By Arvind Narayanan, Sayash Kapoor, and Seth Lazar
Preventing harms from AI is important. The AI safety community calls this the alignment problem. The vast majority of development effort to date has been on technical methods that modify models themselves. We’ll call this model alignment, as opposed to sociotechnical ways to mitigate harm.
The main model alignment technique today is Reinforcement Learning with Human Feedback (RLHF), which has proven essential to the commercial success of chatbots. But RLHF has come to be seen as a catch-all solution to the dizzying variety of harms from language models. Consequently, there is much hand-wringing about the fact that adversaries can bypass it. Alignment techniques aren’t keeping up with progress in AI capabilities, the argument goes, so we should take drastic steps, such as “pausing” AI, to avoid catastrophe.
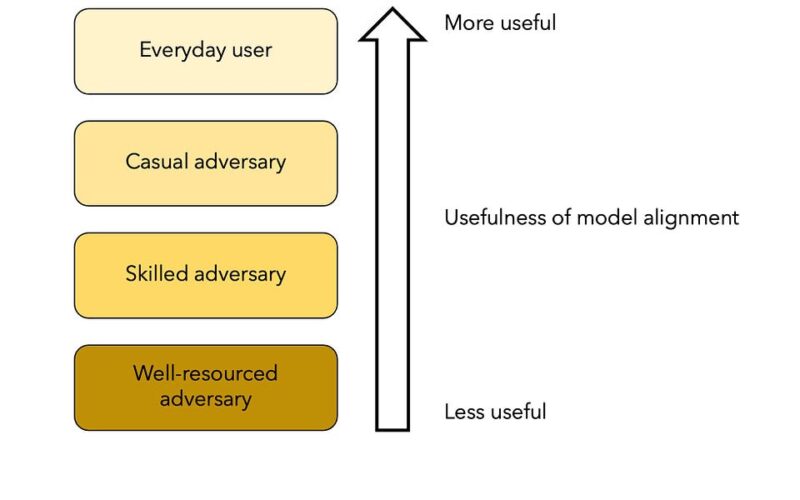
In this essay, we analyze why RLHF has been so useful. In short, its strength is in preventing accidental harms to everyday users. Then, we turn to its weaknesses. We argue that (1) despite its limitations, RLHF continues to be effective in protecting against casual adversaries (2) the fact that skilled and well-resourced adversaries can defeat it is irrelevant, because model alignment is not a viable strategy against such adversaries in the first place. To defend against catastrophic risks, we must look elsewhere.
While RLHF is the dominant alignment approach today, our arguments are more broadly relevant. The limits we describe apply to the other alignment techniques that have been used so far, such as supervised fine tuning and prompt crafting. There is evidence that alignment methods that happen after the pre-training stage have intrinsic vulnerabilities. Pre-training interventions could be more robust, but may incur a trade-off in terms of model capabilities that may affect legitimate applications. Other alignment techniques such as input or output filtering using a different model fall outside the scope of our analysis.
Until 2021, it would have been unthinkable to release a product like ChatGPT to mainstream consumers rather than developers. That’s not because of capability limitations: GPT-3 was already good enough for many of the purposes that ChatGPT is now being used for, such as writing homework essays. Rather, the main barrier was LLMs’ tendency to parrot and amplify offensive stereotypes and ideologies present in their training data. As one study showed, all it took to get GPT-3 to do this was to prompt it with a phrase like “Two Muslims walked into a”. In short, LLMs were too unreliable to be deployed as consumer-facing products.
RLHF has very substantially solved this problem, and by solving it OpenAI created a multi-billion dollar industry where one didn’t exist before. In fact, just a couple of weeks before ChatGPT was launched, Meta put out Galactica and then pulled it down within days because it tended to produce biased nonsense.
Of course, it remains possible to jailbreak chatbots, including ChatGPT, but this doesn’t happen accidentally — it must be done intentionally. This has allowed chatbot developers to legitimately disclaim some measure of responsibility for anything harmful that is subsequently done with them. There is a genre of misguided research and journalism that ignores this distinction. It is silly to claim that it’s the developer’s responsibility if a chatbot produces biased text or insults the user after the user tricks it into doing so.
There are a couple of important caveats. Model alignment, especially RLHF, is hard to get right, and there have been aligned chatbots that were nonetheless harmful. And alignment doesn’t matter if the product concept is itself creepy. Finally, for combatting more serious kinds of accidental harms, such as those that might arise from autonomous agents, a narrowly technical approach is probably not enough.
First, consider a well-funded entity, perhaps even a government, aiming to use the model for strategic, offensive purposes, such as finding zero-day vulnerabilities. They don’t need to use ChatGPT. They are perfectly capable of training their own models, and the cost is dropping exponentially.
Model alignment may be useless even against much weaker adversaries, such as a scammer using it to generate websites with fraudulent content, or a terrorist group using AI for instructions on how to build a bomb. If they have even a small budget, they can pay someone to fine tune away the alignment in an open model (in fact, such de-aligned models have now been publicly released). And recent research suggests that they can fine tune away the alignment even for closed models.
Even if there is draconian regulation to prohibit the release of new open models, and global cooperation to enforce such regulations, the open models that have already been released are more than sufficient for harmful applications like disinformation and scams. Unlike a government, these adversaries don’t need state-of-the-art capabilities.
This means that we must prepare for a world in which unaligned models exist — either because threat actors trained them from scratch or because they modified an existing model. We must instead look to defend the attack surfaces that attackers might target using unaligned models, such as social media (in the case of disinformation) or software codebases (in the case of the use of LLMs to find security vulnerabilities).
If we set aside the relatively powerful adversaries discussed above, what we have left are everyday users who might occasionally do harmful things. A teenager might use LLMs for bullying or harassment (say, by generating dozens of messages appearing to come from different people).
The critical observation about this set of threats is that regular people use products, not technologies. They don’t have the time or expertise to install an open-source model and tinker with it to generate harmful outputs.
Productization enables many additional defenses. None is bulletproof, but they don’t need to be. For instance, it may be true that changing the sampling temperature can defeat alignment, but most chatbots don’t allow changing the sampling temperature in the first place.
Similarly, it may be that users can jailbreak chatbots by crafting a specific, seemingly nonsensical adversarial string. But products tend to be centralized, so product developers can easily scan for such adversarial strings to identify user behavior that might violate their terms of use.
Model alignment raises the bar for the adversary and strengthens other defenses. A wave of recent research has shown that RLHF is brittle. Yet, despite being insufficient on its own, it is extremely useful in the broader context of product safety.
The weaknesses of RLHF have led to panicked commentary. Panic would be appropriate if we see model alignment as analogous to software security: Individual failures can be catastrophic and can cause irreversible damage (like data loss).
This is the correct analogy for LLMs integrated into applications with access to personal data, such as Bard’s integration into Google Docs and Gmail. Prompt injection is a serious risk: An attacker may be able to steal a user’s personal data simply by sending them a malicious email. When the LLM processes the email, it may be tricked into performing attacker-specified actions. In such applications, treating model alignment as the primary line of defense is extremely dubious.
But if we’re talking about the use of a vanilla chatbot to generate problematic text, such severe risks don’t arise. In this case, a better analogy is instead content moderation on social media, where individual failures typically have low-severity consequences, such as the spread of misinformation (although they can be harmful in the aggregate). Consider how poorly social media content moderation works: It has tended to be largely reactive and requires a large amount of taxing manual work. There is some automation, but it is mostly limited to simple classifiers and fingerprint-matching techniques.
Compared to this approach, model alignment is a big improvement. Whereas content moderation tends to lag far behind in combating new forms of online harms, aligned LLMs have some ability to recognize potentially harmful use that developers haven’t considered ex ante. They are often able to identify the morally salient features of situations at a level of sophistication comparable to that of a really good philosophy PhD student, which is a remarkable accomplishment, and might provide foundations for more robust forms of alignment in the future. While such filters can be made to fail, the worst that can happen is a fallback to content-moderation-style reactive monitoring of logs to identify and block offending users.
As AI systems are given more autonomy and used in more consequential situations, alignment will become more important, and the content moderation analogy may no longer be appropriate. Will the progress that’s been made so far serve as the stepping stone to more secure forms of alignment, or are there intrinsic limits to what we can expect out of model alignment? We’ll have to wait and see. At any rate, the fact that researchers are vigorously probing the limits of current alignment techniques is good news.
RLHF and other model alignment techniques help make generative AI products safer and nicer to use. But we shouldn’t be surprised or alarmed that they are imperfect. They remain useful despite their weaknesses. And when it comes to catastrophic AI risks, it’s best not to put any stock in model alignment until and unless there are fundamental breakthroughs that lead to new alignment techniques.
-
For overviews of the research on the brittleness of RLHF, see this Twitter thread by Shayne Longpre or this post by Nathan Lambert.
-
Roel Dobbe presents lessons for AI safety from the field of system safety, which has long dealt with accidents and harm in critical systems. The first lesson is to think about safety as a property of the overall socio-technical system rather than a single technical component such as LLMs.
-
For more on why LLMs’ moral reasoning ability is philosophically interesting, see this talk by Seth Lazar.
We are grateful to Rishi Bommasani and Solon Barocas for feedback on a draft of this essay.
Source link
lol