23
May
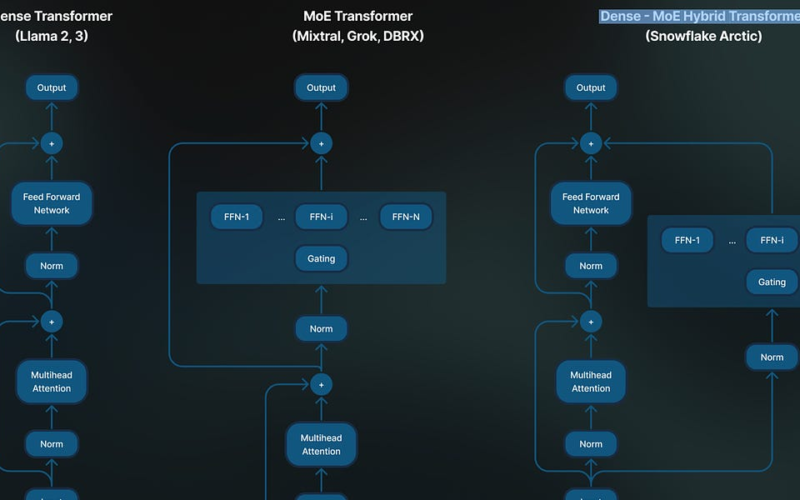
Mixture of Experts (MoE) architectures for large language models (LLMs) have recently gained popularity due to their ability to increase model capacity and computational efficiency compared to fully dense models. By utilizing sparse expert subnetworks that process different subsets of tokens, MoE models can effectively increase the number of parameters while requiring less computation per token during training and inference. This enables more cost-effective training of larger models within fixed compute budgets compared to dense architectures. Despite their computational benefits, training and fine-tuning large MoE models efficiently presents some challenges. MoE models can struggle with load balancing if the tokens…