
In Ahead of AI, I try to strike a balance between discussing recent research, explaining AI-related concepts, and delving into general AI-relevant news and developments. Given that the previous issues leaned heavily towards research, I aim to address the latest trends in this issue.
Specifically, I’ll explore the current endeavors of major tech companies. It appears that every one of these entities is either training or developing LLMs, with a noticeable shift of their core operations towards AI — thus the title “LLM Businesses and Busyness.”
It’s worth noting that the initial segment of this article will focus on discussions related to these companies. None of this content is sponsored. It’s 100% based on my thoughts and what I found interesting.
For those particularly interested in open-source and freely accessible LLMs, fear not. This edition will also spotlight some innovative LLMs that have garnered attention due to their small nature and exceptional benchmark results.
Given that LoRA is a favored technique in research for efficient finetuning, I will also delve into two new intriguing variants that were proposed last month. To conclude, I’ll highlight the recent launches of some major open-source initiatives.
OpenAI started rolling out GPT-4V to ChatGPT Pro users with a bold announcement that ChatGPT could now “see, hear and speak.” This is the multimodal ChatGPT version that I alluded to in previous issues.
The release is accompanied by a 166-page technical report from researchers at Microsoft, who illustrate and analyze the different use cases with hands-on examples: The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision).
In a nutshell, GPT-4V allows you to upload images and audio to the ChatGPT interface and ask questions about it. I tried one of my favorite use cases, extracting the LaTeX code for equations (very helpful when writing papers), and it seems to work quite well.
By the way, if you are interested in the equation to LaTeX conversion, I recommend checking out Mathpix, which has been doing the same thing for many years more accurately. I am a long-term subscriber since I use it almost daily for extracting equations from books and papers for my personal notes in Markdown. (I am not affiliated and have not been sponsored to say this.)
Back to GPT-4V: while I currently don’t have a use case that requires describing general pictures to me, I can see this being useful in certain automation workflows, though, brainstorming, and so forth.
But note that while this is impressive, Google’s Bard supported images, including the above LaTeX extraction capabilities, for a while now. While GPT4-V is a nice improvement of the ChatGPT interface, Google’s less popular Bard chatbot was ahead of OpenAI this time (although, according to rumors, Google is using two separate models/API calls for this whereas OpenAI may be using a unified LLM model).
If you are interested in outfitting open-source LLMs like Falcon or Llama 2 with multimodal capabilities, I recommend checking out the Llama-Adapter v2 method (despite its name, it’s not just for Llama models), which I covered a few months ago in Ahead of AI #8.
I usually try not to pay attention to ads, but I recently stumbled upon one on LinkedIn that emphasizes how everyone is going all-in on the development of custom and next-generation AI models. But as always, the bottleneck is the data (or the lack thereof).
Remember the term Big Data that was commonly used >10 years ago? It would not surprise me if data becomes an even more hotly traded commodity in the upcoming months or years, similar to how oil has been in the past few decades, to use a worn-out analogy.
Data, or data usage rights, might indeed become scarcer (or at least costlier) in the future as more and more platforms are closing up their free API access. Examples of that we have seen earlier this year include Reddit and Twitter/X. The latter has also just updated its usage terms to prevent crawling and scraping last month.
This summer, major online publishers such as CNN, ABC, and the New York Times took steps to prevent OpenAI’s crawlers from freely accessing their websites’ content.
And last week, Google introduced a new flag for a website’s robots.txt file, allowing publishers to opt out of having their articles used as AI training data.
Say what you may about the impact of AI, but one undeniable effect has been its role in ushering in a restructuring of the internet.
While companies are working on improved search capabilities and helpful chatbots, the content these tools are supposed to find for a user will be harder to access. One silver lining might be that this will all lead to hopefully stronger cybersecurity and authenticity verification systems.
It’s hard to believe that it’s already 1 1/2 years since DALL-E 2 was launched and popularized text-to-image generative AI. Last month, OpenAI announced the new version DALL-E 3 and made it available on the Bing Create website where OpenAI’s DALL-E 3 model is offered.
I must say that the original announcement was a bit misleading as it first looked like DALL-E 3 is capable of generating image annotations, as shown in the screenshot below:
However, this annotation is just added by the author for illustration purposes.
In either case, I am not a heavy text-to-image AI user, but I must say that after playing around with different prompts on the Bing Create website, the results are quite stunning.
The Wall Street Journal reported, “Nvidia’s French Offices Are Raided in Cloud Inquiry.” Further, the newspaper stated, “Typically, such raids are hours-long exercises where officials arrive early in the morning, search the company’s premises, seize physical and digital materials, and interview employees as they come in.”
While the French authorities have not disclosed the reason for the raid, it might be related to Nvidia’s 90% market share in the AI chip sector.
Having trained deep learning models on Nvidia hardware for over a decade, I believe its dominant market share is attributed to its superior software support through CUDA and cuDNN. While there are competent AMD GPUs, the software support is still seen as experimental, as mentioned by colleagues who’ve used AMD GPUs with deep learning frameworks. (Although, I recently read reports from users who had good experiences with AMD GPUs “after pulling some hair.”)
Additionally, Google’s TPUs and Amazon’s Trainium chips are, to the best of my knowledge, not currently available for purchase. Furthermore, TPU support via XLA is primarily optimized for Google’s proprietary software, like TensorFlow and Jax, making it less versatile than CUDA. (For instance, I utilized CUDA for molecular dynamics simulations during my undergraduate studies even before deep learning became popular.)
In my opinion, Nvidia’s large market share is partly owed to their more mature software support. Of course, it’s a good thing for the consumer to have more alternatives, and as the saying goes, “competition is good for business.”
In a surprising news article, Reuters reported that OpenAI is exploring the possibility of manufacturing its own AI chips.
In recent years, there’s been a growing trend toward vertical integration, a business strategy where a company controls multiple stages of its production process. A notable example is Apple producing its own processors for the iPhone and Mac. Within the realm of AI, Google has developed TPUs and Amazon has created Trainium chips.
This is not discussed within the Reuters article above, but I find it interesting that currently, Microsoft stands out as the only major cloud provider that hasn’t developed its own custom AI chips. Given Microsoft’s substantial investment in OpenAI, it’s possible that Microsoft Azure might benefit from custom AI inference and/or training chips in the future. As always, a significant challenge will be ensuring software support and seamless integration with major deep learning libraries like PyTorch.
Shortly after writing the previous section on OpenAI’s chip plans and the speculation about Microsofts potential interest in catching up with Google and Amazon when it comes to developing custom AI chips for their data centers, a new article came out that mentions exactly that. According to The Information, Microsoft plans to unveil a chip designed for data centers that train and run LLMs in November.
Amazon has invested $1.25 billion in Anthropic, the developer of a ChatGPT-like chatbot called Claude. This investment allegedly constitutes approximately 23% of Anthropic’s equity. There’s also an option for an additional $4 billion investment at a later stage. Interestingly, the investment is not in cash but in cloud credits for model training using Amazon’s in-house Trainium chips.
This also means that Amazon now also has access to a general-purpose chatbot, Claude, which they can offer to customers, following Google’s Bard and Microsoft’s association with ChatGPT.
A few days after the announcement above, it was reported that Anthropic in Talks to Raise $2 Billion From Google and Others Just Days After Amazon Investment, which is an interesting development.
Many new LLMs are hitting the public benchmark leaderboards each week. The two most interesting and notable ones I’ve been toying around in the last couple of weeks have been phi-1.5 and Mistral, which I wanted to highlight in this newsletter.
Both phi-1.5 and Mistral are very capable yet relatively small (1.3 and 7 billion parameters versus GPT-3’s 175 billion parameters) and come with openly available weights that can be used. On that note, there’s an interesting and accurate quote by Percy Liang making the distinction between open LLMs and open-source LLMs:
> “Many ‘open’ language models only come with released weights. In software, this is analogous to releasing a binary without code (you wouldn’t call this open-source). To get the full benefits of transparency, you need the training data. GPT-J, GPT-NeoX, BLOOM, RedPajama do this.”
If you are interested in using or finetuning phi-1.5 or Mistral, both LLMs are available via the open-source Lit-GPT repository, which I help maintain.
Phi-1.5 is a “small” 1.3 billion parameter LLM with an impressive performance for its size.
How does this small model accomplish such a good performance? The secret ingredient seems to be the high-quality data.
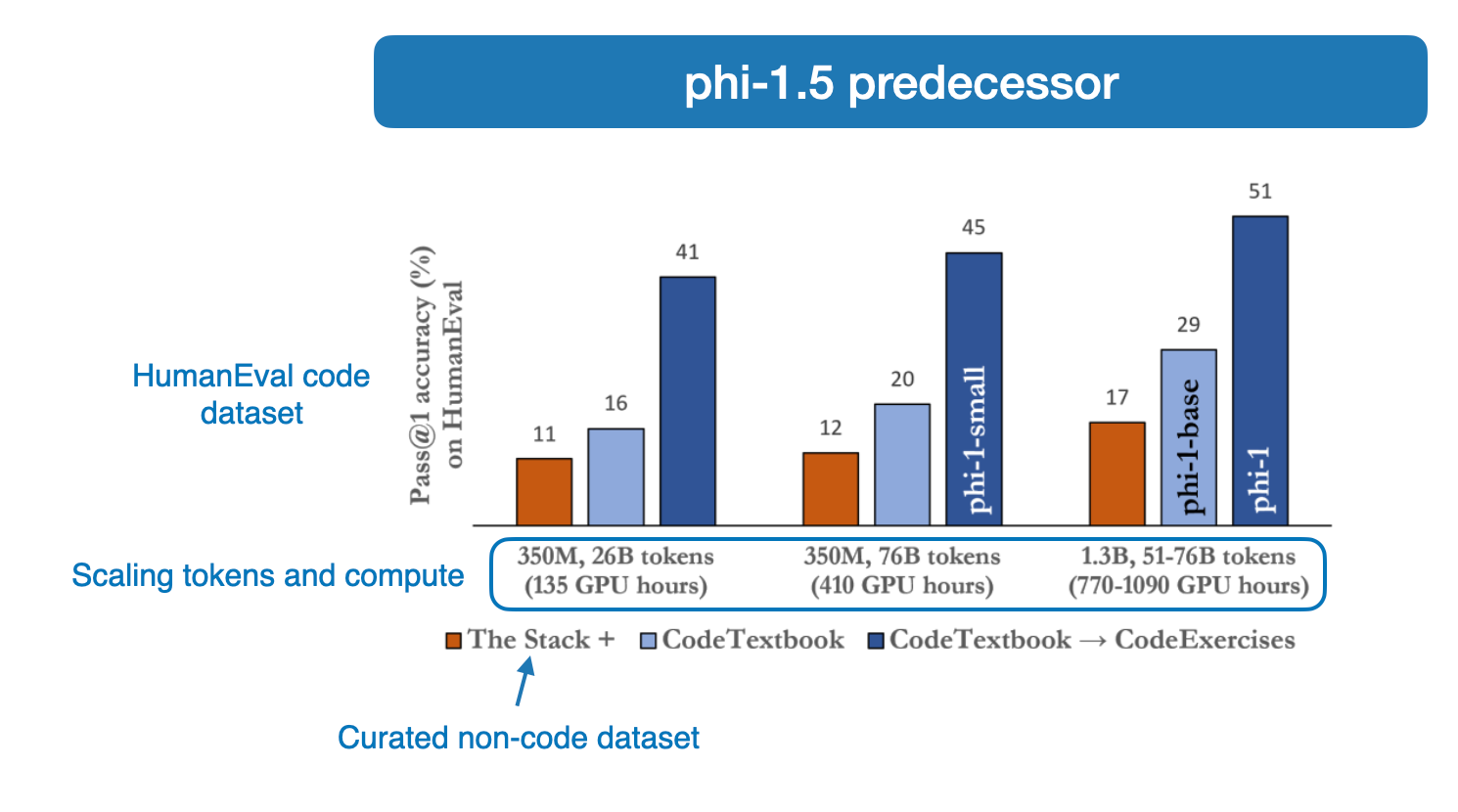
The pretraining is based on the Textbooks Is All You Need approach that I briefly covered in the Ahead AI research highlights earlier this summer, where researchers trained the original 1.3B phi model on a relatively small 6B token “textbook quality” dataset from the web plus 1B tokens of exercises synthesized via GPT-3.5.
The 1.3B phi-1.5 successor model was trained on a similar “high-quality” dataset, this time using ~20B tokens of textbook-quality synthetic text on top of 7B tokens of code from The Stack, StackOverflow, and others. It’s worth noting that phi-1.5 has only undergone pretraining, not instruction finetuning — the latter could potentially improve its performance even further.
The authors hypothesize that the model gains instruction following capabilities without being instruction finetuning, which is an interesting observation. However, phi-1.5 has been pretrained on a dataset that has been generated by instruction-prompting another LLM. So, in my opinion, it should not be totally surprising that the model gains certain instruction finetuning from the pretraining stage. (Supervised instruction finetuning is a next-word prediction task similar to pretraining, as I described in the previous issue of Ahead of AI.)
You can read more about the phi-1.5 training details in Textbooks Are All You Need II: phi-1.5 technical report.
Susan Zhang’s posts on X started debates regarding the performance metrics of phi-1.5, speculating that the model may have unintentionally been trained using benchmark datasets. Susan Zhang showcases examples where phi-1.5 is very particular with respect to the formatting. For instance, it perfectly answers math questions formatted similarly to the benchmark datasets but starts hallucinating when the format slightly changes. Zhang believes that this indicates that the model is merely memorizing the test dataset.
On that note, in the satirical Pretraining on the Test Set Is All You Need paper, the author trains a small 1M parameter LLM that outperforms all other models, including the 1.3B phi-1.5 model. This is achieved by training the model on all downstream academic benchmarks. It appears to be a subtle criticism underlining how easily benchmarks can be “cheated” intentionally or unintentionally (due to data contamination).
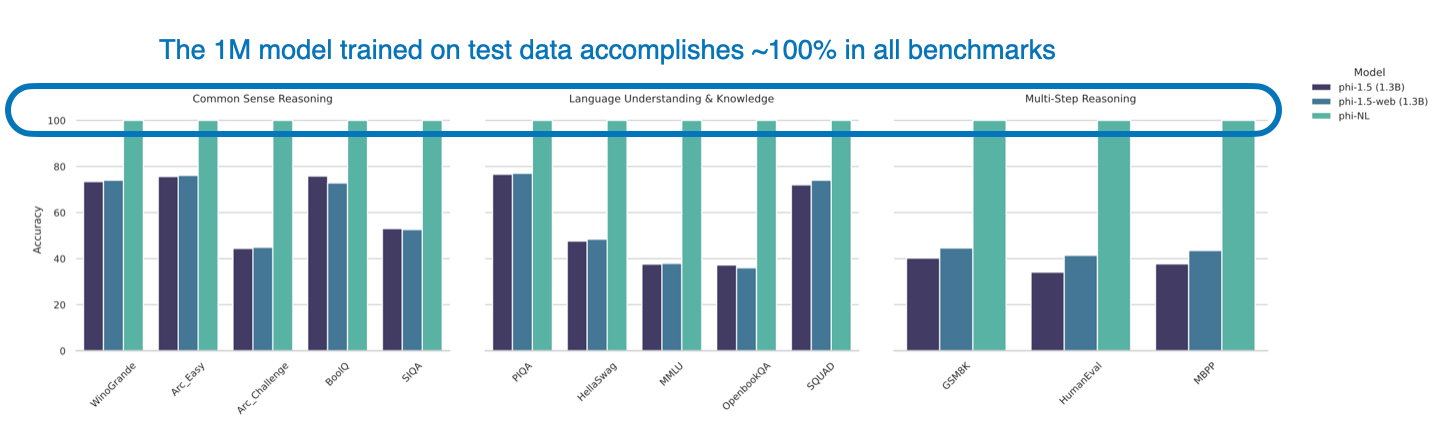
The bottom line is that we currently don’t have a good way of telling whether a model has been trained on benchmark or test data. This is especially true since most companies no longer share or disclose the training data, which is likely to prevent lawsuits (e.g., see” ‘Game of Thrones’ creator and other authors sue ChatGPT-maker OpenAI for copyright infringement“).
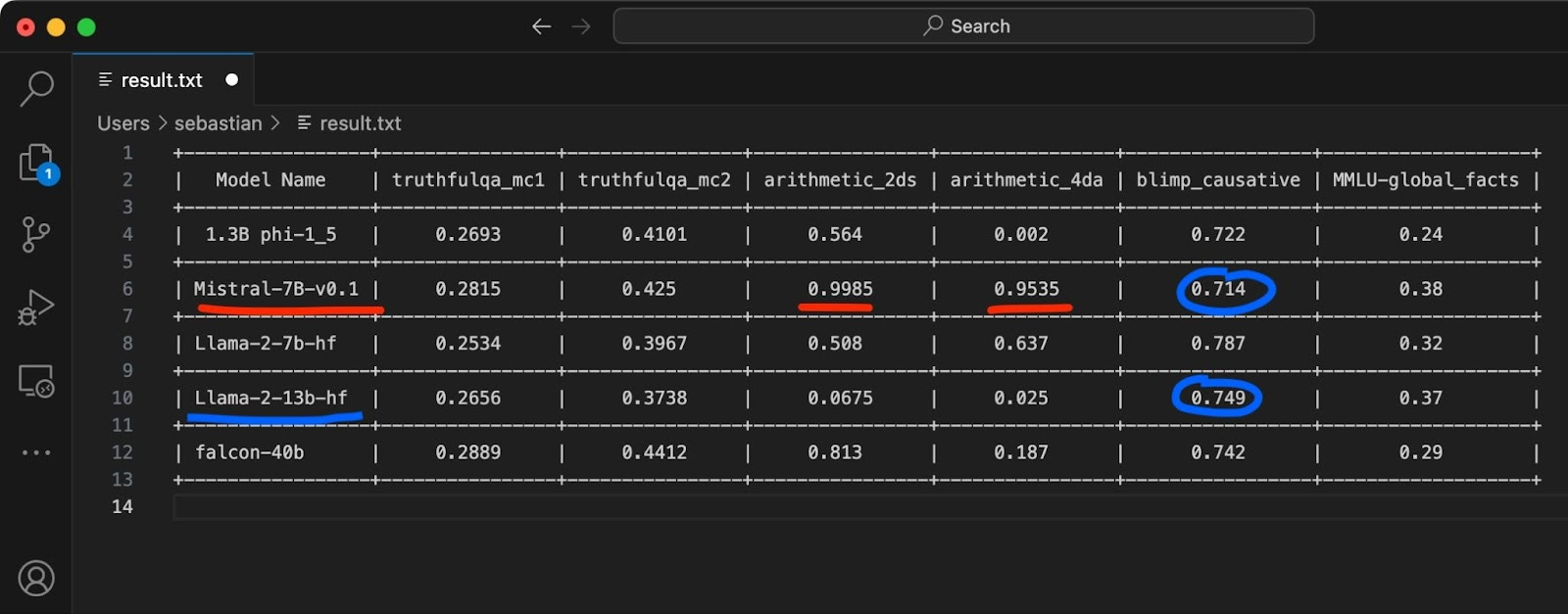
In its first public announcement, the new AI company Mistral AI shared its first openly available LLM. According to the company’s benchmarks, the 7B Mistral model outperforms the larger 13B Llama 2 model on all benchmarks and even approaches CodeLlama 7B performance on code at the same time. Hence, it’s been the talk of the (social media) town last week.
I tried Mistral on a randomly selected subset of Evaluation Harness tasks. It does perform (almost suspiciously) well on arithmetic benchmarks. It does not, however, beat the 13B Llama 2 model on all tasks.
If you are interested in giving, Mistral and Phi-1.5 have also been added to the Lit-GPT repository that I regularly contribute to and which is part of the NeurIPS LLM efficiency challenge.
Now, some people have raised concerns similar to Phi-1.5. I.e., people are discussing that there was some potential data contamination, which led the model to be trained on test data, which could explain some of the high benchmark scores. Overall, it does seem to be very interesting and capable, though.
Moreover, it also uses an interesting self-attention variant, sliding window attention, to save memory and improve computational throughput for faster training. (Sliding window attention was previously proposed in Child et al. 2019 and Beltagy et al. 2020.)
The sliding window attention mechanism is essentially a fixed-sized attention block that allows a current token to attend only a specific number of previous tokens (instead of all previous tokens), which is illustrated in the figure below.
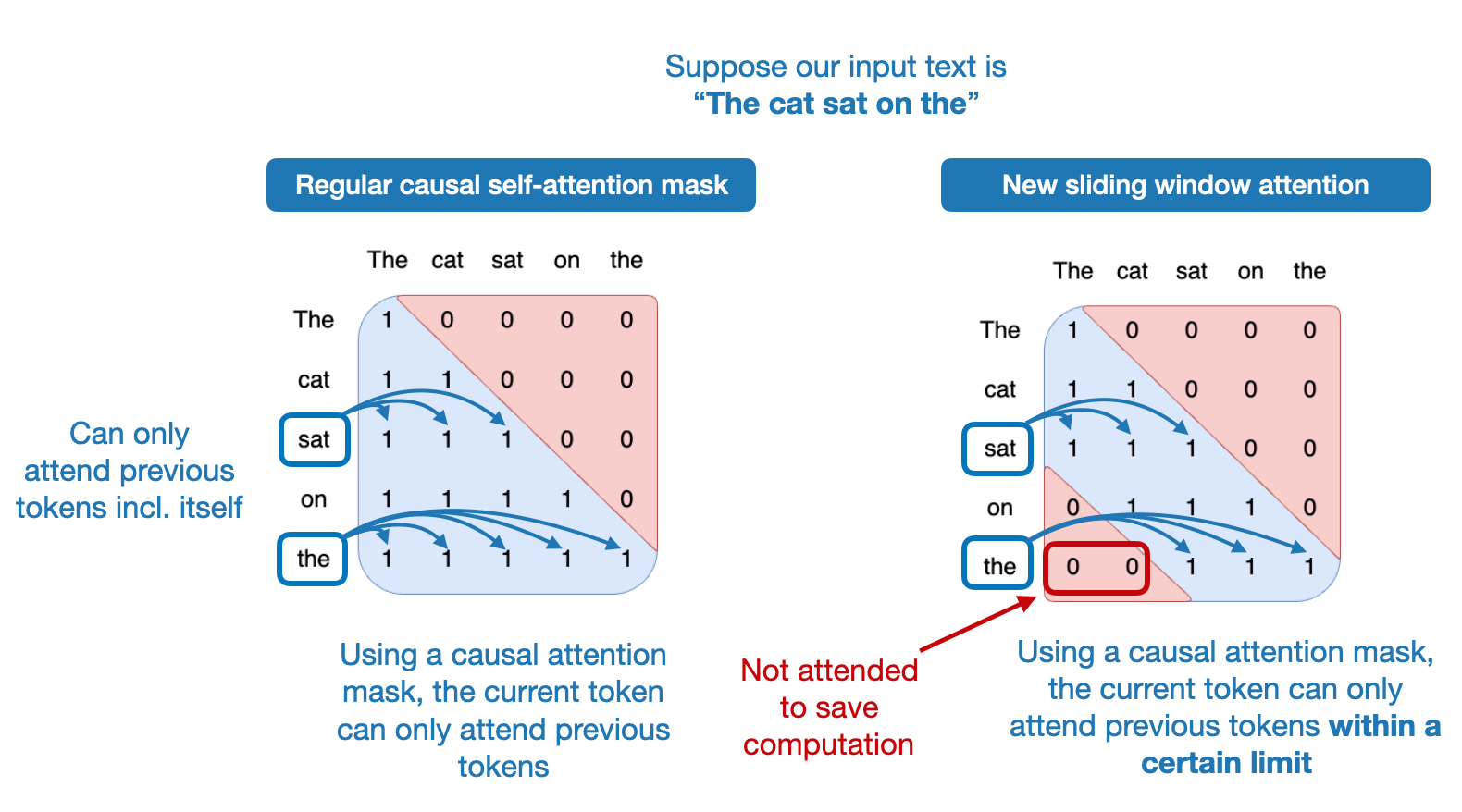
In this specific case, the attention block size is 4096 tokens, and the researchers were training the model with up to 100k token context sizes.
To provide a more concrete example, in regular self-attention, a model at the 50,000th token can attend all previous 49,999 tokens. In sliding window self-attention, the Mistral model can only attend tokens 45,904 to 50,000.
Does this mean that the model can’t access the whole context all at once? Not quite. The Mistral developers argue that the model can still access all input tokens in a hierarchical indirect way, as illustrated in the figure below.
Since there are no research papers and ablation studies for GPT-like LLMs trained with sliding window attention, we don’t know yet whether it positively or negatively affects the modeling performance. However, it surely has a positive effect on the computational throughput and the Mistral team mentioned that it led to a 2x speed improvement.
LoRA (short for “low-rank adaptation”) is the single most popular method for finetuning LLMs efficiently, and researchers developed two new variants in recent weeks: QA-LoRA and LongLoRA.
(In short, LoRA involves finetuning a pretrained model by adapting a low-rank projection of its parameters. Most readers are probably familiar with how LoRA works, but if there’s interest, I can share a from-scratch implementation and explanation in a future article to explain how it works in detail. Please let me know in the comments.)
In LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, researchers propose LongLoRA, an efficient method for finetuning LLMs that expands their context sizes without the usual high computational costs associated with longer contexts. The approach uses sparse local attention, allowing computation savings during finetuning. One can then still use regular, dense attention during inference time.
QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models is essentially a small modification or improvement over QLoRA (quantized LoRA) that addresses its higher computational efficiency cost — QLoRA saves GPU memory but increases the runtime due to dequantizing the quantized weights of the base model in each forward pass.
QA-LoRA, in contrast to QLoRA, quantizes the LoRA (adapter) weights, avoiding a costly conversion of the quantized base model weights back into 16-bit when adding the adapter weights. This concep summarized in the annotated figure below.
A little nitpick: In Table 2, QA-LoRA is about 2x faster than QLoRA for finetuning. However, a much smaller number of parameters was used for the adapter weights. I believe it would have been interesting to use the same number of parameters for both when comparing their speeds.
Lastly, I want to close this article with highlighting some notable open-source releases that don’t happen too often: Python 3.12, PyTorch 2.1, and XGBoost 2.0.
The newest version of Python comes with a lot of computational performance improvements with the asyncio standard library package being up to 75% faster as mentioned in the official What’s New release notes.
Python Weekly, my favorite Python newsletter, summarized some of the major changes as follows:
-
More flexible f-string parsing
-
Support for the buffer protocol in Python code
-
A new debugging/profiling API
-
Support for isolated subinterpreters with separate Global Interpreter Locks
-
Even more improved error messages.
-
Support for the Linux perf profiler to report Python function names in traces.
-
Many large and small performance improvements
Last year was a particularly big year for PyTorch with its 2.0 release featuring torch.compile as a new option to convert dynamic PyTorch graphs into full or partial static graphs for performance boosts. This year, the PyTorch team released PyTorch 2.1. As far I can tell, no breaking changes were introduced, and the focus was more on performance enhancements.
A notable feature (although still in beta) is that torch.compile can now also compile NumPy operations via translating them into PyTorch-equivalent operations. This means that we can now GPU-accelerate NumPy code as well.
The associated domain libraries such as torchvision also got some attention. For example, the popular data augmentations CutMix and MixUp were now finally integrated.
Yes, machine learning without deep neural networks and LLMs is still relevant! XGBoost is one of the most popular flavors and software implementations of gradient boosting, which is still considered state-of-the-art for tabular datasets.
XGBoost has been around for almost 10 years and just came out with a big XGBoost 2.0 release that features better memory efficiency, support for large datasets that don’t fit into memory, multi-target trees, and more.
This magazine is personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.
Your support means a great deal! Thank you!
Source link
lol