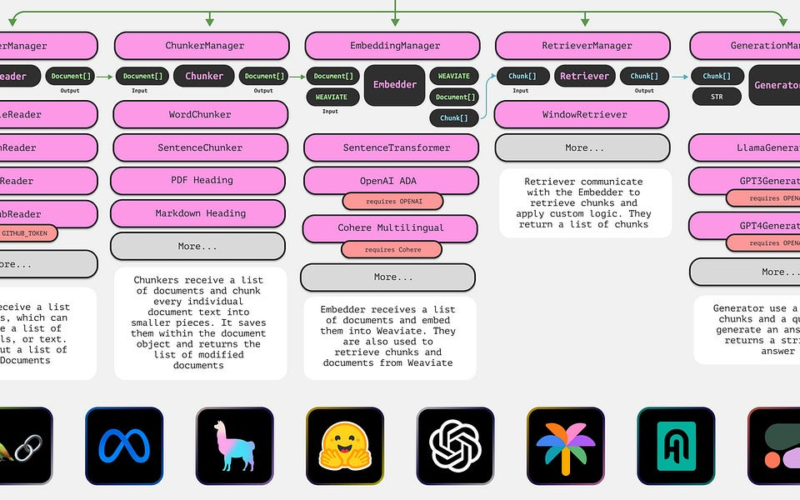
The GenAI RAG House Revisited. Since Facebook AI introduced RAG three years ago, RAG systems have evolved from Naive to Advanced, and then to Modular RAG. But Modular RAG also added more complexity, components, interfaces, etc. to the LLMOps pipeline.
Many naive RAG and advanced RAG projects never made it to prod. I know many companies that have spent a lot effort and money in building enterprise RAG apps, only to realise they couldn’t produce accurate, reliable results at a manageable cost. Building a RAG system that is scalable, cost-efficient, accurate, and modular requires deep expertise. Here are a few things to consider when building a modern, modular RAG system.
Understanding RAG design choices and its implications. In this blogpost, Michal describes the many design choices required to build a RAG, and how those RAG design choices can impact the performance, behaviour, and cost of your RAG app, sometimes in non-obvious ways. Blogpost: Designing RAGs: A guide to Retrieval-Augmented Generation design choices.
Lessons learnt from implementing large RAG systems. This is a great blogpost written as an intermediate practitioner’s guide to building RAGs. Hrishi is a veteran in RAG battles and has earned all the medals. He writes about “some things you may not have considered, some things we’ve had to (painfully) discover, and some things we believe every RAG system should have.” Blogpost: Better RAG: From Basics to Advanced (Part 1, 2 & 3).
Implementing RAG at production scale. Productising RAG at scale is really hard indeed. Cohere just announced Command-R, a generative model optimised for long context RAG interoperating with external APIs and tools. Command-R addresses the main challenge of RAG: Balancing high efficiency, strong accuracy, low latency, and high throughput at production scale. Blogpost: Command-R: Retrieval Augmented Generation at Production Scale.
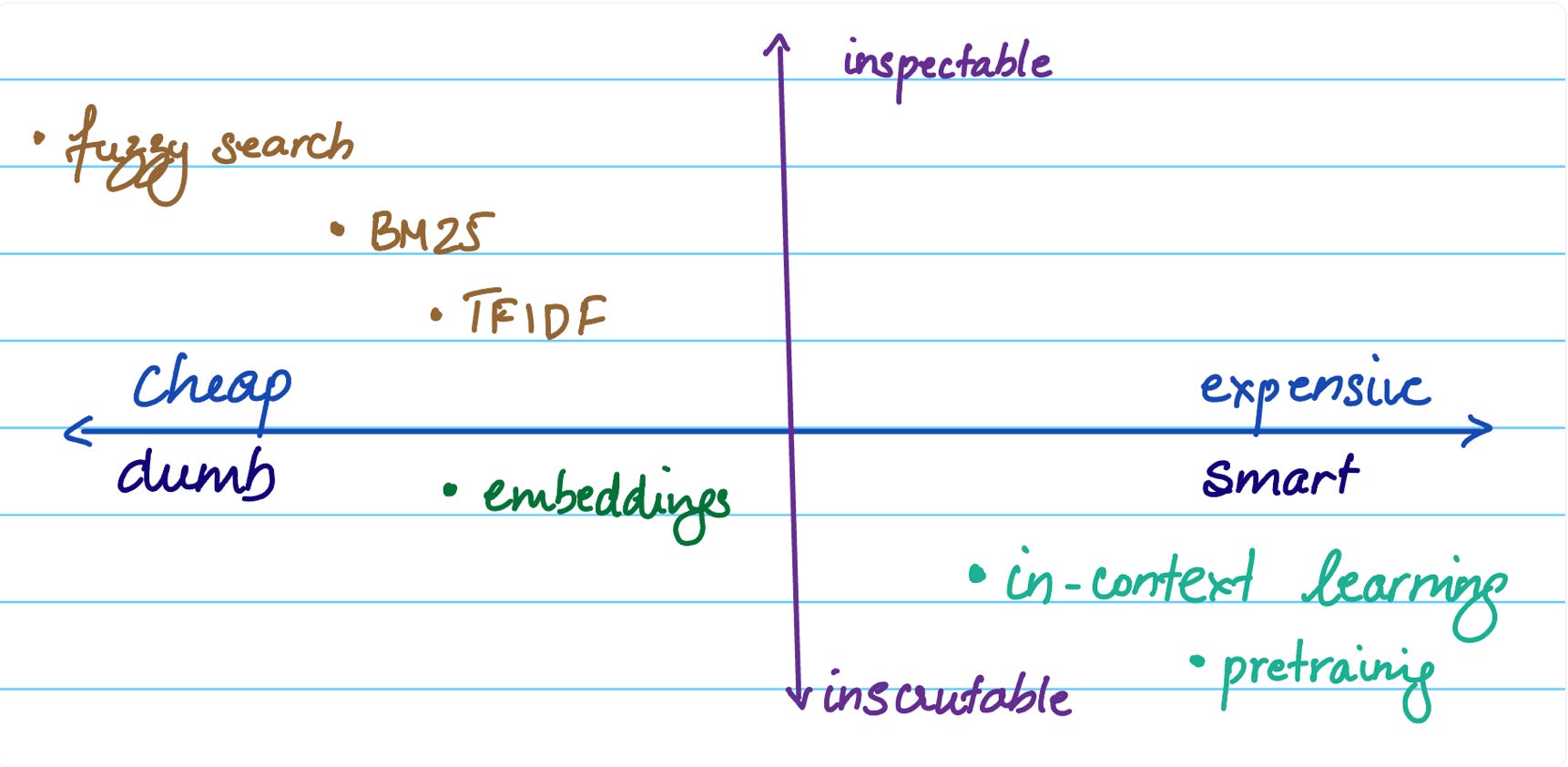
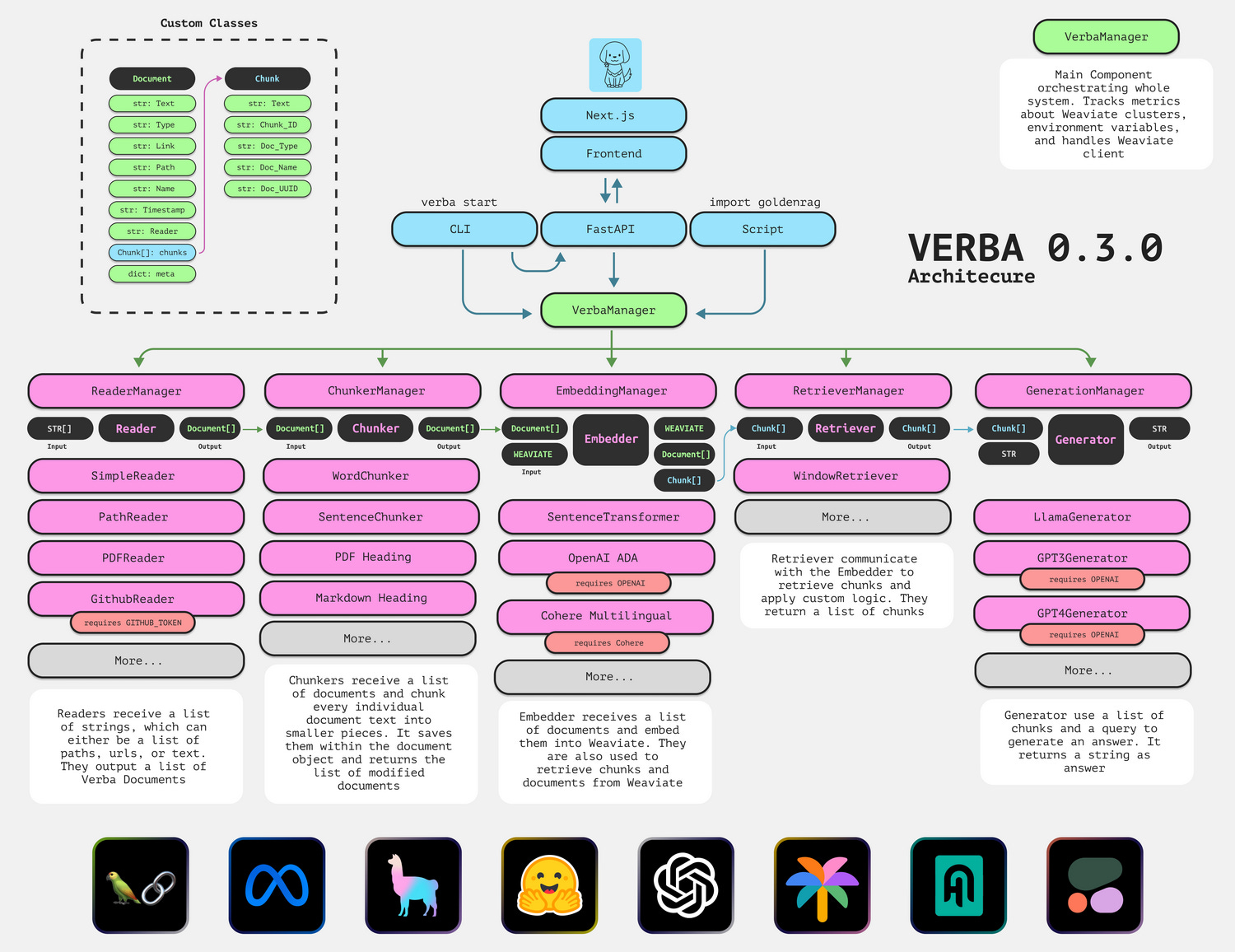
Avoiding black-box, proprietary AI by leveraging Modular RAG & Opensource AI. A popular way to build RAG protos has been to integrate calls to proprietary AI APIs (e.g GPT-4) with RAG components using LangChain or Llamaindex. But this has proven complex, often expensive to maintain, and not always reliable. To address these challenges, Weaviate recently announced Verba: an open-source, modular RAG system that is both fully customisable and adaptable. It’s easy to use out-of-the-box with a nice UI. Verba also enables smooth integration with many AI libs, and both closed & open-source LLMs. Blogpost, repo and demo here: Verba: Building an Open Source, Modular RAG Application.
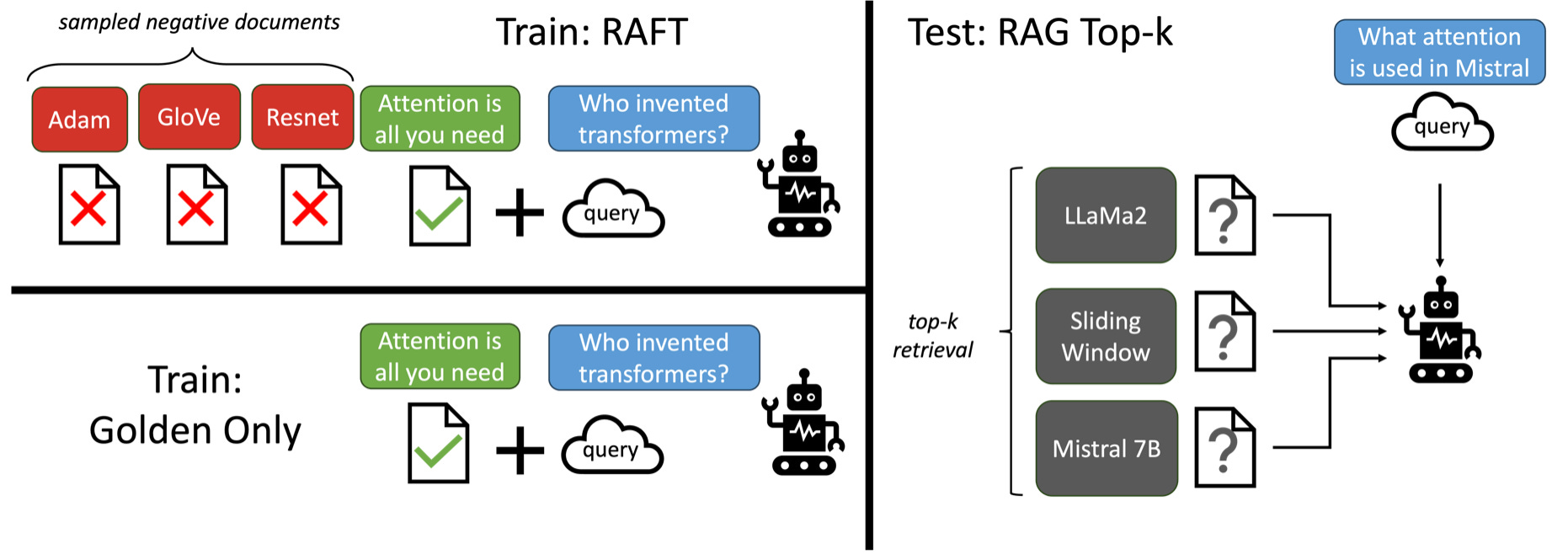
Improving RAG with domain-specific knowledge. A group of researchers from Berkeley, Meta AI & MS Research just introduced RAFT (Retrieval-Augmented Fine-Tuning), a new method that combines RAG and domain-specific fine-tuning (DSF). RAFT solves many of the challenges that RAG and DSF can’t solve alone on their own. Blogpost, paper here: RAFT: Adapting Language Model to Domain Specific RAG.
The downside of cosine-similarity and leveraging ColBERT v2. in RAG. Many RAG apps use cosine-similarity matching between docs and query embeddings as default. In a new paper from Netflix, (Is Cosine-Similarity of Embeddings Really About Similarity?) the researchers caution against blindly using cosine-similarity.
Cosine-similarity is referred as a “no interaction” approach due to its inability to capture the complex relationships between query and document terms. To address this issue, ColBERT v.2 comes to the rescue with “late interaction” evaluation by which the query and document representations occurs late in the process, after both have been independently encoded. Read more here: What is ColBERT and Late Interaction and Why They Matter in Search?

Combining RAG with Knowledge Graphs. Knowledge graphs can combine unstructured and structured data, and can capture the context behind the data. The idea here is to provide better context to the RAG via the knowledge graph, and improve results as compared to just using semantic search.
Just in case, here’s a brief, good intro to Knowledge Graphs.
A few hours ago, Yohei open sourced MindGraph, a prototype for generating and querying against a large knowledge graph with AI.
This is a short, free course on Knowledge Graphs for RAG. You’ll learn how to build a RAG question-answering system to chat with a knowledge graph of structured text documents using LangChain and Neo4j.
Combining Chain-of-Thought with RAG. A group of AI researchers recently introduced RAT (Retrieval-Augmented Thoughts), a new method that iterative revises a chain of thoughts with the help of information retrieval. The researchers claim that RAT significantly improves LLM reasoning and generation ability in long-horizon generation tasks, while hugely mitigating hallucinations. Checkout the paper, code, and demo here: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation.
Have a nice week.
-
AutoDev: A Magic AI Auto Coding Wizard with Multi-Language Support
-
A Review of Salesforce MORAI Model for Time-series Forecasting
-
Amazon Chronos: Pretrained Models for Probabilistic Time Series Forecasting
-
DeepSeek-VL: An Open Source Model for Real-World Vision-Language Apps
-
Training ML Models on Encrypted Data Using Fully Homomorphic Encryption
-
Data Interpreter: An LLM Agent For Data Science (paper, repo)
-
Apple MMI: Methods, Analysis & Insights from Multimodal LLM Pre-training
-
MoAI: Mixture of All Intelligence for Large Language-Vision Models (paper, repo)
-
Cohere Wikipedia v3 – 250M Paragraphs/ Embedding, +300 Languages
-
VidProM – 1.6 Million Text-to-Video Prompts, 6.69 Million AI Generated Videos
-
A Toolbox with Interpretable ML Methods for Comparing Datasets
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol