This is a submission for the AssemblyAI Challenge : 1) Sophisticated Speech to Text, 2) Really Rad Real-Time. and 3) No more Monkey Business
What I Built
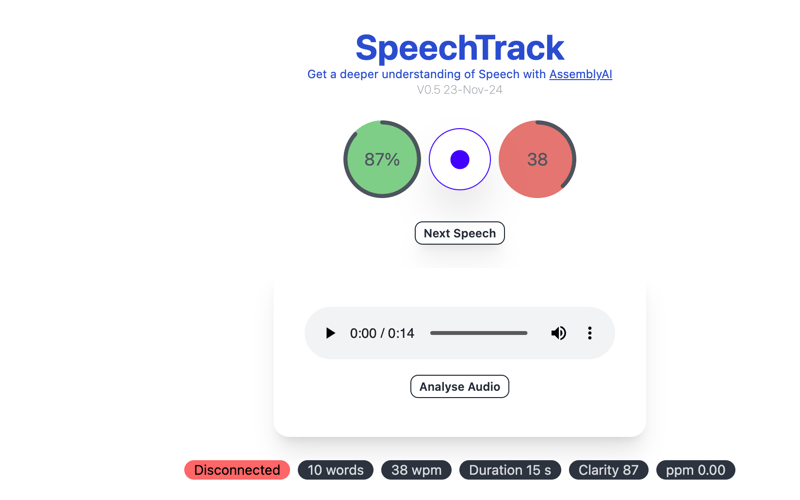
SpeechTrack
Getting a deeper understanding of speech with AssemblyAI
Ever wondered how your speech sounds to others? Clarity and speed are the heartbeat of effective communication, but striking the perfect balance can be a challenge.
Enter SpeechTrack, your real-time speech companion.
With intuitive visual indicators for Clarity and Tempo, SpeechTrack empowers you to refine your delivery through post speech Feedback.
Whether you’re preparing for a big presentation, a podcast, or an important conversation,
SpeechTrack helps you speak with confidence, precision, and impact.
Try it now and transform the way you communicate!
Technical Overview
- App – built using
REMIX.run&Reactweb frameworktailwind.cssanddaisyUIfor styling - App modules (at a high level)
- Microphone – to stream Audio
- Websocket module for receiving messages from AssemblyAI
- AudioProcessor – to combine streamed Audio chunks to a .wav File object
- Various React components to process & assemble received messages and maintain application state
- Backend for front to deal with:
- API keys and temporary tokens
- Uploading audio,
- Getting transcripts,
- asking LeMUR to do evaluation of Speech
- Finally present the Report in MARKDOWN format
- Maintain a history of last 3 Speeches in localStorage on client side
Demo
Here are some use cases:
1. Learning from good speakers.
A good speaker can keep the audience spell bound. What is it that they do well that we can replicate. This inspiring speech is from the movie Coach Carter.
Here is the Speech Evaluation Report from LeMUR
Analysis & Feedback
Here’s my analysis and feedback for the speech transcript in a human-readable Markdown format:
Speech Evaluation
Strengths
-
Effective Use of Pauses: With 8.75 pauses per minute (ppm), the speaker is within the ideal range of 5-10 ppm. This allows listeners to process key ideas and adds emphasis to important points.
-
Inspirational Content: The speech contains powerful, motivational messages about personal empowerment and positive influence on others.
-
Concise Delivery: At 104 words, the speech is relatively brief, which can help maintain audience attention and focus on core ideas.
Areas for Improvement
-
Speaking Speed: At 130 words per minute (wpm), the pace is slightly below the ideal range of 140-200 wpm. Increasing the speed slightly could make the delivery more engaging.
-
Filler Words: The use of “ah” was noted in the transcript. Reducing or eliminating filler words can enhance clarity and professionalism.
-
Structure: While the content is inspirational, a clearer structure with an introduction, main points, and conclusion could improve overall coherence.
Summary Feedback
The speaker delivers a powerful message with good use of pauses, allowing the audience to absorb the inspirational content. To enhance the speech:
- Increase speaking speed slightly to reach the ideal range of 140-200 wpm.
- Eliminate filler words like “ah” to maintain a smooth flow of ideas.
- Consider structuring the speech more clearly, perhaps by grouping ideas into distinct sections.
- The personal touch at the end (“Sir, I just want to say thank you. You saved my life.”) is impactful but seems abrupt. Consider a smoother transition or integration of this personal element.
By implementing these suggestions, the speaker can elevate an already powerful message to create an even more impactful and polished presentation.
{kind=link}
2. In-audio directives for Speech summary and sentiment Analysis.
The first line of audio is always checked for any directives (Summary, Sentiment Analysis) before speech->text transcript generation – see process details below.
In the following video hear the first line direct the app to prepare for summary and sentiment analysis.
Screenshot: Show’s Realtime transcript with directives to parameter object

The variours steps in the process Speech->Transript->Inference.
## All lines except those with leading ##'s are from server logs
## Detection of directive from first line
f(getComnand) from first FinalTranscript: I would like you to generate a catchy summary and sentiment analysis of the following story. {
summarization: true,
summary_model: 'catchy',
summary_type: 'gist',
sentiment_analysis: true
}
## The streamed audio packets are then combined with .wav header and
## file object for the wave file is uploaded
url : https://api.assemblyai.com/v2/upload
## we then have a URL to the uploaded audio
f(fileUpload) : Uploaded Successfully {
upload_url: 'https://cdn.assemblyai.com/upload/ebabc86a-0a1d-4988-a6f0-5dc06352921d'
}
f(fileUpload): 472.023ms
/api/upload fileUpload: 540.219ms
## NOTE: parameters for audioURL -> transcript
## disfluencies - so assemblyai can transcribing filler words
## Parameters below are computed for every speech and depend
## on first line - see below
## audio_start_from - ensure we don't include first line while asking
/api/upload getTranscriptFromURL: 6.628s
f(getTranscriptFromURL) {
audio: 'https://cdn.assemblyai.com/upload/ebabc86a-0a1d-4988-a6f0-5dc06352921d',
disfluencies: true,
summarization: true,
summary_model: 'catchy',
summary_type: 'gist',
sentiment_analysis: true,
audio_start_from: 10010
}
## Transcript id along with a CUSTOM PROMPT is submitted to leMUR for
## specfic speech evaluation response.
## CUSTOM PROMPT contains:
## 1. Description of the Task evaluation details,
## 2. Required outline of the evaluation report
## 3. Acceptable standards of a good speech
## 4. App generated metrics (duration, words per min, pauses, etc)
## 5. Report format as markdown
/api/feedback 1129a02c-4a28-49ea-8fbf-cb55f89a0214
f(askLeMUR): 9.234s
Screenshot: Show’s Transcription and Sentiment Analysis

CUSTOM PROMPT used with LeMUR
You are **SpeechEvaluator**, an expert in analyzing and
providing constructive feedback on speech delivery.
Your role is to assess the quality of a speaker's
performance based on key metrics and provide
actionable insights to help them improve.
You will be given structured data from a speech analysis,
including metrics like *Words per Minute (*wpm*)*,
*Pauses per Minute (*ppm*)*,
duration, and word count, along with a transcript.
**Your Task**:
1. **Analyze Metrics**:
Evaluate the speaker's delivery based on provided quantitative
data:
- *wpm*: Assess speaking speed (ideal range: 140–200 wpm).
- *ppm*: Evaluate pause usage (ideal range: 5–10 ppm).
- *duration*: Consider how metrics align with speech length.
- *wc*: Check for verbosity or brevity based on context.
2. **Assess Transcript**:
- Identify clarity issues, such as filler words, redundancy, or lack of focus.
- Highlight the effectiveness of pauses and transitions between topics.
- Comment on structure and coherence, ensuring ideas flow logically.
3. **Provide Feedback**:
- Highlight **strengths** (e.g., engaging delivery, appropriate speed).
- Suggest **areas for improvement**, including specific and actionable tips.
4. **Use Accessible Language**:
- Ensure your feedback is clear and easy for the speaker to understand,
even if they are new to public speaking or storytelling or presentations.
### **Example Output**:
#### **Strengths**
- *Good Speaking Speed*: wpm is within the recommended range, making the delivery engaging and energetic.
- *Use of Pauses*: Pauses are moderately frequent, allowing listeners time to process key ideas.
#### **Areas for Improvement**
- *Filler Words*: Repeated use of 'um', 'uh', 'like', 'you know', and 'I mean' distracts
from the main message. Replace these with deliberate pauses.
- *Structure and Clarity*: The speech lacks a clear structure and transitions,
making it harder to follow. Organize thoughts into sections for better flow.
#### **Summary Feedback**
The speaker demonstrates confidence and an engaging pace but should focus on
reducing filler words like 'uh', 'um', and structuring ideas more effectively.
With these adjustments, the speech will feel more polished and impactful.
Follow this format consistently to ensure feedback is constructive and actionable.
DO NOT APOLOGIZE FOR INFORMATION NOT AVAILABLE FOR ABOVE ANALYSIS"
Below is the metrics from this Speech in JSON format. Use it to evaluate the speech.
Journey
The Assembly AI Hackathon immediately caught my attention. Exploring their Playground gave me a basic understanding of their APIs, and soon I was diving deeper with httpie, testing almost all REST APIs. The Speech-to-Text Streaming API stood out as the most exciting, and I knew it would be the foundation of my project.
Building SpeechTrack
With the help of ChatGPT, I brainstormed ideas and finalized SpeechTrack, a tool to provide real-time feedback to speakers on:
- Clarity, measured through confidence scores.
- Tempo, tracked in words per minute.
The name was a nod to Assembly AI’s focus on unraveling speech, evolving from ChatGPT’s original suggestion of VoiceTrack.
Steps in the Journey
-
Exploring APIs: I familiarized myself with Assembly AI’s tools using
httpie. - Ideation: Brainstormed (w/LLMs) and refined the concept for SpeechTrack.
-
Implementation:
- Used the Streaming API for real-time speech insights.
- Faced challenges with audio streaming and creating WAV files. Resources like the Assembly AI Realtime Transcription Example and @3kb-dev’s WAV file guide were lifesavers.
<!– Please clearly note whether or not this submission should qualify for additional prompts, and if so, expand on how you implemented those additional tools. –>
-
Prompt Coverage.
In my opinion SpeechTrack qualifies for all 3 challenge prompts as it ended up using: - Streaming Speech-to-Text – to provide realtime cues (providing the audio and real-time transcript)
- Speech-to-Text – Transcribe Audio (with in-audio parameter detection)
- Speech Understanding (using transcript of (b) and LeMUR to provide analysis and feedback on Speech)
Reflections & Conclusion
Though the journey had its hurdles, completing SpeechTrack was immensely satisfying. Thanks to Assembly AI for their fantastic APIs, great support (thanks to Lee Vaughn of Support Engineering at Assembly AI) and the Dev community for their support. Here’s to more learning and creating in the future!
Source link
lol