AI is moving fast. Every day, researchers release thousands of new papers, models, and tools. AImodels.fyi sifts through the deluge to bring you the breakthroughs that matter. Today, we’re spotlighting a development that’s flying under the radar but could reshape the landscape of AI vision: Recap-DataComp-1B.
This story is trending on the site but hasn’t gained much traction on some social media channels, so you might’ve missed it. Here’s why it deserves your attention:
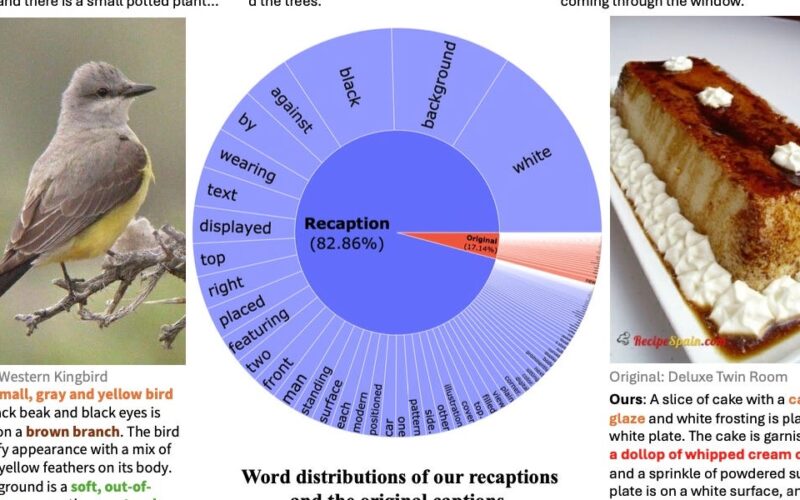
Web-crawled image-text datasets have been the foundation of AI vision systems for years, but they’ve always struggled with noise. Even carefully curated datasets suffer from misaligned captions, vague descriptions, and irrelevant text. These issues have hindered the development of more advanced vision-language models.
Source link
lol