Due to the extensive length of the regular Ahead of AI #11: New Foundation Models article, I removed some interesting tidbits around the Llama 2 weights from the main newsletter. However, it might be nice to include those as a small bonus for the supporters of Ahead of AI. Thanks again for the kind support!
In this short(er) article, we will briefly examine the Llama 2 weights and the implications of hosting them using different floating point precisions.
The original Llama 2 weights are hosted by Meta but the Hugging Face (HF) model hub also hosts the Llama 2 weights for added convenience. Using one over the other should be a matter of convenience. However, There was something peculiar about the HF weights, which were stored in float16 precision, whereas the original weights were stored in bfloat16 precision. Both bfloat16 and float16 are low-precision formats that reduce the compute memory requirements by half compared to regular 32-bit precision models, which are typically used when training deep neural networks on GPUs. A lower precision format accelerates the training time substantially, too!
Before explaining the implications of this format change, let’s start with a bit (no pun intended) more background information on the different precision formats.
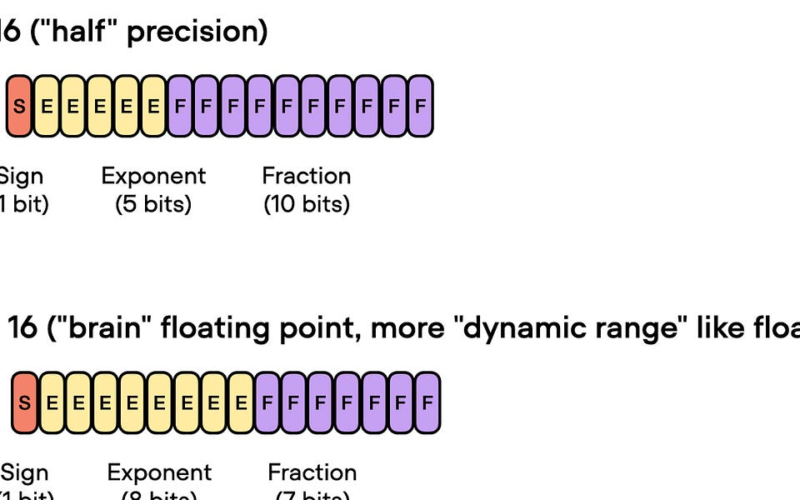
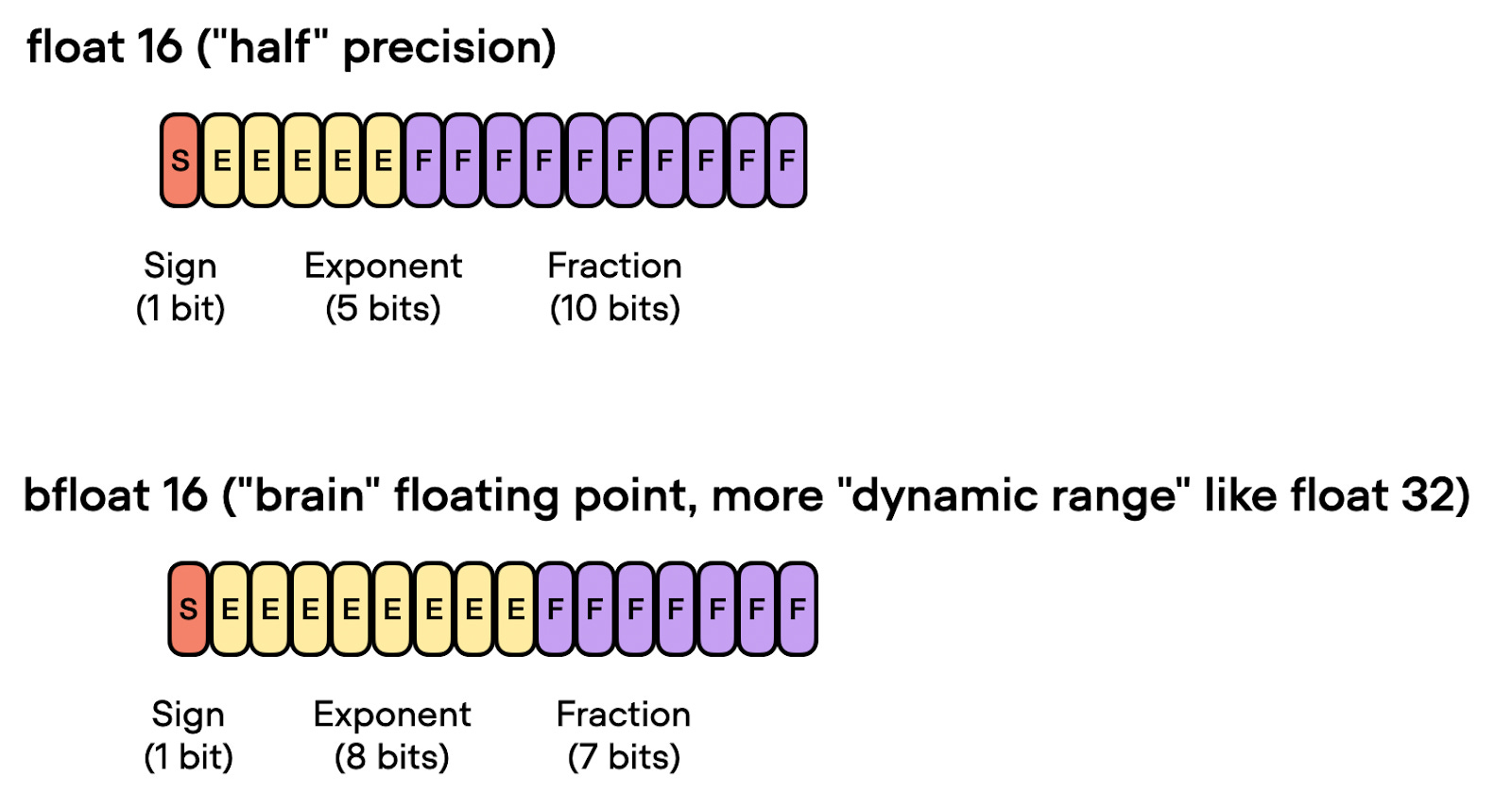
16-bit precision for floating-point computation is often referred to as “half” precision since, as the name implies, it has half the precision compared to 32-bit formats that are the standard float format (for training deep neural networks on GPUs.)
The figure below shows that float16 uses three fewer bits for the exponent and 13 fewer bits for the fractional value
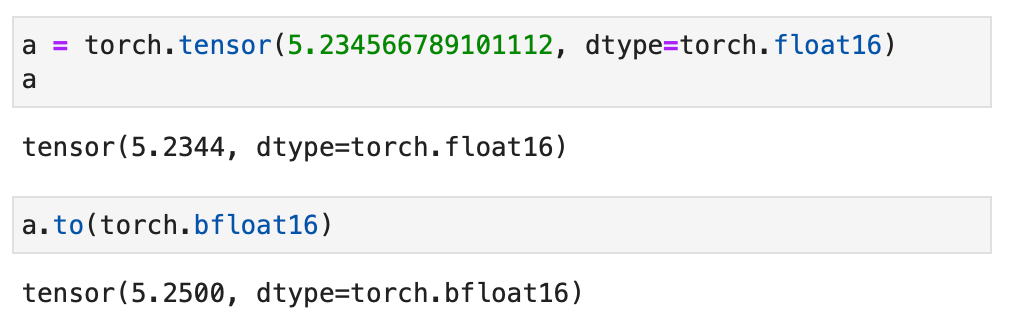
But before discussing the difference to bfloat16, let’s make the difference between 32-bit and 16-bit-precision levels more intuitive and tangible. Consider the following code example in PyTorch:
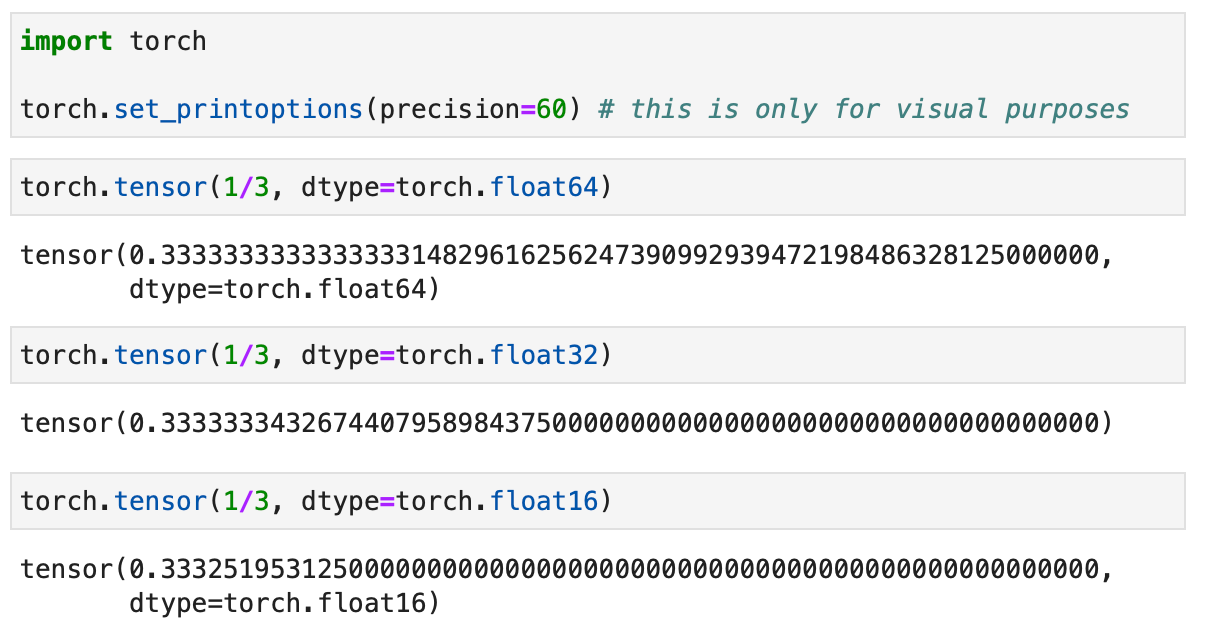
The code examples above show that the lower the precision, the fewer accurate digits we see after the decimal point.
Deep learning models are generally robust to lower precision arithmetic. In most cases, the slight decrease in precision from using 32-bit floats instead of 64-bit floats does not significantly impact the model’s predictive performance, making the trade-off worthwhile. However, things can become tricky when we go down to 16-bit precision. You may notice that the loss may become unstable or not converge due to imprecision, numeric overflow, or underflow.
Overflow and underflow refer to the issue that certain numbers exceed the range that can be handled by the precision format, for example, as demonstrated below:

By the way, while the code snippets above showed some hands-on examples regarding the different precision types, you can also directly access the numerical properties via torch.finfo as shown below:
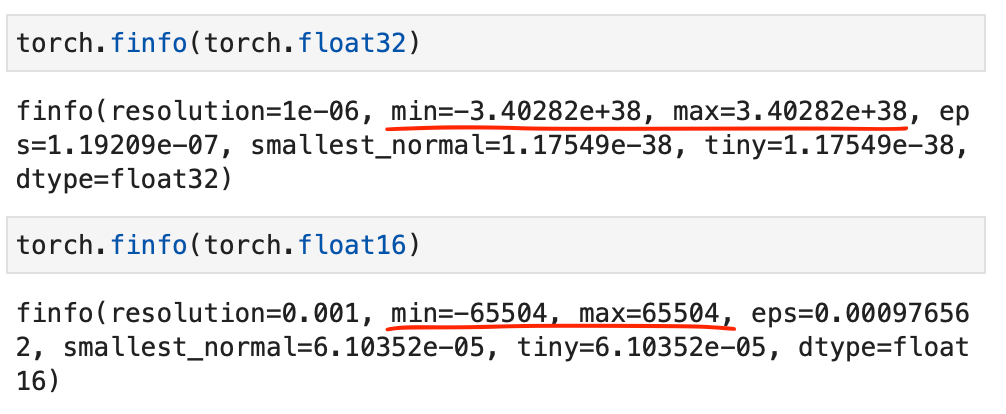
The code above reveals that the largest float32 number is 340,282,000,000,000,000,000,000,000,000,000,000,000 (via max); float16 numbers cannot exceed the value 65,504 for example.
340,282,000,000,000,000,000,000,000,000,000,000,000 (via max); float16 numbers cannot exceed the value 65,504 for example.
Another floating-point format has recently gained popularity, Brain Floating Point (bfloat16). Google developed this format for machine learning and deep learning applications, particularly in their Tensor Processing Units (TPUs). Bfloat16 extends the dynamic range compared to the conventional float16 format at the expense of decreased precision.
Now bfloat16, or “brain float 16” is a 16-bit floating point version that has a higher dynamic range than float 16 and can thus support larger numbers by trading off more numbers after the decimal point, as I summarized in the figure below:
The extended dynamic range helps bfloat16 to represent very large and very small numbers, making it more suitable for deep learning applications where a wide range of values might be encountered. However, the lower precision may affect the accuracy of certain calculations or lead to rounding errors in some cases. But in most deep learning applications, this reduced precision has minimal impact on modeling performance.
While bfloat16 was originally developed for TPUs, this format is now supported by several NVIDIA GPUs as well, beginning with the A100 Tensor Core GPUs, which are part of the NVIDIA Ampere architecture.
We can check whether your GPU supports bfloat16 via the following code:
>>> torch.cuda.is_bf16_supported()
True
And we can double check that bfloat16 can indeed show the practically same range of numbers as float32 by looking at the torch.finfo side by side:

Why did HF change the precision from bfloat16 to float16 when hosting the model on their hub? This is likely because only TPUs and Nvidia cards with an Ampere or newer support bfloat16. So, by adopting a float16 format, users with older GPUs should be able to use the model weights, too.
However, the change may have practical implications. As we’ve seen above, bfloat16 supports a wider dynamic range than float16. Now, this means that if the model weights contain values larger than 65504 or smaller than -65504, these values will become either inf or -inf:

I guess that HF would have clipped the values before the conversion to avoid these issues. Furthermore, Radek Osmulski, following our discussion on social media, double-checked the weights and found that the original Llama 2 weights of the 7B model provided by Meta do not contain numbers that stray much from 0.
I double checked with 70B model and found that this is also not the case for the 70B model:

We can see that converting the smallest and largest numbers to bfloat16 should indeed not cause any issues due to clipping or rounding:

Another reason could be that HF recommends the float16 weights for numerical stability reasons when finetuning the model. If a network is not optimally normalized, activations, gradients, or weights may exceed the number ranges supported by bfloat16.
Converting weights from float16 to bfloat16 should not cause any issues in terms of clipping large or small numbers since bfloat16 has a larger dynamic range than float16, as we have discussed above. However, since float16 supports fewer numbers after the decimal point, a float16 to bfloat16 conversion can lead to a difference due to rounding:
Now, converting the formats the other way, that is, changing bfloat16 to float16 as HF did, should not cause any issues unless the original weights contain very small or huge numbers.
However, based on Radek’s analysis of the 7B model and my analysis of the 70B model mentioned above, there is no indicator that the model contained large weight values that could have been affected by this. So, for now, there does not seem to be an issue with the weights hosted on HF. (Although, some people noted difficulties with training the 7B model: “[…] the 7b weights are so broken and basically impossible to train in float16.“)
Apparently, HF already updated the Llama 2 weights on the model hub, as Radek reported today, changing the weights back to the original bfloat16 format.
Apparently, the weights are not cast to `fp16` anymore on loading!
But the config still says `fp16` for the default `torch_dtype`.
But that might not be that bad — probably doing `torch_dtype=torch.bfloat16` in `from_pretrained` would preserve the bf16 weights!
Now the interesting bit is that the weights in the HF repo haven’t been changed yet.
…
But if indeed going from bf16 to fp16 breaks the weights in any way, that would be surprising and no one would be to blame.
…
There is essentially no performance difference for the base Llama 2 7b model, regardless of whether the original bf16 weights are used, or the ones converted from fp16 -> bf16.
In any case, it remains interesting. I will update this article in case I find out anything peculiar or hear an update on this.
For now, nothing to worry about! Enjoy the rest of the weekend!
This magazine is personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.
Your support means a great deal! Thank you!
Source link
lol