We are slowly but steadily approaching the end of 2023. I thought this was a good time to write a brief recap of the major developments in the AI research, industry, and open-source space that happened in 2023.
Of course, this article is only a glimpse of the most relevant topics that are on the top of my mind. I recommend checking out the monthly Research Highlights and Ahead of AI #4-12 issues in the Archive for additional coverage.
This year, we have yet to see any fundamentally new technology or methodology on the AI product side. Rather, this year was largely focused on doubling down on what has worked last year:
An interesting rumor was that GPT-4 is a mixture of experts (MoE) models consisting of 16 submodules. Each of these 16 submodules is rumored to have 111 billion parameters (for reference, GPT-3 has 175 billion parameters).
The fact that GPT-4 is an MoE is probably true, even though we don’t know for sure yet. One trend is that industry researchers share less and less information in their papers than they used to. For example, while GPT-1, GPT-2, GPT-3, and InstructGPT papers disclosed the architecture and training details, the GPT-4 architecture is a closely guarded secret. Or to provide another example: while Meta AI’s first Llama paper detailed the training dataset that was used to train the models, the Llama 2 model keeps this information private. On that note Stanford introduced the The Foundation Model Transparency Index last week, according to which Llama 2 leads at 54%, and GPT-4 ranks third at 48%.
Of course, it may be unreasonable to demand that companies share their trade secrets. It’s still an interesting trend worth mentioning because it looks like we’ll continue on this route in 2024.
Regarding scaling, another trend this year was scaling the input context length. For example, one of the main selling points of the GPT-4 competitor Claude 2 is that it supports up to 100k input tokens (GPT-4 is currently limited to 32k tokens), which makes it particularly attractive for generating summaries of long documents. The fact that it supports PDF inputs makes it especially useful in practice.
As I recall, the open-source community was heavily focused on latent diffusion models (such as Stable Diffusion) and other computer vision models last year. Diffusion models and computer vision remain as relevant as ever. However, an even bigger focus of the open-source and research communities was on LLMs this year.
The explosion of open-source (or rather openly available) LLMs is partly owed to the release of the first pretrained Llama model by Meta, which, despite its restrictive license, inspired a lot of researchers and practitioners: Alpaca, Vicuna, Llama-Adapter, Lit-Llama, just to name a few.
A few months later, Llama 2, which I covered in more detail in Ahead of AI #11: New Foundation Models, largely replaced Llama 1 as a more capable base model and even came with finetuned versions.
However, most open-source LLMs are still pure text models, even though methods such as the Llama-Adapter v1 and Llama-Adapter v2 finetuning methods promise to turn existing LLMs into multimodal LLMs.
The one noteworthy exception is the Fuyu-8B model, which was released only a few days ago on October 17th.
It’s noteworthy that Fuyu passes the input patches directly into a linear projection (or embedding layer) to learn its own image patch embeddings rather than relying on an additional pretrained image encoder like other models and methods do (examples include LLaVA and MiniGPT-V. This greatly simplifies the architecture and training setup.
Besides the few multimodal attempts mentioned above, the largest research focus is still on matching GPT-4 text performance with smaller models in the <100 B parameter range, which is likely due to hardware resource costs and constraints, limited data access, and requirements for shorter development time (due to the pressure to publish, most researchers can’t afford to spend years on training a single model).
However, the next breakthrough in open-source LLMs does not have to come from scaling models to larger sizes. It will be interesting to see if MoE approaches can lift open-source models to new heights in 2024.
Interestingly, on the research front, we also saw a few alternatives to transformer-based LLMs in 2023, including the recurrent RWKV LLM and the convolutional Hyena LLM, that aim to improve efficiency. However, transformer-based LLMs are still the current state of the art.
Overall, open source has had a very active year with many breakthroughs and advancements. It’s one of the areas where the whole is greater than the sum of its parts. Hence, it saddens me that some individuals are actively lobbying against open-source AI. But I hope we can keep the positive momentum in building more efficient solutions and alternatives rather than just becoming more dependent on ChatGPT-like products released by big tech companies.
To end this section on a positive note, thanks to the open source and research communities, we saw small and efficient models that we can run on a single GPU, like the 1.3B parameter phi1.5, 7B Mistral, and 7B Zephyr come closer to the performance of the large proprietary models, which is an exciting trend that I hope will continue in 2024.
I see open-source AI as the primary path forward for developing efficient and custom LLM solutions, including finetuned LLMs based on our personal or domain-specific data for various applications. if you follow me on social media, you probably saw me talking about and tinkering with Lit-GPT, which is an LLM open-source repository that I actively contribute to. But while I am a big proponent of open-source, I am also a big fan of well-designed products.
Since ChatGPT was released, we have seen LLMs being used for pretty much everything. Readers of this article have probably already used ChatGPT, so I don’t have to explain that LLMs can indeed be useful for certain tasks.
The key is that we use them for the “right” things. For instance, I probably don’t want to ask ChatGPT about the store hours of my favorite grocery store. However, one of my favorite use cases is fixing my grammar or helping me brainstorm with rephrasing my sentences and paragraphs. Bigger picture-wise, what underlies LLMs is the promise of increased productivity, which you probably also already experienced.
Besides LLMs for regular text, Microsoft’s and GitHub’s Copilot coding assistant is also maturing, and more and more people are starting to use it. Earlier this year, a report by Ark-Invest estimated that code assistants reduce the time to complete a coding task by ~55%.
Whether it’s more or less than 55% is debatable, but if you have used a code assistant before, you notice that these can be super helpful and make tedious coding-related tasks easier.
One thing is certain: coding assistants are here to stay, and they will probably only get better over time. Will they replace human programmers? I hope not. But they will undoubtedly make existing programmers more productive.
What does that mean for StackOverflow? The State of AI report includes a chart that shows the website traffic of StackOverflow compared to GitHub, which might be related to the increasing adoption of Copilot. However, I believe even ChatGPT/GPT-4 is already very helpful for coding-related tasks. I suspect that ChatGPT is also partly (or even largely) responsible for the decline in StackOverflow traffic.
Hallucination
The same problem still plagues LLMs as in 2022: they can create toxic content and tend to hallucinate. Throughout the year, I discussed several methods to address this, including reinforcement learning with human feedback (RLHF) and Nvidia’s NeMO Guardrails. However, these methods remain bandaids that are either too strict or not strict enough.
So far, there is no method (or even idea for a method) to address this issue 100% reliably and in a way that doesn’t diminish the positive capabilities of LLMs. In my opinion, it all comes down to how we use an LLM: Don’t use LLMs for everything, use a calculator for math, regard LLMs as your writing companion and double-check its outputs, and so forth.
Also, for specific business applications, it might be worthwhile exploring retrieval augmented augmentation (RAG) systems as a compromise. In RAG, we retrieve relevant document passages from a corpus and then condition the LLM-based text generation on the retrieved content. This approach enables models to pull in external information from databases and documents versus memorizing all knowledge.
Copyrights
More urgent problems are the copyright debates around AI. According to Wikipedia, “The copyright status of LLMs trained on copyrighted material is not yet fully understood.” And overall, it seems that many rules are still being drafted and amended. I am hoping that the rules, whatever they are, will be clear so that AI researchers and practitioners can adjust and act accordingly. (I wrote more about AI and copyright debates here.)
Evaluation
An issue plaguing academic research is that the popular benchmarks and leaderboards are considered semi-broken because the test sets may have leaked and have become LLM training data. This has become a concern with phi-1.5 and Mistral, as I discussed in my previous article.
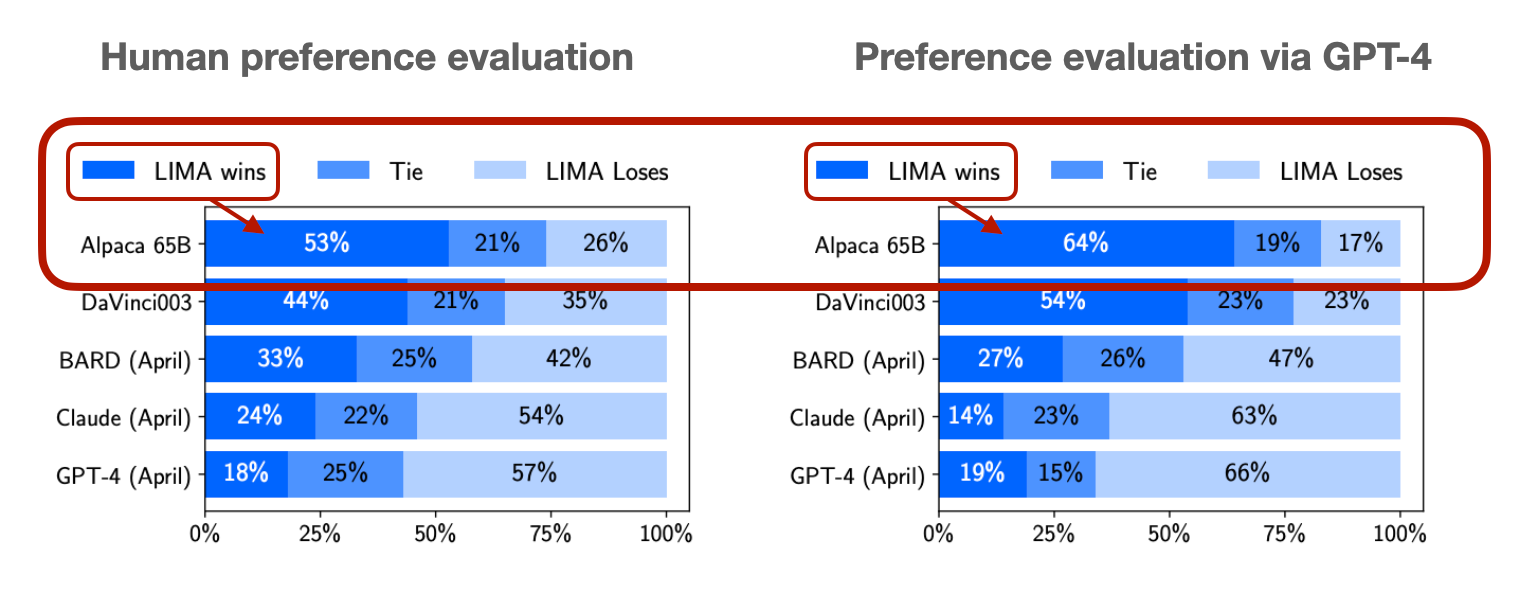
A popular but less easy way to automate LLM evaluation is to ask humans for their preferences. Alternatively, many papers also rely on GPT-4 as the second-best way.
Revenue
Generative AI is currently still in an exploratory stage. Of course, we all experienced that text and image generators can be helpful for specific applications. However, whether they can generate a positive cash flow for companies is still a hotly debated topic due to the expensive hosting and runtime costs. For example, it was reported that OpenAI had a $540 million loss last year. On the other hand, recent reports say that OpenAI is now earning $80 million each month, which could offset or exceed its operating costs.
Fake Imagery
One of the bigger issues related to generative AI, which is particularly apparent on social media platforms at the moment, is the creation of fake images and videos. Fake images and videos have always been a problem, and similar to how software like Photoshop lowered the barrier to entry for fake content, AI is taking this to the next level.
Other AI systems are designed to detect AI-generated content, but these are neither reliable for text nor images or videos. The only way to somewhat curb and combat these issues is to rely on trustworthy experts. Similar to how we do not take medical or legal advice from random forums or websites on the internet, we probably also shouldn’t be trusting images and videos from random accounts on the internet without double-checking.
Dataset Bottlenecks
Related to the copyright debate mentioned earlier, many companies (including Twitter/X and Reddit) closed their free API access to increase revenue but also to prevent scrapers from collecting the platforms’ data for AI training.
I’ve come across numerous advertisements from companies specializing in dataset-related tasks. Although AI may regrettably lead to the automation of certain job roles, it appears to be simultaneously generating new opportunities.
One of the best ways to contribute to open-source LLM progress may be in building a platform to crowdsource datasets. With this, I mean writing, collecting, and curating datasets that have explicit permission for LLM training.
When the Llama 2 model suite was released, I was excited to see that it included models that were finetuned for chat. Using reinforcement learning with human feedback (RLHF), Meta AI increased both the helpfulness and harmlessness of their models — If you are interested in a more detailed explanation, I have a whole article dedicated to RLHF here.
I always thought of RLHF as a really interesting and promising approach, but besides InstructGPT, ChatGPT, and Llama 2, it was not widely used. Hence, I was surprised to find a chart on the rising popularity of RLHF. I certainly didn’t expect it because it’s still not widely used.
Since RLHF is a bit complicated and tricky to implement, most open-source projects are still focused on supervised finetuning for instruction finetuning.
A recent alternative to RLHF is Direct Preference Optimization (DPO). In the corresponding paper, the researchers show that the cross entropy loss for fitting the reward model in RLHF can be used directly to finetune the LLM. According to their benchmarks, it’s more efficient to use DPO and often also preferred over RLHF/PPO regarding response quality.
DPO does not seem to be widely used yet. However, to my excitement, two weeks ago, we got the first openly available LLM trained via DPO via Lewis Tunstall and colleagues, which seems to outperform the bigger Llama-2 70b Chat model trained via RLHF:
However, it’s worth noting that RLHF is not explicitly used to optimize benchmark performance; its primary optimization goals are “helpfulness” and “harmlessness” as assessed by human users, which is not captured here.
Last week, I gave a talk at Packt’s generative AI conference a few weeks ago, highlighting that one of the most prominent use cases for text models remains classification. For example, think of common tasks such as email spam classification, document categorization, classifying customer reviews, and labeling toxic speech on social media.
In my experience, it’s possible to get really good classification performance with “small” LLMs, such as DistilBERT, using only a single GPU.
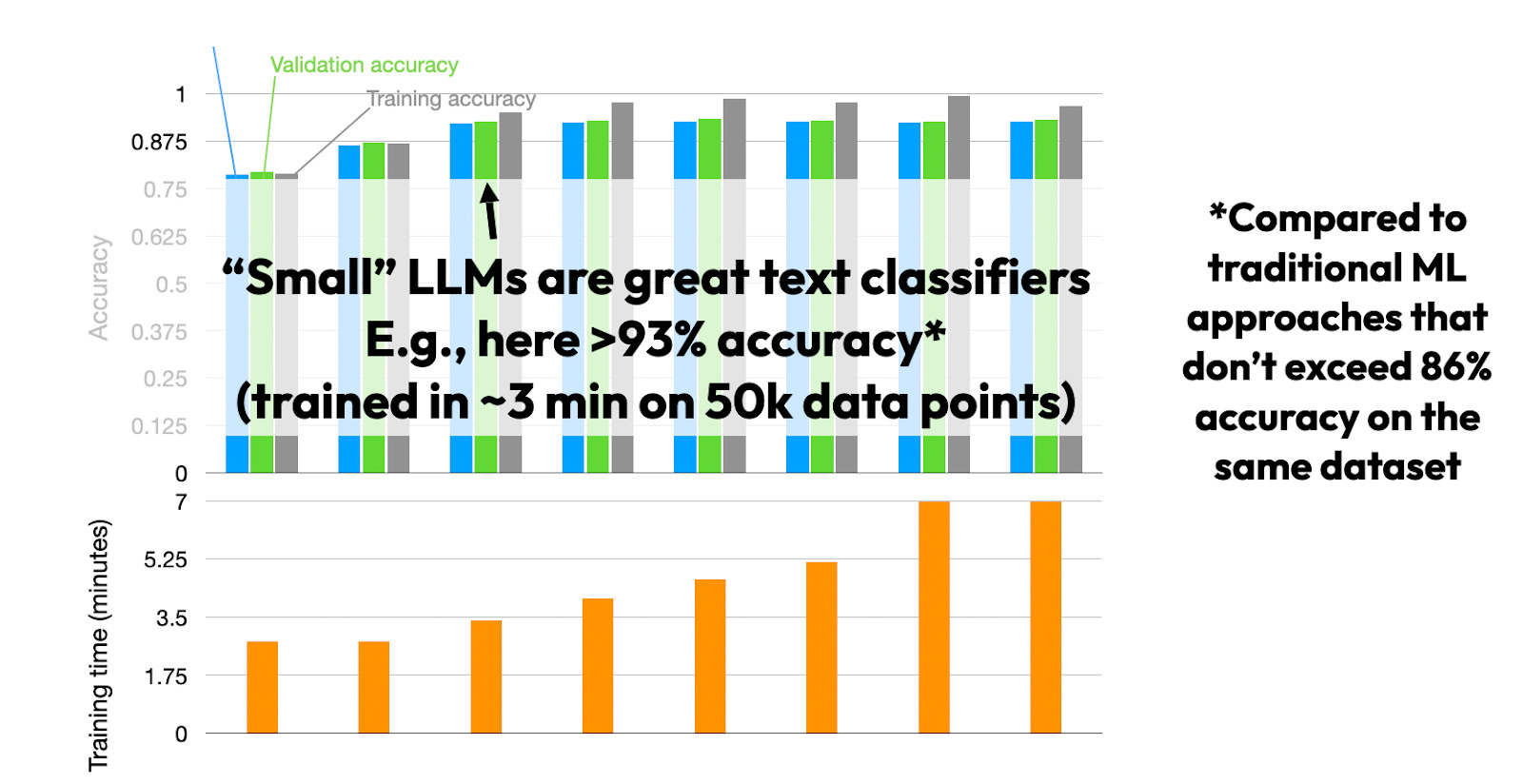
I posted text classification with small LLMs as an exercise in Unit 8 of my Deep Learning Fundamentals class this year, where Sylvain Payot even achieved >96% prediction accuracy on the IMDB movie review dataset by finetuning an off-the-shelf available Roberta model. (For reference, the best classic machine learning-based bag-of-words model I trained on that dataset achieved only 89% accuracy).
Now, that being said, I haven’t seen any new major work or trends on LLMs for classification yet. Most practitioners still use BERT-based encoder models or encoder-decoder models like FLAN-T5, which came out in 2022. That could be because these architectures still work surprisingly and satisfactorily well.
In 2022, I wrote A Short Chronology Of Deep Learning For Tabular Data, covering many interesting deep learning-based approaches to tabular data. However, similar to LLMs for classification mentioned above, there haven’t been that many developments on the tabular dataset front either, or I have just been too busy to notice.
In 2022, Grinsztajn et al. wrote a paper on Why do tree-based models still outperform deep learning on tabular data? I believe the main takeaway that tree-based models (random forests and XGBoost) outperform deep learning methods for tabular data on small- and medium-sized datasets (10k training examples) is still true.
On that note, after being around for almost 10 years, XGBoost came out with a big 2.0 release that featured better memory efficiency, support for large datasets that don’t fit into memory, multi-target trees, and more.
While this year has been very focused on LLMs, there have been many developments on the computer vision front. Since this article is already very long, I won’t cover the latest computer vision research. However, I have a standalone article on the State of Computer Vision Research 2023 from my attendance at CVPR 2023 this summer:
Besides research, computer vision-related AI has been inspiring new products and experiences that have been maturing this year.
For example, when I attended the SciPy conference in Austin this summer, I saw the first truly driverless Waymo cars roaming the streets.
And from a trip to the movie theater, I also saw AI usage is becoming increasingly popular in the movie industry. A recent example is the de-aging of Harrison Ford in “Indiana Jones 5”, where the filmmakers trained an AI using old archive material of the actor.
Then, there are generative AI capabilities that are now firmly integrated into popular software products. A recent example is Adobe’s Firefly 2.
Predictions are always the most speculative and challenging aspect. Last year, I predicted that we would see more applications of LLMs in domains beyond text or code. One such example was HyenaDNA, an LLM for DNA. Another was Geneformer, a transformer pretrained on 30 million single-cell transcriptomes designed to facilitate predictions in network biology.
In 2024, LLMs will increasingly transform STEM research outside of computer science.
Another emerging trend is the development of custom AI chips by various companies, driven by GPU scarcity due to high demand. Google will double-down on its TPU hardware, Amazon has introduced its Trainium chips, and AMD might be closing the gap with NVIDIA. And now, Microsoft and OpenAI also started developing their own custom AI chips. The challenge will be ensuring full and robust support for this hardware within major deep learning frameworks.
On the open-source front, we still lag behind the largest closed-source models. Currently, the largest openly available model is Falcon 180B. This might not be too concerning because most people lack access to the extensive hardware resources required to handle these models anyway. Instead of bigger models, I’m more eager to see more open-source MoE models consisting of multiple smaller submodules, which I discussed earlier in this article.
I’m also optimistic about witnessing increased efforts in crowdsourced datasets and the rise of DPO as a replacement for supervised fine-tuning in state-of-the-art open-source models.
This magazine is personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.
Your support means a great deal! Thank you!
Source link
lol