Capital markets operation teams face numerous challenges throughout the post-trade lifecycle, including delays in trade settlements, booking errors, and inaccurate regulatory reporting. For derivative trades, it’s even more challenging. The timely settlement of derivative trades is an onerous task. This is because trades involve different counterparties and there is a high degree of variation among documents containing commercial terms (such as trade date, value date, and counterparties). We commonly see the application of screen scrapping solutions with OCR in capital market organizations. These applications come with the drawback of being inflexible and high-maintenance.
Artificial intelligence and machine learning (AI/ML) technologies can assist capital market organizations overcome these challenges. Intelligent document processing (IDP) applies AI/ML techniques to automate data extraction from documents. Using IDP can reduce or eliminate the requirement for time-consuming human reviews. IDP has the power to transform the way capital market back-office operations work. It has the potential to boost employee efficiency, enhance cash flow by speeding up trade settlements, and minimize operational and regulatory risks.
In this post, we show how you can automate and intelligently process derivative confirms at scale using AWS AI services. The solution combines Amazon Textract, a fully managed ML service to effortlessly extract text, handwriting, and data from scanned documents, and AWS Serverless technologies, a suite of fully managed event-driven services for running code, managing data, and integrating applications, all without managing servers.
Solution overview
The lifecycle of a derivative trade involves multiple phases, from trade research to execution, to clearing and settlement. The solution showcased in this post focuses on the trade clearing and settlement phase of the derivative trade lifecycle. During this phase, counterparties to the trade and their agents determine and verify the exact commercial terms of the transaction and prepare for settlement.
The following figure shows a sample derivative confirms the document.
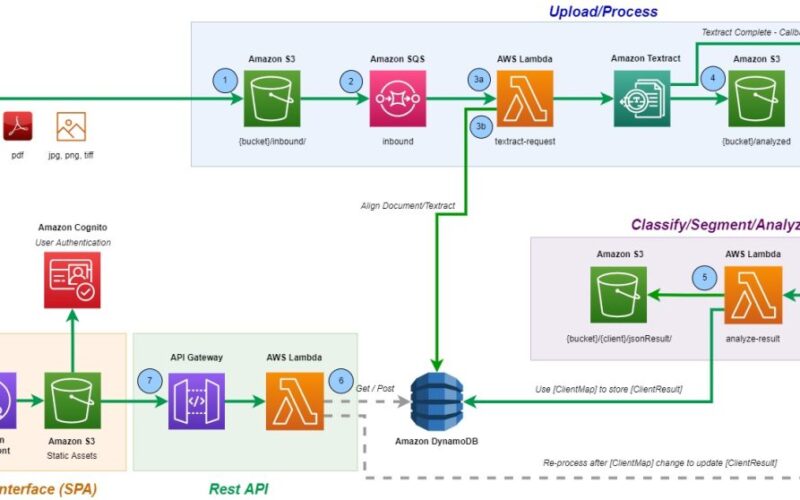
We built the solution using the event-driven principles as depicted in the following diagram. The derivative confirmation documents received from customers are stored in Amazon Simple Storage Service (Amazon S3). An event notification on S3 object upload completion places a message in an Amazon Simple Queue Service (Amazon SQS) queue to invoke an AWS Lambda function. The function invokes the Amazon Textract API and performs a fuzzy match using the document schema mappings stored in Amazon DynamoDB. A web-based human-in-the-loop UI is built for reviewing the document processing pipeline and updating schemas to train services for new formats. The web UI uses Amazon Cognito for authentication and access control.

The process flow includes the following steps:
- The user or business application uploads an image or PDF to the designated S3 bucket.
- An event notification on S3 object upload completion places a message in an SQS queue.
- An event on message receipt invokes a Lambda function that in turn invokes the Amazon Textract
StartDocumentAnalysisAPI for information extraction.- This call starts an asynchronous analysis of the document for detecting items within the document such as key-value pairs, tables, and forms.
- The call also returns the ID of the asynchronous job, and saves the job ID and Amazon S3 document key to a DynamoDB table.
- Upon job completion, Amazon Textract sends a message to an Amazon Simple Notification Service (Amazon SNS) topic and places the resultant JSON in the designated S3 bucket for classification analysis.
- A Lambda function receives the Amazon SQS payload and performs fuzzy match using Sorenson-Dice analysis between the Amazon Textract JSON results and DynamoDB document configuration mappings. The Sorenson-Dice analysis step compares the two texts and computes a number between 0–1, where the former indicates no match at all and the latter an exact match.
- Upon analysis completion, a Lambda function writes a merged and cleansed JSON result to the original S3 bucket and inserts the analysis results back into the DynamoDB table.
- Amazon API Gateway endpoints facilitate the interaction with the web-based UI.
- The human-in-the-loop UI application provides a human-in-the-loop function to analyze the document processing pipeline and intervene as needed to update the document configuration mappings.
A human-in the-loop process was applied to visually compare the reconciled results with their locations in the input documents. End-users can verify the accuracy of the results and either accept or reject the findings. When new counterparties and formats are introduced, ML learning helps the users create new schema mappings in the human-in-the-loop UI for further processing.
What is human-in-the-loop?
A human-in-the-loop process combines supervised ML with human involvement in training and testing an algorithm. This practice of uniting human and machine intelligence creates an iterative feedback loop that allows the algorithm to produce better results.
You can apply human-in-the-loop to all types of deep learning AI projects, including natural language processing (NLP), computer vision, and transcription. Additionally, you can use human-in-the-loop in conjunction with AI content moderation systems to quickly and effectively analyze user-generated content. We refer this to as human-in-the-loop decision-making, where content is flagged by the AI and human moderators review what has been flagged.
The harmonious relationship between people and AI has several benefits, including:
- Accuracy – In the context of document processing, there are limitations to how much of the analysis can be automated. AI can miss content that should be flagged (a false positive), and they can also incorrectly flag content that may be harmless (a false negative). Humans are essential in the content moderation process because they can interpret things such as context and multilingual text.
- Increased efficiency – Machine intelligence can save significant time and cost by sifting through and trimming down large amounts of data. The task can then be passed on to humans to complete a final sort. Although you can’t automate the entirety of the process, you can automate a significant portion, saving time.
Looking forward: The art of the possible
Amazon Textract is an AWS service that uses ML to automatically extract text, handwriting, and data from any document.
Amazon Textract can extract information from a large variety of documents, including scanned paper records, forms, IDs, invoices, reports, certificates, legal documents, letters, bank statements, tables, handwritten notes, and more. Supported formats include common file types like PNG, JPEG, PDF, and TIFF. For formats like Word or Excel, you can convert them into images before sending them to Amazon Textract. The content is extracted within seconds and then indexed for search through a simple-to-use API.
The Queries feature within the Amazon Textract Analyze Document API provides you the flexibility to specify the data you need to extract from documents. Queries extract information from a variety of documents, like paystubs, vaccination cards, mortgage notes, and insurance cards. You don’t need to know the data structure in the document (table, form, nested data) or worry about variations across document versions and formats. The flexibility that Queries provides reduces the need to implement postprocessing and reliance on manual review of extracted data.
Conclusion
The automation of derivatives confirmation boosts the capacity of the operations team by saving processing time. In this post, we showcased common challenges in derivatives confirms processing and how can you use AWS intelligent document processing services to overcome them. The big part of capital markets’ back-office operations involves documents processing. The approach showed in this post sets a pattern for many back-office documents processing use cases, benefiting the capital markets industry in reducing costs and enhancing staff productivity.
We recommend a thorough review of Security in Amazon Textract and strict adherence to the guidelines provided. To learn more about the pricing of the solution, review the pricing details of Amazon Textract, Lambda, and Amazon S3.
“Using Amazon Textract and Serverless services, we have been able to build an end-to-end digital workflow for derivatives processing. We are expecting straight-through processing rates to increase to over 90%, reducing operational risks and costs associated with manual interventions. This automation provides the resilience and flexibility required to adapt to evolving market structures like T+1 settlement timeframes.”
– Stephen Kim, CIO, Head of Corporate Technology, Jefferies
About the Authors
 Vipul Parekh, is a senior customer solutions manager at AWS guiding our Capital Markets customers in accelerating their business transformation journey on Cloud. He is a GenAI ambassador and a member of AWS AI/ML technical field community. Prior to AWS, Vipul played various roles at the top investment banks, leading transformations spanning from front office to back-office, and regulatory compliance areas.
Vipul Parekh, is a senior customer solutions manager at AWS guiding our Capital Markets customers in accelerating their business transformation journey on Cloud. He is a GenAI ambassador and a member of AWS AI/ML technical field community. Prior to AWS, Vipul played various roles at the top investment banks, leading transformations spanning from front office to back-office, and regulatory compliance areas.
 Raj Talasila, is a senior technical program manager at AWS. He comes to AWS with 30+ years of experience in the Financial Services, Media and Entertainment, and CPG.
Raj Talasila, is a senior technical program manager at AWS. He comes to AWS with 30+ years of experience in the Financial Services, Media and Entertainment, and CPG.
 Saby Sahoo, is a senior solutions architect at AWS. Saby has 20+ years of experience in the field of design and implementation of IT Solutions, Data Analytics, and AI/ML/GenAI.
Saby Sahoo, is a senior solutions architect at AWS. Saby has 20+ years of experience in the field of design and implementation of IT Solutions, Data Analytics, and AI/ML/GenAI.
 Sovik Kumar Nath is an AI/ML solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Source link
lol