21
Nov
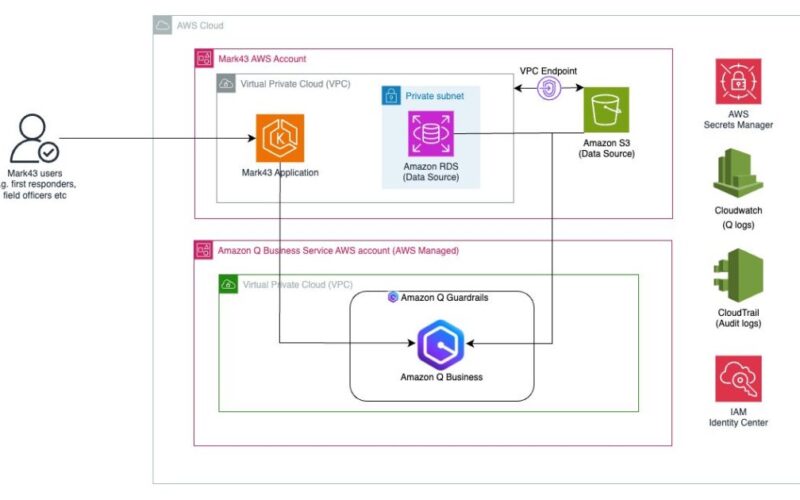
This post is co-written with Lawrence Zorio III from Mark43. Public safety organizations face the challenge of accessing and analyzing vast amounts of data quickly while maintaining strict security protocols. First responders need immediate access to relevant data across multiple systems, while command staff require rapid insights for operational decisions. Mission-critical public safety applications require the highest levels of security and reliability when implementing technology capabilities. Mark43, a public safety technology company, recognized this challenge and embedded generative artificial intelligence (AI) capabilities into their application using Amazon Q Business to transform how law enforcement agencies interact with their mission-critical applications. By embedding…