20
May
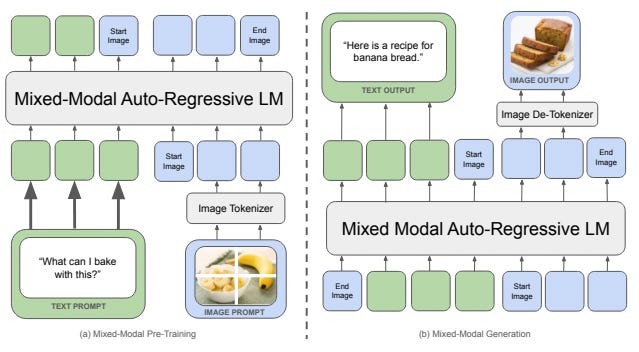
In the wake of OpenAI's recent announcement of GPT-4o, a new model that processes and generates text, audio, and images in real-time, it's clear that the race for multimodal AI is heating up. Not to be outdone, researchers at Meta AI (FAIR) have just released a fascinating new paper introducing Chameleon, a family of early-fusion foundation models that also seamlessly blend language and vision. In this post, we'll do a deep dive into the Chameleon paper, exploring how it pushes the boundaries of multimodal AI in different but equally exciting ways compared to GPT-4o. We’ll also speculate a bit on…