23
Jul
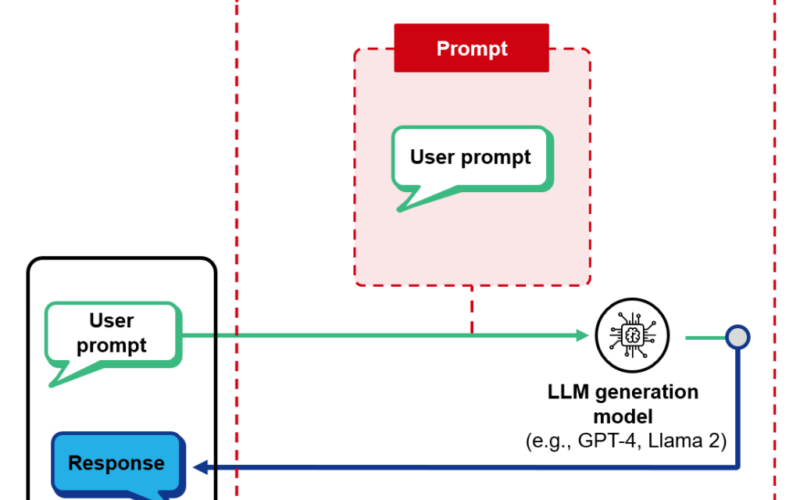
arXiv:2407.14790v1 Announce Type: new Abstract: Solving grid puzzles involves a significant amount of logical reasoning. Hence, it is a good domain to evaluate the reasoning capability of a model which can then guide us to improve the reasoning ability of models. However, most existing works evaluate only the final predicted answer of a puzzle, without delving into an in-depth analysis of the LLMs' reasoning chains (such as where they falter) or providing any finer metrics to evaluate them. Since LLMs may rely on simple heuristics or artifacts to predict the final answer, it is crucial to evaluate the generated reasoning…