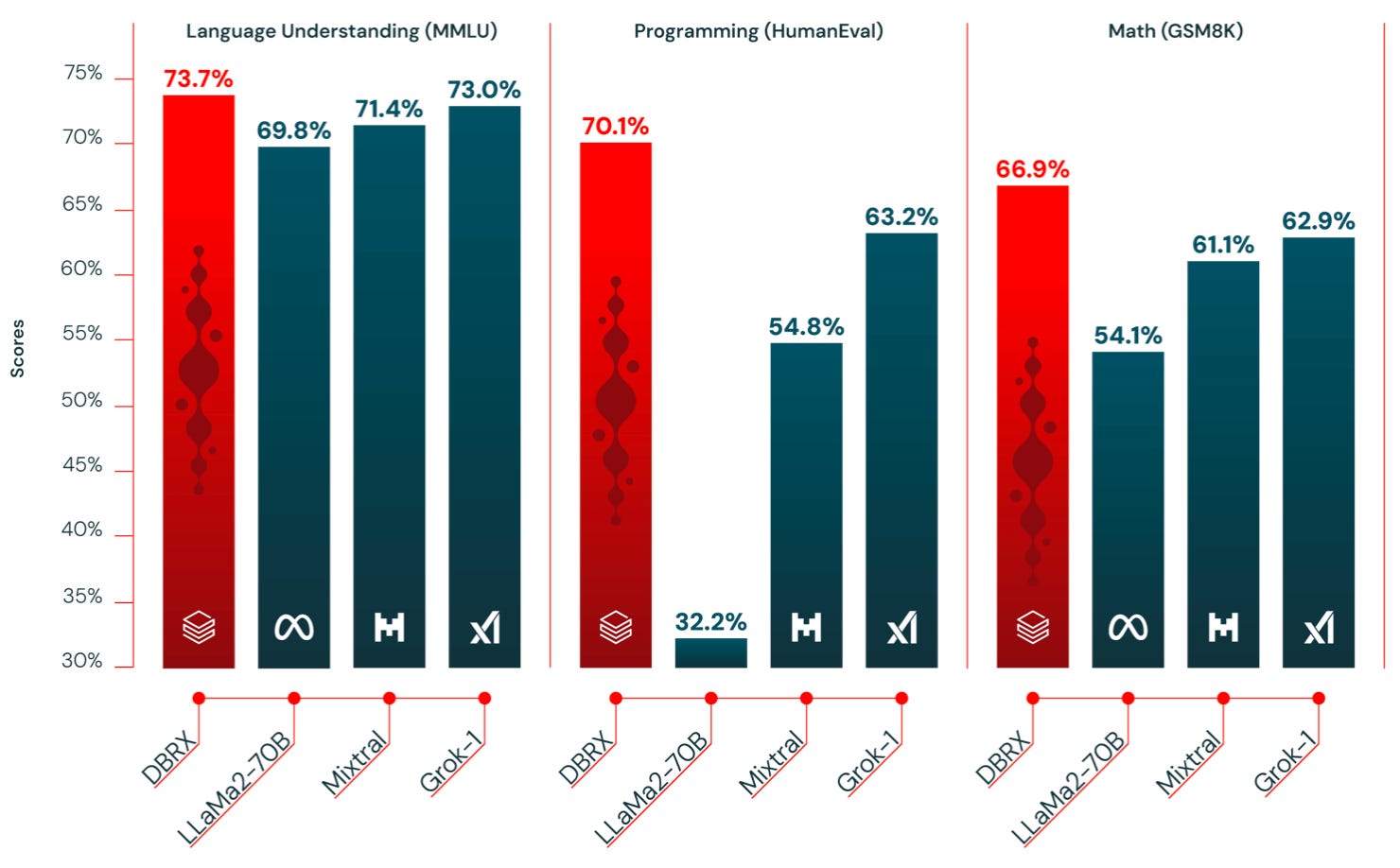
Databricks DBRX 132B MoE. DBRX model uses a fine-grained MoE architecture with 132B parameters of which 36B parameters are active on any input. It was pre-trained on 12T tokens of text and code data. The weights of the base model (DBRX Base) and the finetuned model (DBRX Instruct) are available on Hugging Face under an open license. According to Databricks, DBRX achieves SOTA in performance, cost efficiency, and output quality across open model benchmarks, and beats closed models like GPT-3.5 and Gemini 1.0 Pro. To read more about how DBRX was built its performance, and how to start using it see: Introducing DBRX: A New State-of-the-Art Open LLM
You can try DBRX-Instruct model for free at Perplexity Labs Playground. (Make sure you select the model in the pull down menu.) And if you are interested in running DBRX in a local MacBook environment checkout this repo thread on how to 4-bit quantise DBRX with Apple MLX framework.
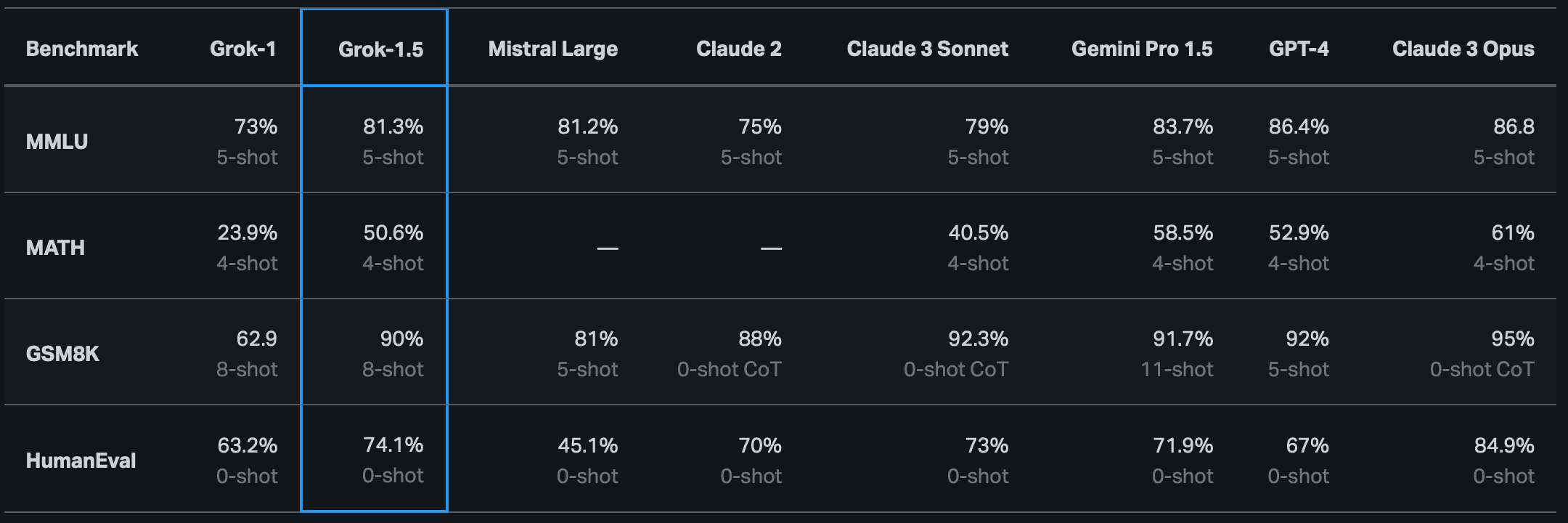
xAI Grok-1.5. A few days ago, the xAI team announced Grok-1.5, which is an open model built on top of Grok-1 base MoE model (repo). The model comes with a 128K context window and is very powerful in coding, RAG, and reasoning tasks. Grok-1.5 was built on a custom distributed training framework based on JAX, Rust, and Kubernetes. According to xAI researchers, Grok-1.5 beats most open models, and achieves near SOTA performance as compared to the likes of Gemini 1.5 Pro or GPT-4. Grok-1.5 will be available in X (formerly Twitter.) In the meantime you can read the blogpost: Announcing Grok-1.5.
Have a nice week.
-
[free tutorial] Diffusion Models for Imaging and Vision (Mar,2024)
-
Probabilistic Time Series Forecasting with Auto Bayesian NNs
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol