As with any IT project, Machine Learning projects need a framework. However, classical methodologies do not apply or apply very poorly to Data Science. Among the existing methodologies, CRISP-DM is the most commonly used and will be presented here. Several variants exist.
Be careful, CRISP is a framework and not a rigid structure. The purpose of using a methodology is not to have a magic formula or to be limited. It mainly provides an idea of the progress and steps, as well as good practices to follow.
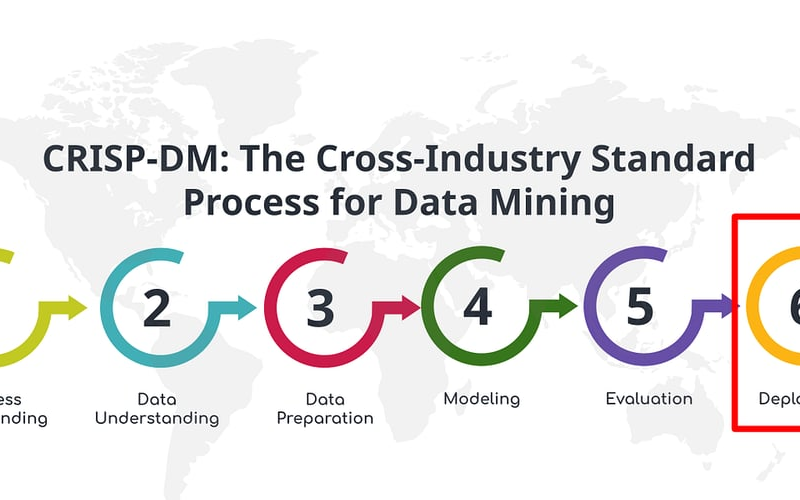
CRISP-DM stands for “Cross Industry Standard Process for Data Mining.” It is, therefore, a standard process that does not depend on the application domain. Originally, the methodology was created as part of a European project led by a consortium of companies.
The presence of Data Mining in its name (and not Machine Learning) indicates that this method is old. Indeed, its first version dates back to 1996. A second version was being drafted from 2006 but was abandoned in 2011 before its release.
This method is iterative. Five phases follow one another until the result is validated by the business, with possible back-and-forths between some.
These phases are as follows:
-
Business Understanding: this is the business understanding phase, which is not a technical phase.
-
Data Understanding: the data understanding phase corresponds mainly to a phase of descriptive statistics and allows for familiarization with the provided data.
-
Data Preparation: it is in this data preparation phase that format modifications or feature creations are carried out.
-
Modeling: this is the phase of creating models and optimizing parameters.
-
Evaluation: the evaluation is not conducted by Data Scientists in this phase. Business experts will assess whether the quality of the proposed solution meets the production constraints.
These five phases are then followed by a sixth phase that only occurs once: the Deployment phase. More than a deployment phase, it is actually a preparation phase for a more classic project: the production deployment of the model, which will become one among other components in the solution’s architecture.
The overall schema is as follows:
{kind=link}
1. Business Understanding
The business understanding phase comes first within the iterations. Its goal is to fully understand the business needs and project objectives.
This phase is divided into several steps, namely determining business objectives, assessing the situation, setting Machine Learning goals, and planning the project.
These steps are mostly carried out through meetings and workshops with business experts, by studying the processes on-site where Machine Learning will be implemented.
2. Data Understanding
The data understanding phase is the first technical phase. It involves loading the data and beginning to understand it.
There are three main steps leading to the completion of part of the deliverable:
-
The identity card of the dataset(s)
-
The description of the fields
-
The statistical analysis of each field
Before these three steps, the data must be retrieved and loaded into the software of choice, or access must be obtained if the data is directly in databases.
3. Data Preparation
In most cases, the data preparation phase is lengthy (up to 50% of the project time). The goal is to transform raw data into usable data for the modeling phase.
4. Modeling
The modeling phase involves creating various models, comparing them, and choosing the model(s) to present to the business.
For each model tested, it is important to track all the decisions made. This requires successively:
-
Indicating how the model will be tested and the metrics chosen for evaluation.
-
Specifying the chosen technique and briefly describing it.
Indicating the constraints of the chosen model (which may lead to a return to the data preparation phase if necessary). -
Specifying the parameters used (and those tested in the case of hyperparameter optimization).
-
Calculating the model metrics (in the vast majority of cases, multiple metrics are needed) and, if possible, an analysis of the model.
-
Indicating whether the model is acceptable for the next phase or if it is insufficient.
This phase represents the largest part of this book and is detailed in the chapters dedicated to the different techniques (from the Modeling and Evaluation chapter to the Unsupervised Algorithms chapter).
5. Evaluation
Contrary to what its name might suggest, the evaluation phase is not a phase for calculating metrics (which should be done in the Modeling phase) but rather a business evaluation phase.
Indeed, the results are compared against the needs identified in the Business Understanding phase. The aim is to determine whether the best models obtained are practically usable, often through tests on real data.
If a model is validated, it must then be reviewed to ensure that the assumptions made throughout the process are valid and correspond to reality. If no issues are detected, deployment can proceed.
In all other cases, it is necessary to determine the course of action to restart a complete iteration and achieve a result that can be validated, or decide to stop the project. Depending on the results obtained, several avenues can be explored:
-
Add more data, for example through new extractions or by adding attributes.
-
Test other models.
-
Change the desired task by breaking it down into several subtasks.
-
Put the project on hold until algorithms improve if the current state-of-the-art is insufficient or until new data becomes available.
6. Deployment
The deployment phase is not a technical phase.
The deployment itself will be a different project, managed according to the technical team’s usual practices. However, in this phase, it is necessary to prepare the model’s production deployment and, most importantly, its future lifecycle:
-
What is the expected schedule for delivering the model?
-
In what form will it be provided to the technical team?
-
How will monitoring be conducted?
-
In case of failure or deviations, how will the model be retrained and at what frequency?
-
What is the model maintenance procedure (in case of issues, for example)?
-
What are the risks and mitigations?
Source link
lol