24
May
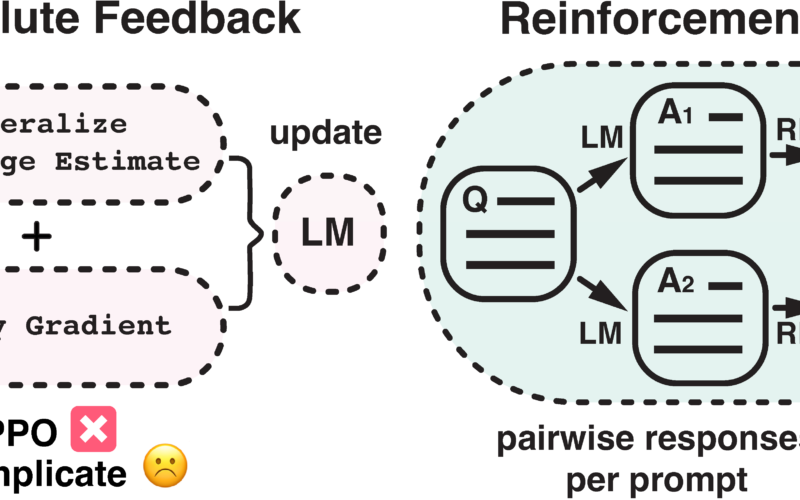
Rethinking the Role of PPO in RLHF TL;DR: In RLHF, there’s tension between the reward learning phase, which uses human preference in the form of comparisons, and the RL fine-tuning phase, which optimizes a single, non-comparative reward. What if we performed RL in a comparative way? Figure 1: This diagram illustrates the difference between reinforcement learning from absolute feedback and relative feedback. By incorporating a new component - pairwise policy gradient, we can unify the reward modeling stage and RL stage, enabling direct updates based on pairwise responses. Large Language Models (LLMs) have powered increasingly capable virtual assistants, such as…