This post is a guest post co-written with Tengyu Ma and Wen Phan from Voyage AI.
Organizations today have access to vast amounts of data, much of it proprietary, which holds the potential to unlock valuable insights when used effectively in generative artificial intelligence (AI) applications. Retrieval Augmented Generation (RAG) is a powerful technique designed to tap into this reservoir of information. By dynamically pulling relevant data from these extensive databases during the response generation process, RAG enables AI models to produce more accurate, relevant, and contextually rich outputs.
Embedding models are crucial components in the RAG architecture, serving as the foundation for effectively identifying and retrieving the most relevant information from a large dataset. These models convert large volumes of text into compact, numerical representations, allowing the system to quickly sift through and match query-related data with unprecedented precision. By facilitating a more efficient and accurate retrieval process, embedding models make sure that the generative component of RAG is fed with the most pertinent information.
In this post, we provide an overview of the state-of-the-art embedding models by Voyage AI and show a RAG implementation with Voyage AI’s text embedding model on Amazon SageMaker Jumpstart, Anthropic’s Claude 3 model on Amazon Bedrock, and Amazon OpenSearch Service. Voyage AI’s embedding models are the preferred embedding models for Anthropic. In addition to general-purpose embedding models, Voyage AI offers domain-specific embedding models that are tuned to a particular domain.
RAG architecture and embedding models
RAG is the predominant design pattern for enterprise chatbots where a retrieval system fetches validated sources and documents that are pertinent to the query and inputs them to a large language model (LLM) to generate a response. It combines the generative capabilities of models with the informational breadth found in vast databases, enabling the model to pull relevant external documents to enhance its responses. This results in outputs that are not only contextually rich but also factually accurate, significantly boosting the reliability and utility of LLMs across diverse applications.
Let’s briefly review RAG using the following figure.
RAG systems are empowered by semantic search using dense-vector representations of the documents called embeddings. These vectors are stored in a vector store, where they can be efficiently retrieved later. At query time, a query is also converted into a vector and then used to find and retrieve similar documents stored in the vector store via a k-nearest neighbor (k-NN) search against the document vector representations. Finally, the retrieved documents along with the query are used to prompt the generative model, often resulting in higher-quality responses and fewer hallucinations.
Embedding models are neural network models that transform queries and documents into embeddings. The retrieval quality is solely decided by how the data is represented as vectors, and the effectiveness of embedding models is evaluated based on their accuracy in retrieving relevant information. Therefore, the retrieval quality of the embedding models is highly correlated with the quality of the RAG system responses—to make your RAG more successful, you should consider improving your embeddings. Check out this blog for a detailed explanation.
Voyage AI’s general-purpose and domain-specific embedding models
Voyage AI develops cutting-edge embedding models with state-of-the-art retrieval accuracy. voyage-large-2 is Voyage’s most powerful generalist embedding model, outperforming popular competing models. Voyage also offers voyage-2, a base generalist embedding model optimized for latency and quality. The following table summarizes the Voyage embedding models currently available on SageMaker JumpStart.
| Voyage AI Model | SageMaker JumpStart Model ID | Description |
voyage-2 |
voyage-2-embedding |
General-purpose embedding model optimized for a balance between cost, latency, and retrieval quality |
voyage-large-2 |
voyage-large-2-embedding |
General-purpose embedding model optimized for retrieval quality |
voyage-code-2 |
voyage-code-2-embedding |
Domain-specific embedding model optimized for code retrieval (17% better than alternatives) |
In addition to general-purpose embedding models, Voyage AI offers domain-specific ones that are tuned to a particular domain. These domain-specific embedding models are trained on massive domain-specific datasets, allowing them to deeply understand and excel in that domain. For example, Voyage’s code embedding model (voyage-code-2) outperforms general-purpose embedding models on code-related data documents, achieving about a 15% improvement over the next best model. This performance gap over the next best general-purpose embedding improves even more for datasets requiring deeper code understanding. See voyage-code-2: Elevate Your Code Retrieval for voyage-code-2 details. More recently, Voyage released a legal embedding model (voyage-law-2) that is optimized for legal retrieval and tops the MTEB leaderboard for legal retrieval. See Domain-Specific Embeddings and Retrieval: Legal Edition (voyage-law-2) for voyage-law-2 details. Voyage AI plans to continue releasing additional domain-specific embedding models in the near future, including finance, healthcare, and multi-language. For a list of all available Voyage AI embedding models, see Embeddings.
Voyage AI offers API endpoints for embedding models, making it seamless to integrate with other components of your RAG stack. The Voyage AI embedding models are available on AWS Marketplace and deployable as Amazon SageMaker endpoints within your account and VPC, eliminating security and compliance concerns. As part of SageMaker JumpStart, you can deploy Voyage AI embedding models with a few clicks and start running your RAG stack on AWS.
Solution overview
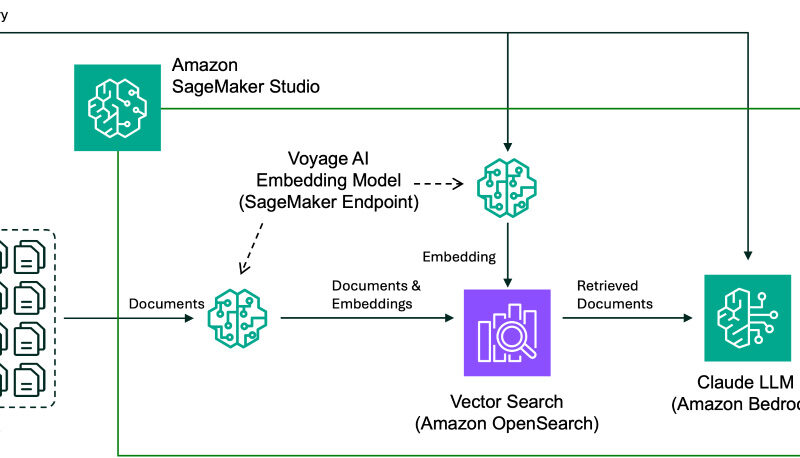
In this RAG solution, we use Voyage AI embedding models deployed with SageMaker JumpStart to demonstrate an example using the Apple 2022 annual report (SEC Form 10-K) as the corpus to retrieve from. Specifically, we deploy the SageMaker model package of the voyage-large-2 model. For the LLM, we use the Anthropic Claude 3 Sonnet model on Amazon Bedrock. We use OpenSearch Service as the vector store. You can also follow along with the notebook. The following diagram illustrates the solution architecture.

SageMaker JumpStart is the machine learning (ML) hub of SageMaker that offers one-click access to over 350 open source and third-party models. These models can be discovered and deployed through the Amazon SageMaker Studio UI or using the SageMaker Python SDK. SageMaker JumpStart provides notebooks to customize and deploy foundation models into your VPC.

Anthropic’s Claude 3 models are the next generation of state-of-the-art models from Anthropic. For the vast majority of workloads, Sonnet is faster on inputs and outputs than Anthropic’s Claude 2 and 2.1 models, with higher levels of intelligence. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic through an API, making it straightforward to build generative AI applications. To follow along, be sure to request model access to Anthropic Claude 3 Sonnet on Amazon Bedrock.
Amazon OpenSearch Service is a managed service that makes it straightforward to deploy, operate, and scale OpenSearch, a popular open source, distributed search analytics suite derived from Elasticsearch. OpenSearch provides the ability to do vector search via the k-NN search.
Prerequisites
To follow along, you need to create an OpenSearch Service domain. For the purposes of this walkthrough, the Easy create option is fine. Keep the Enable fine-grained access control option selected. Select Create master user and provide a user name and password. After the domain has been created, the domain details will have the domain endpoint, which you’ll need—along with the user name and password—to access your OpenSearch instance. You don’t need to worry about creating an index or inserting data. We use the OpenSearch Python client to work with our vector store in the walkthrough.
Deploy Embedding model endpoint
To use voyage-large-2, you need to subscribe to the SageMaker model package in AWS Marketplace. For instructions, see Subscribe to the model package. Choosing the model card in the SageMaker JumpStart UI will also bring you to the model listing page on AWS Marketplace.
After you’re subscribed, you can initialize and deploy the embedding model as a SageMaker endpoint as follows:
# Set embedding endpoint configuration
(embedding_model_id, embedding_model_version, embedding_instance_type) = (
"voyage-large-2-embedding",
"*",
"ml.g5.xlarge", # See AWS Marketplace model package for supported instance types
)
# Instantiate embedding model from JumpStart
from sagemaker.jumpstart.model import JumpStartModel
embedding_model = JumpStartModel(
model_id=embedding_model_id,
model_version=embedding_model_version,
instance_type=embedding_instance_type,
)
# Deploy model as inference endpoint. This can take several minutes to deploy (5 to 10 minutes)
embedding_endpoint = embedding_model.deploy()Vectorize Documents
With the embedding endpoint deployed, you can index your documents for retrieval.
Transform and chunk documents
You need a list of strings to invoke the deployed voyage-large-2 model. For many documents, like our example annual report, each string is a semantically meaningful chunk of text. There are several ways you can load and chunk documents for vectorization. The code in this section is just one example; feel free to use what suits your data source and files.
In this walkthrough, we load and chunk the source PDF file with the LangChain PyPDFLoader (which uses pypdf) and recursive character text splitter:
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = PyPDFLoader("apple-10k-2022.pdf")
document_chunks = loader.load_and_split(
RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
)In practice, selecting the text splitting chunk size and overlap requires some experimentation. The are many techniques for appropriately chunking documents for high-quality retrieval, but that is beyond the scope of this post.
Generate document embeddings
You can now vectorize your documents—or more precisely, your document chunks. See the following code:
# Set batch size
BATCH_SIZE = 45
In [ ]:
# Vectorize chunks in batches
index_list = []
for i in range(0, len(chunk_list), BATCH_SIZE):
docs_playload = {
"input": chunk_list[i:i + BATCH_SIZE],
"input_type": "document",
"truncation": "true",
}
embed_docs_response = embedding_endpoint.predict(json.dumps(docs_playload))
doc_embeddings_list = [d["embedding"] for d in embed_docs_response["data"]]
index_list += [
{"document": document, "embedding": embedding}
for document, embedding in zip(chunk_list[i:i + BATCH_SIZE], doc_embeddings_list)
]Create a vector store index
The next step is to populate your OpenSearch vector search index with the document embeddings using the OpenSearch Python client:
# Populate index with document, embedding, and ID
for id, i in zip(range(0, len(index_list)), index_list):
index_response = opensearch_client.index(
index=INDEX_NAME_OPENSEARCH,
body={
"document": i["document"],
"embedding": i["embedding"],
},
id=id,
refresh=True,
)Retrieve relevant documents
With your indexed vector store, you can now use embeddings to find relevant documents to your query:
# Set number of documents to retrieve
TOP_K = 3
In [ ]:
# Set vector search payload
vector_search_payload = {
"size": TOP_K,
"query": {"knn": {"embedding": {"vector": query_embedding, "k": TOP_K}}},
}
In [ ]:
vector_search_response = opensearch_client.search(
index=INDEX_NAME_OPENSEARCH,
body=vector_search_payload,
)
The following is a formatted semantic search result of the top three most-relevant document chunks, indicating the index ID, similarity score, and the first several characters of the chunk:
ID: 4
Score: 0.7956404
Document: under Section 404(b) of the Sarbanes-Oxley Act (15 U.S.C. 7262(b)) by the registered public accounting firm that prepared or issued its audit report. ☒
Indicate by check mark whether the Registrant is a shell company (as defined in Rule 12b-2 of the Act).
Yes ☐ No ☒
The aggregate market value of the voting and non-voting stock held by non-affiliates of the Registrant, as of March 25, 2022, the last business day of the Registrant’s most recently completed second fiscal quarter, was approximately $2,830,067,000,000. Solely for purposes of this disclosure, shares of common stock held by executive officers and directors of the Registrant as of such date have been excluded because such persons may be deemed to be affiliates. This determination of executive officers and directors as affiliates is not necessarily a conclusive determination for any other purposes. 15,908,118,000 shares of common stock were issued and outstanding as of October 14, 2022.
ID: 5
Score: 0.7367379
Document: 15,908,118,000 shares of common stock were issued and outstanding as of October 14, 2022.
DOCUMENTS INCORPORATED BY REFERENCE
Portions of the Registrant’s definitive proxy statement relating to its 2023 annual meeting of shareholders are incorporated by reference into Part III of this Annual Report on Form 10-K where indicated. The Registrant’s definitive proxy statement will be filed with the U.S. Securities and Exchange Commission within 120 days after the end of the fiscal year to which this report relates.
ID: 178
Score: 0.7263324
Document: Note 3 – Financial Instruments
Cash, Cash Equivalents and Marketable Securities
The following tables show the Company’ s cash, cash equivalents and marketable securities by significant investment category as of September 24, 2022 and September 25, 2021 (in millions):
2022
Adjusted Cost
Unrealized Gains
Unrealized Losses
Fair Value
Cash and Cash Equivalents
Current Marketable Securities
Non-Current Marketable Securities
Cash $ 18,546 $ — $ — $ 18,546 $ 18,546 $ — $ —
Level 1 :
Money market funds 2,929 — — 2,929 2,929 — —
Mutual funds 274 — (47) 227 — 227 —
Subtotal 3,203 — (47) 3,156 2,929 227 —
Level 2 :
U.S. Treasury securities 25,134 — (1,725) 23,409 338 5,091 17,980
U.S. agency securities 5,823 — (655) 5,168 — 240 4,928
Non-U.S. government securities 16,948 2 (1,201) 15,749 — 8,806 6,943 Certificates of deposit and time deposits 2,067 — — 2,067 1,805 262 —
Commercial paper 718 — — 718 28 690 —
Corporate debt securities 87,148 9 (7,707) 79,450 — 9,023 70,427
The top retrieved document chunk (ID 4 with a score of 0.7956404) contains a statement that provides a direct answer to our query:
The aggregate market value of the voting and non-voting stock held by non-affiliates of the Registrant, as of March 25, 2022, the last business day of the Registrant’s most recently completed second fiscal quarter, was approximately $2,830,067,000,000.
This additional context will enable Claude to provide a response that answers your query.
Generate a retrieval augmented response
You can now prompt Claude to use the retrieved documents to answer your query:
# Create retrieval-augmented prompt
rag_prompt = f"""Human:
INSTRUCTIONS:
Answer the QUERY using the CONTEXT text provided below. Keep your answer
grounded in the facts of the CONTEXT. If the CONTEXT doesn’t contain the
facts to answer the QUERY just respond with "I do not have enough context
to respond to this query.".
QUERY: {query}
CONTEXT: {context}
Assistant:
"""
Next initialize the Amazon Bedrock client to invoke Anthropic’s Claude3 Sonnet model in us-east-1.
# List available LLMs on Amazon Bedrock
bedrock_client = boto3.client('bedrock', region_name="us-east-1")
bedrock_fm = bedrock_client.list_foundation_models()
print([(m["modelId"], m["modelName"]) for m in bedrock_fm["modelSummaries"]])
In [ ]:
# Set Bedrock LLM model ID
LLM_MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0"
In [ ]:
bedrock_runtime_client = boto3.client('bedrock-runtime', region_name="us-east-1")
In [ ]:
# Invoke LLM inference
try:
llm_rag_response = bedrock_runtime_client.invoke_model(
modelId=LLM_MODEL_ID,
body=json.dumps(rag_payload),
accept="application/json",
contentType="application/json",
)
except botocore.exceptions.ClientError as error:
print("Client error")
raise error
Claude produces a correct response that answers the query using the context provided:
According to the context provided, "The aggregate market value of the voting and non-voting stock held by non-affiliates of the Registrant, as of March 25, 2022, the last business day of the Registrant's most recently completed second fiscal quarter, was approximately $2,830,067,000,000."
Generate a response without retrieved documents
For comparison, let’s see how Claude will respond to a query directly—without any additional context. Specifically, we ask “What is the aggregate market value of the voting and non-voting stock held by non-affiliates of the Registrant, as of March 25, 2022?”
The following is Claude’s response:
Unfortunately, without access to the specific financial filings or reports for the company you are asking about, I do not have enough information to determine the aggregate market value of the voting and non-voting stock held by non-affiliates as of March 25, 2022.
Public companies are required to disclose this information in their annual reports and other SEC filings, but I do not have access to those documents for the particular company or "Registrant" you are referring to. The aggregate market value calculation takes into account things like the number of outstanding shares, recent stock prices, and which shareholders are considered affiliates versus non-affiliates.
Unless you are able to provide the company's name and the specific report containing this data point, I cannot lookup or calculate that aggregate market value figure. My role is to provide helpful information to you, but I do not have a way to access each public company's proprietary financial data directly. Please let me know if you can share more details about the company in question.
Claude indicates it does not have enough context, especially because the query didn’t explicitly indicate the registrant (the company).
Clean up
If you’ve been following along, don’t forget to delete the SageMaker endpoint and delete the OpenSearch Service domain when you’re done so you don’t incur unnecessary costs:
embedding_endpoint.delete_model()
embedding_endpoint.delete_endpoint()Conclusion
Embeddings are at the heart of a RAG system, and Voyage AI offers the best general-purpose and domain-specific embedding models today. Get started or level up your existing RAG stack on AWS today with Voyage AI embedding models—it’s seamless with SageMaker JumpStart. You can try the notebook in this post yourself. Learn more about Voyage AI and follow them on X (Twitter) or LinkedIn for updates!
About the Authors
 Tengyu Ma is CEO and Co-Founder of Voyage AI and an assistant professor of computer science at Stanford University. His research interests broadly include topics in machine learning, algorithms and their theory, such as deep learning, (deep) reinforcement learning, pre-training / foundation models, robustness, non-convex optimization, distributed optimization, and high-dimensional statistics. Tengyu earned his PhD from Princeton University and has worked at Facebook and Google as visiting scientists.
Tengyu Ma is CEO and Co-Founder of Voyage AI and an assistant professor of computer science at Stanford University. His research interests broadly include topics in machine learning, algorithms and their theory, such as deep learning, (deep) reinforcement learning, pre-training / foundation models, robustness, non-convex optimization, distributed optimization, and high-dimensional statistics. Tengyu earned his PhD from Princeton University and has worked at Facebook and Google as visiting scientists.
 Wen Phan is Head of Product at Voyage AI and has spent the last decade developing and commercializing AI and data products for enterprises. He has worked with hundreds of users and organizations around the world to apply AI and data to their use cases in financial services, healthcare, defense, and technology, to name a few. Wen holds a B.S. in electrical engineering and M.S. in analytics and decision sciences. Personally, he enjoys spinning hip-hop records, dining out, and spending time with his wife and two kids — oh, and guzzling cookies and cream milkshakes, too!
Wen Phan is Head of Product at Voyage AI and has spent the last decade developing and commercializing AI and data products for enterprises. He has worked with hundreds of users and organizations around the world to apply AI and data to their use cases in financial services, healthcare, defense, and technology, to name a few. Wen holds a B.S. in electrical engineering and M.S. in analytics and decision sciences. Personally, he enjoys spinning hip-hop records, dining out, and spending time with his wife and two kids — oh, and guzzling cookies and cream milkshakes, too!
 Vivek Gangasani is an AI/ML Solutions Architect working with Generative AI startups on AWS. He helps world leading AI startups train, host and operationalize LLMs to build innovative Generative AI solutions. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance at scale for LLMs. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
Vivek Gangasani is an AI/ML Solutions Architect working with Generative AI startups on AWS. He helps world leading AI startups train, host and operationalize LLMs to build innovative Generative AI solutions. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance at scale for LLMs. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
Source link
lol