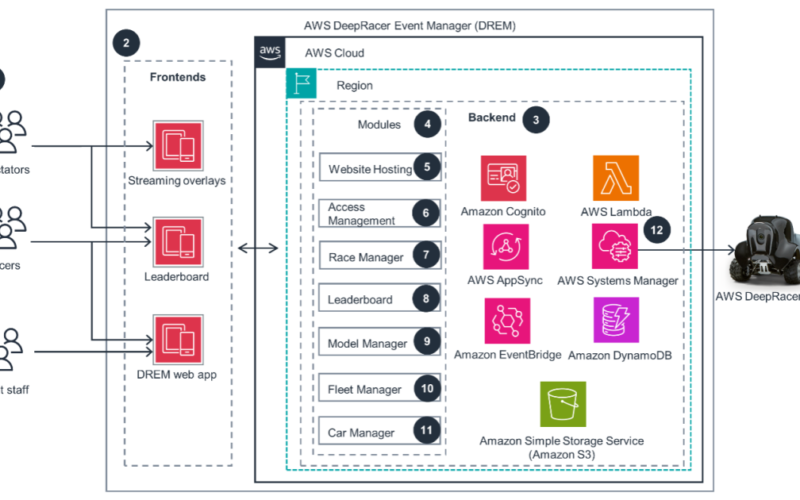
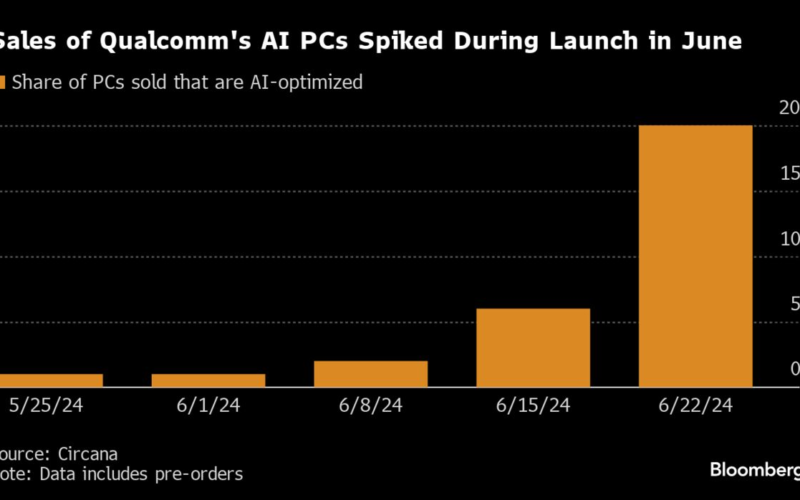
08
Jul
arXiv:2407.03621v1 Announce Type: new Abstract: Large Language Models (LLMs) have an unrivaled and invaluable ability to "align" their output to a diverse range of human preferences, by mirroring them in the text they generate. The internal characteristics of such models, however, remain largely opaque. This work presents the Injectable Realignment Model (IRM) as a novel approach to language model interpretability and explainability. Inspired by earlier work on Neural Programming Interfaces, we construct and train a small network -- the IRM -- to induce emotion-based alignments within a 7B parameter LLM architecture. The IRM outputs are injected via layerwise addition at…