I frequently reference a process called Reinforcement Learning with Human Feedback (RLHF) when discussing LLMs, whether in the research news or tutorials. RLHF is an integral part of the modern LLM training pipeline due to its ability to incorporate human preferences into the optimization landscape, which can improve the model’s helpfulness and safety.
In this article, I will break down RLHF in a step-by-step manner to provide a reference for understanding its central idea and importance. Following up on the previous Ahead of AI article that featured Llama 2, this article will also include a comparison between ChatGPT’s and Llama 2’s way of doing RLHF.
Finally, for those wondering about the relevance or necessity of RLHF, I also added a section highlighting the most recent alternatives — I intend to update this section regularly.
In short, the table of contents of this article is as follows:
Modern transformer-based LLMs, such as ChatGPT or Llama 2, undergo a 3-step training procedure:
-
Pretraining
-
Supervised finetuning
-
Alignment
Initially, in the pretraining phase, the models absorb knowledge from enormous unlabeled text datasets. The subsequent supervised finetuning refines these models to better adhere to specific instructions. Lastly, the alignment stage hones the LLMs to respond more helpfully and safely to user prompts.
Note that this training pipeline is based on OpenAI’s InstructGPT paper, which details the process for GPT-3. This process is widely considered to be the approach behind ChatGPT. Later, we will also compare this method with Meta AI’s latest Llama 2 model.
Let’s begin with the initial step, pretraining, as depicted below.
Pretraining typically occurs on a vast text corpus comprising billions to trillions of tokens. In this context, we employ a straightforward next-word prediction task in which the model predicts the subsequent word (or token) from a provided text.
If you’re unfamiliar with this next-word prediction task, you might like my earlier article Understanding Encoder And Decoder LLMs:

One point worth emphasizing is that this type of pretraining allows us to leverage large, unlabeled datasets. As long as we can use the data without infringing on copyrights or disregarding creator preferences, we can access large datasets without the need for manual labeling. In fact, in this pretraining step, the “label” is the subsequent word in the text, which is already part of the dataset itself (hence, this pretraining approach is often called self-supervised learning).
The next step is supervised finetuning, which is summarized in the figure below.

The supervised finetuning stage involves another round of next-token prediction. However, unlike the preceding pretraining stage, we now work with instruction-output pairs, as depicted in the figure above. In this context, the instruction is the input given to the model (it is sometimes accompanied by an optional input text, depending on the task). The output represents a desired response similar to what we expect the model to produce.
To provide a concrete example, let’s consider the following instruction-output pair:
The model takes the instruction text (“Write a limerick about a pelican”) as input and carries out next-token prediction for the output text (“There once was a pelican so fine…”).
While both employ a similar next-token training objective, supervised finetuning typically uses much smaller datasets than pretraining. This is because it requires instruction-output pairs rather than just raw text. To compile such a dataset, a human (or another high-quality LLM) must write the desired output given a specific instruction — creating such a dataset is a lot of work.
Following this supervised finetuning stage, there’s another finetuning phase commonly regarded as the “alignment” step, as its primary objective is to align the LLM with human preferences. This is where RLHF comes into play.
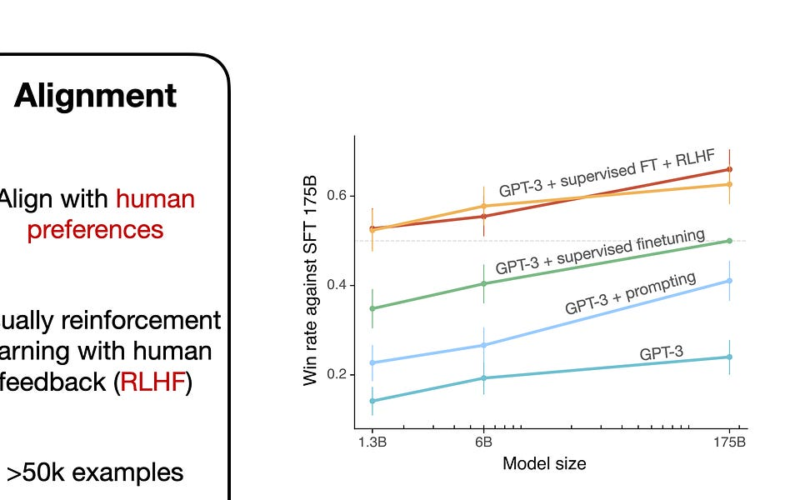
In the upcoming section, we will dive into the RLHF-based alignment step. However, for those curious about how it compares to the pretrained base model and the model from supervised finetuning in step 2, I included a chart (above) from the InstructGPT paper, which is the paper that popularized this procedure.
The chart above compares a 175B GPT-3 model after supervised finetuning (faint dotted line) with the other method. We can see the base GPT-3 model at the bottom of this chart.
If we consider a prompting approach where we query it multiple times and select the best response each time (“GPT-3 + prompting”), we can see a somewhat improved performance over the base model (“GPT-3”), which is to be expected.
Adding supervised finetuning to the GPT-3 base model makes the performance (“GPT-3 + supervised finetuning”) even better than “GPT-3 + prompting”.
The best performance, however, can be obtained from the GPT-3 model after supervised finetuning and RLHF (“GPT-3 + supervised finetuning + RLHF”) — the two graphs at the top of the chart. (Note that there are two lines at the top of this chart since the researchers experimented with two different sampling procedures.)
The next section will describe this RLHF step in more detail.
The previous section discussed the 3-step training procedure behind modern LLMs like ChatGPT and Llama-2-chat. In this section, we will look at the finetuning stages in more detail, focusing on the RLHF part.
The RLHF pipeline takes a pretrained model and finetunes it in a supervised fashion (step 2 in the previous section) and further aligns it with proximal policy optimization (step 3 in the previous section).
For simplicity, we will look at the RLHF pipeline in three separate steps:
-
RLHF Step 1: Supervised finetuning of the pretrained model
-
RLHF Step 2: Creating a reward model
-
RLHF Step 3: Finetuning via proximal policy optimization
RLHF Step 1, shown below, is a supervised finetuning step to create the base model for further RLHF finetuning.
In RLHF step 1, we create or sample prompts (from a database, for example) and ask humans to write good-quality responses. We then use this dataset to finetune the pretrained base model in a supervised fashion.
Note that this RLHF Step 1 is similar to step 2 in the previous section, “The Canonical LLM Training Pipeline”. I am listing it here again because it’s integral to RLHF.
In RLHF Step 2, we then use this model from supervised finetuning to create a reward model, as shown below.
As depicted in the figure above, for each prompt, we generate four to nine responses from the finetuned LLM created in the prior step. An individual then ranks these responses based on their preference. Although this ranking process is time-consuming, it might be somewhat less labor-intensive than creating the dataset for supervised finetuning. This is because ranking responses is likely simpler than writing them.
Upon compiling a dataset with these rankings, we can design a reward model that outputs a reward score for the optimization subsequent stage in RLHF Step 3. This reward model generally originates from the LLM created in the prior supervised finetuning step. Let’s refer to te reward model as RM and the LLM from the supervised finetuning step as SFT. To turn the model from RLHF Step 1 into a reward model, its output layer (the next-token classification layer) is substituted with a regression layer, which features a single output node.
If you are interested, here is a short video lecture on changing a classification model to a regression model in Unit 4.5 of my Deep Learning Fundamentals course.
The third step in the RLHF pipeline is to use the reward (RM) model to finetune the previous model from supervised finetuning (SFT), which is illustrated in the figure below.
In RLHF Step 3, the final stage, we are now updating the SFT model using proximal policy optimization (PPO) based on the reward scores from the reward model we created in RLHF Step 2.
More details about PPO are out of the scope of this article, but interested readers can find the mathematical details in these four papers that predate the InstructGPT paper:
(1) Asynchronous Methods for Deep Reinforcement Learning (2016) by Mnih, Badia, Mirza, Graves, Lillicrap, Harley, Silver, and Kavukcuoglu introduces policy gradient methods as an alternative to Q-learning in deep learning-based RL.
(2) Proximal Policy Optimization Algorithms (2017) by Schulman, Wolski, Dhariwal, Radford, and Klimov presents a modified proximal policy-based reinforcement learning procedure that is more data-efficient and scalable than the vanilla policy optimization algorithm above.
(3) Fine-Tuning Language Models from Human Preferences (2020) by Ziegler, Stiennon, Wu, Brown, Radford, Amodei, Christiano, Irving illustrates the concept of PPO and reward learning to pretrained language models including KL regularization to prevent the policy from diverging too far from natural language.
(4) Learning to Summarize from Human Feedback (2020) by Stiennon, Ouyang, Wu, Ziegler, Lowe, Voss, Radford, Amodei, Christiano introduces the popular RLHF three-step procedure that was later also used in the InstructGPT paper.
In the previous section, we looked at the RLHF procedure described in OpenAI’s InstructGPT paper. This method is commonly referenced as the one employed to develop ChatGPT. But how does it stack up against Meta AI’s recent Llama 2 model?
Meta AI utilized RLHF in creating the Llama-2-chat models as well. Nevertheless, there are several distinctions between the two approaches, which I’ve highlighted in the annotated figure below.
In summary, Llama-2-chat follows the same supervised finetuning step on instruction data as InstructGPT in RLHF Step 1. Yet, during RLHF Step 2, two reward models are created instead of just one. Furthermore, the Llama-2-chat model evolves through multiple stages, with reward models being updated based on the emerging errors from the Llama-2-chat model. There’s also an added rejection sampling step.
Margin Loss
Another distinction not depicted in the above-mentioned annotated figure relates to how model responses are ranked to generate the reward model. In the standard InstructGPT approach for RLHF PPO discussed previously, the researchers collect responses that rank 4-9 outputs from which the researchers create “k choose 2” comparisons.
For example, if a human labeler ranks four responses (A-D), such as A < C < D < B, this yields “4 choose 2” = 6 comparisons:
-
A < C
-
A < D
-
A < B
-
C < D
-
C < B
-
D < B
Similarly, Llama 2’s dataset is based on binary comparisons of responses, like A < B. However, it appears that each human labeler was only presented 2 responses (as opposed to 4-9 responses) per labeling round.
Moreover, what’s new is that alongside each binary rank, a “margin” label (ranging from “significantly better” to “negligibly better”) is gathered, which can optionally be used in the binary ranking loss via an additional margin parameter to calculate the gap between the two responses.
While InstructGPT used the following cross entropy-based ranking loss to train the reward model:
(mathcal{L}_{text {ranking }}=-log left(sigmaleft(r_thetaleft(x, y_cright)-r_thetaleft(x, y_rright)right)right))
Llama 2 added the the margin “m(r)” as a discrete function of the preference rating as follows:
(mathcal{L}_{text {ranking }}=-log left(sigmaleft(r_thetaleft(x, y_cright)-r_thetaleft(x, y_rright)-m(r)right)right))
where
-
r_θ(x,y) is the scalar score output for prompt x and the generated response y;
-
θ are the model weights;
-
σ is the logistic sigmoid function that converts the layer outputs to scores ranging from 0 to 1;
-
y_c is the preferred response chosen by the human annotators;
-
y_r is the rejected response chosen by the human annotators.
For instance, returning a higher margin via “m(r)” will make the difference between the reward of the preferred and rejected responses smaller, resulting in a larger loss, which in turn results in larger gradients, and consequently model changes, during the policy gradient update.
Two reward models
As mentioned earlier, there are two reward models in Llama 2 instead of one. One reward model is based on helpfulness, and the other is based on safety. The final reward function that is then used for the model optimization is a linear combination of the two scores.
Rejection sampling
Moreover, the authors of Llama 2 employ a training pipeline that iteratively produces multiple RLHF models (from RLHF-V1 to RLHF-V5). Instead of solely relying on the RLHF with PPO method we discussed earlier, they employ two algorithms for RLHF finetuning: PPO and rejection sampling.
In rejection sampling, K outputs are drawn, and the one with the highest reward is chosen for the gradient update during the optimization step, as illustrated below.
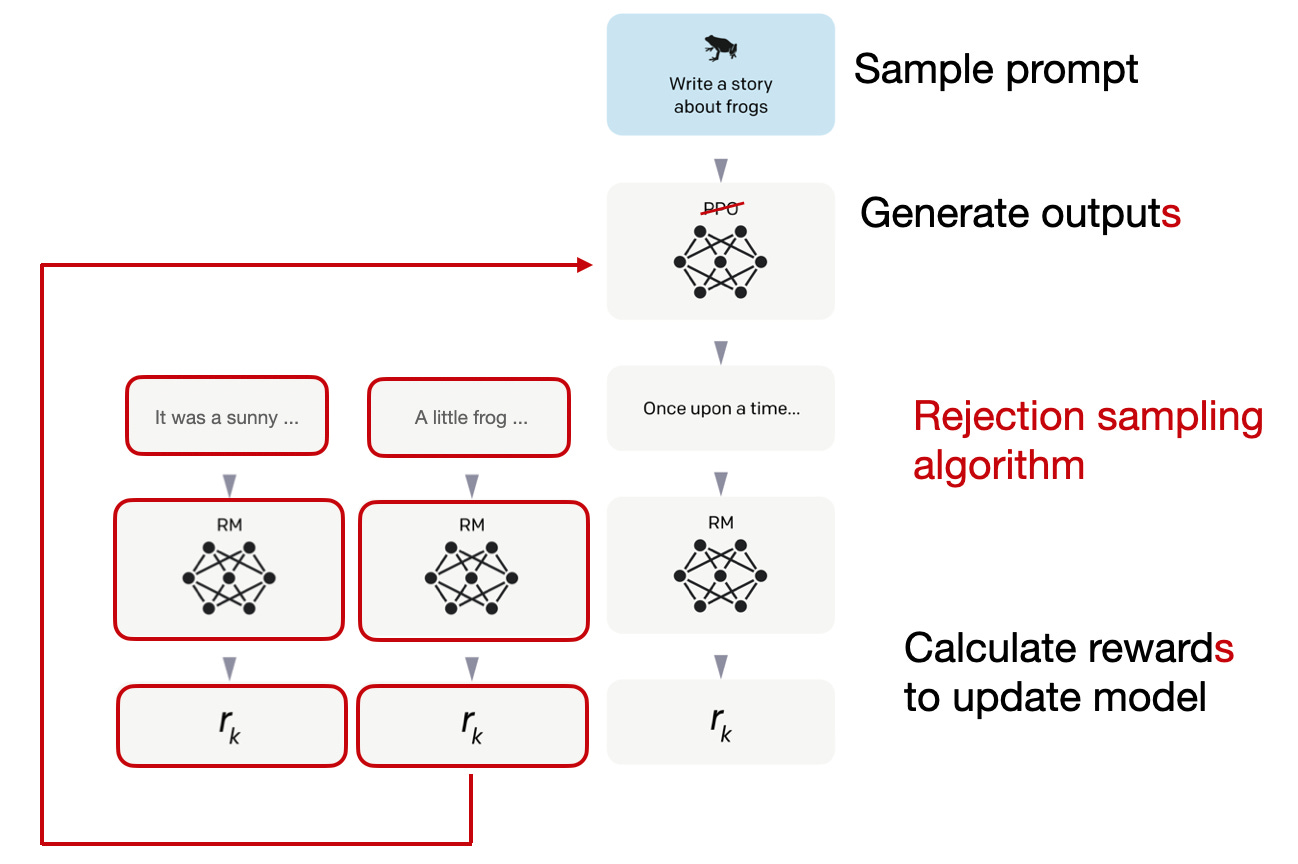
Rejection sampling serves to select samples that has a high reward score in each iteration. As a result, the model undergoes finetuning with samples of a higher reward compared to PPO, which updates based on a single sample each time.
After the initial phases of supervised finetuning, models are exclusively trained using rejection sampling, before later combining both rejection sampling and PPO.
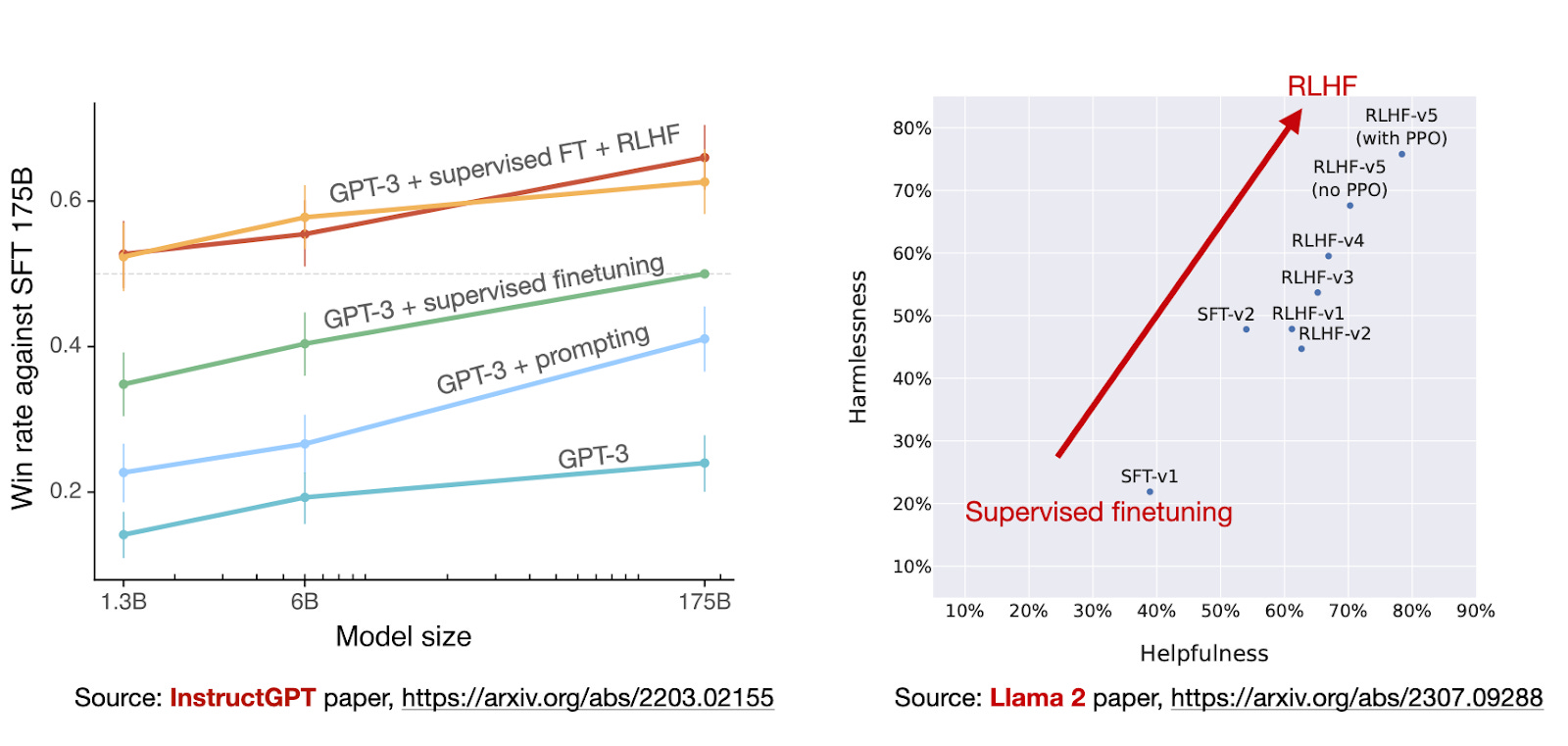
The researchers plotted the model performance over the RLHF stages, which shows that the RLHF-finetuned models improve on both the harmlessness and helpfulness axes.
Note that the researchers used PPO in the final step, following up on the previous models updated via rejection sampling. As the “RLHF-v5 (with PPO)” and “RLHF-v5 (no PPO)” comparison in the chart above shows, a model trained with PPO in the final stage is better than a model trained with just rejection sampling. (Personally, I’d be curious to see how it compares to a model finetuned with just PPO and no rejection sampling.)
Now that we have discussed and defined the RLHF process, a pretty elaborate procedure, one might wonder whether it’s even worth the trouble. The previous graphs from the InstructGPT and Llama 2 papers (shown again below) provide evidence that RLHF is worth the trouble.
However, a lot of ongoing research focuses on developing more efficient alternatives. The most interesting approaches are summarized below.
(1) Constitutional AI: Harmlessness from AI Feedback (Dec 2022, https://arxiv.org/abs/2212.08073)
In this Constitutional AI paper, researchers propose a self-training mechanism based on a list of rules humans provide. Similar to the InstructGPT paper mentioned earlier, the proposed method uses a reinforcement learning approach
The term “red teaming” that the researchers use in the figure above refers to a testing approach that has its roots in Cold War military exercises, where the term originally referred to a group playing the role of the Soviet Union to test US strategies and defenses.
In the context of cybersecurity of AI research, the term “red teaming” is now used to describe a process where external or internal experts emulate potential adversaries to challenge, test, and ultimately improve the given systems of interest by mimicking the tactics, techniques, and procedures of real-world attackers.
(2) The Wisdom of Hindsight Makes Language Models Better Instruction Followers (Feb 2023, https://arxiv.org/abs/2302.05206)
The Wisdom of Hindsight makes Language Models Better Instruction Followers shows that supervised approaches to LLM finetuning can indeed work well. Here, researchers propose a relabeling-based supervised approach for finetuning that outperforms RLHF on 12 BigBench tasks.
How does the proposed HIR (Hindsight Instruction Labeling) work? In a nutshell, the method HIR consists of two steps, sampling and training. In the sampling step, prompts and instructions are fed to the LLM to collect the responses. Based on an alignment score, the instruction is relabeled where appropriate in the training phase. Then, the relabeled instructions and the original prompts are used to finetune the LLM. Using this relabeling approach, the researchers effectively turn failure cases (cases where the LLM creates outputs that don’t match the original instructions) into useful training data for supervised learning.
Note that this study is not directly comparable to the RLHF work in InstructGPT, for example, since it seems to be using heuristics (“However, as most human-feedback data is hard to collect, we adopt a scripted feedback function …”). The results of the HIR hindsight approach are still very compelling, though.
(3) Direct Preference Optimization: Your Language Model is Secretly a Reward Model (https://arxiv.org/abs/2305.18290, May 2023)
Direct Preference Optimization (DPO) is an alternative to RLHF with PPO where the researchers show that the cross entropy loss for fitting the reward model in RLHF can be used directly to finetune the LLM. According to their benchmarks, it’s more efficient to use DPO and often also preferred over RLHF/PPO in terms of response quality.
(4) Contrastive Preference Learning: Learning from Human Feedback without RL (Oct 2023, https://arxiv.org/abs/2310.13639)
Like Direct Preference Optimization (DPO), Contrastive Preference Learning (CPL) is an approach to simplify RLHF by eliminating the reward model learning. Like DPO, CPL uses a supervised learning objective, specifically, a contrastive loss. (In the paper’s appendix, the authors show that DPO is a special case of CPL.) While the experiments were based on a robotics environment, CPL could also be applied to LLM finetuning.
(5) Reinforced Self-Training (ReST) for Language Modeling (Aug 2023, https://arxiv.org/abs/2308.08998)
ReST is an alternative to reinforcement learning with human feedback (RLHF) that aligns LLMs with human preferences. ReST uses a sampling approach to create an improved dataset, iteratively training on increasingly higher-quality subsets to refine its reward function. According to the authors, ReST achieves greater efficiency compared to standard online RLHF methods (like RLHF with proximal policy optimization, PPO) by generating its training dataset offline, but a comprehensive comparison to standard RLHF PPO methods as used in InstructGPT or Llama 2 is missing
(6) RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback (Sep 2023, https://arxiv.org/abs/2309.00267)
The recent reinforcement learning with AI feedback (RLAIF) study shows that the ratings for the reward model training in RLHF don’t necessarily have to be provided by humans but can be generated by an LLM (here: PaLM 2). Human evaluators prefer the RLAIF model half of the time over traditional RLHF models, which means that they actually don’t prefer one model over the other.
An additional interesting side note is that both RLHF and RLAIF strongly outperformed models that are purely trained via supervised instruction finetuning.
The outcome of this study is very useful and interesting since it basically means that we might be able to make RLHF-based training more efficient and accessible. However, it remains to be seen how these RLAIF models perform in qualitative studies that focus on safety and truthfulness of the information content, which is only partially captured by human preferences studies.
Whether these alternatives will be worthwhile in practice remains to be seen as there is currently no true competitor to Llama 2 and Code Llama-scale models that have been trained without RLHF.
Also, if you have tried any of these methods or stumbled upon additional promising approaches, I’d love to hear!
This magazine is personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.
Your support means a great deal! Thank you!
Source link
lol