Extracting valuable insights from customer feedback presents several significant challenges. Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Scalability becomes an issue as the amount of feedback grows, hindering the ability to respond promptly and address customer concerns. In addition, capturing granular insights, such as specific aspects mentioned and associated sentiments, is difficult. Inefficient routing and prioritization of customer inquiries or issues can lead to delays and dissatisfaction. These pain points highlight the need to streamline the process of extracting insights from customer feedback, enabling businesses to make data-driven decisions and enhance the overall customer experience.
Large language models (LLMs) have transformed the way we engage with and process natural language. These powerful models can understand, generate, and analyze text, unlocking a wide range of possibilities across various domains and industries. From customer service and ecommerce to healthcare and finance, the potential of LLMs is being rapidly recognized and embraced. Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. Unlike traditional natural language processing (NLP) approaches, such as classification methods, LLMs offer greater flexibility in adapting to dynamically changing categories and improved accuracy by using pre-trained knowledge embedded within the model.
Amazon Bedrock, a fully managed service designed to facilitate the integration of LLMs into enterprise applications, offers a choice of high-performing LLMs from leading artificial intelligence (AI) companies like Anthropic, Mistral AI, Meta, and Amazon through a single API. It provides a broad set of capabilities like model customization through fine-tuning, knowledge base integration for contextual responses, and agents for running complex multi-step tasks across systems. With Amazon Bedrock, developers can experiment, evaluate, and deploy generative AI applications without worrying about infrastructure management. Its enterprise-grade security, privacy controls, and responsible AI features enable secure and trustworthy generative AI innovation at scale.
To create and share customer feedback analysis without the need to manage underlying infrastructure, Amazon QuickSight provides a straightforward way to build visualizations, perform one-time analysis, and quickly gain business insights from customer feedback, anytime and on any device. In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using natural language, without the need to write SQL queries or learn a BI tool. This user-friendly approach to data exploration and visualization empowers users across the organization to analyze customer feedback and share insights quickly and effortlessly.
In this post, we explore how to integrate LLMs into enterprise applications to harness their generative capabilities. We delve into the technical aspects of workflow implementation and provide code samples that you can quickly deploy or modify to suit your specific requirements. Whether you’re a developer seeking to incorporate LLMs into your existing systems or a business owner looking to take advantage of the power of NLP, this post can serve as a quick jumpstart.
Advantages of adopting generative approaches for NLP tasks
For customer feedback analysis, you might wonder if traditional NLP classifiers such as BERT or fastText would suffice. Although these traditional machine learning (ML) approaches might perform decently in terms of accuracy, there are several significant advantages to adopting generative AI approaches. The following table compares the generative approach (generative AI) with the discriminative approach (traditional ML) across multiple aspects.
| . | Generative AI (LLMs) | Traditional ML |
| Accuracy | Achieves competitive accuracy by using knowledge acquired during pre-training and utilizing the semantic similarity between category names and customer feedback. Particularly beneficial if you don’t have much labeled data. | Can achieve high accuracy given sufficient labeled data, but performance may degrade if you don’t have much labeled data and rely solely on predefined features, because it lacks the ability to capture semantic similarities effectively. |
| Acquiring labeled data | Uses pre-training on large text corpora, enabling zero-shot or few-shot learning. No labeled data is needed. | Requires labeled data for all categories of interest, which can be time-consuming and expensive to obtain. |
| Model generalization | Benefits from exposure to diverse text genres and domains during pre-training, enhancing generalization to new tasks. | Relies on a large volume of task-specific labeled data to improve generalization, limiting its ability to adapt to new domains. |
| Operational efficiency | Uses prompt engineering, reducing the need for extensive fine-tuning when new categories are introduced. | Requires retraining the model whenever new categories are added, leading to increased computational costs and longer deployment times. |
| Handling rare categories and imbalanced data | Can generate text for rare or unseen categories by using its understanding of context and language semantics. | Struggles with rare categories or imbalanced classes due to limited labeled examples, often resulting in poor performance on infrequent classes. |
| Explainability | Provides explanations for its predictions through generated text, offering insights into its decision-making process. | Explanations are often limited to feature importance or decision rules, lacking the nuance and context provided by generated text. |
Generative AI models offer advantages with pre-trained language understanding, prompt engineering, and reduced need for retraining on label changes, saving time and resources compared to traditional ML approaches. You can further fine-tune a generative AI model to tailor the model’s performance to your specific domain or task. For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training.
In this post, we primarily focus on the zero-shot and few-shot capabilities of LLMs for customer feedback analysis. Zero-shot learning in LLMs refers to their ability to perform tasks without any task-specific examples, whereas few-shot learning involves providing a small number of examples to improve performance on a new task. These capabilities have gained significant attention due to their ability to strike a balance between accuracy and operational efficiency. By using the pre-trained knowledge of LLMs, zero-shot and few-shot approaches enable models to perform NLP with minimal or no labeled data. This eliminates the need for extensive data annotation efforts and allows for quick adaptation to new tasks.
Solution overview
Our solution presents an end-to-end generative AI application for customer review analysis. When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation.
The following diagram illustrates the architecture and workflow of the proposed solution.
{kind=link}
The customer review analysis workflow consists of the following steps:
- A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) data lake, invoking the processing using AWS Step Functions.
- The Step Functions workflow starts. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data.
- The raw data is processed by an LLM using a preconfigured user prompt. The LLM generates output based on the user prompt.
- The processed output is stored in a database or data warehouse, such as Amazon Relational Database Service (Amazon RDS).
- The stored data is visualized in a BI dashboard using QuickSight.
- The user receives a notification when the results are ready and can access the BI dashboard to view and analyze the results.
The project is available on GitHub and provides AWS Cloud Development Kit (AWS CDK) code to deploy. The AWS CDK is an open source software development framework for defining cloud infrastructure in code (IaC) and provisioning it through AWS CloudFormation. This provides an automated deployment experience on your AWS account. We highly suggest you follow the GitHub README and deployment guidance to get started.
In the following sections, we highlight the key components to explain this automated framework for insight discovery: workflow orchestration with Step Functions, prompt engineering for the LLM, and visualization with QuickSight.
Prerequisites
This post is intended for developers with a basic understanding of LLM and prompt engineering. Although no advanced technical knowledge is required, familiarity with Python and AWS Cloud services will be beneficial if you want to explore our sample code on GitHub.
Workflow orchestration with Step Functions
To manage and coordinate multi-step workflows and processes, we take advantage of Step Functions. Step Functions is a visual workflow service that enables developers to build distributed applications, automate processes, orchestrate microservices, and create data and ML pipelines using AWS services. It can automate extract, transform, and load (ETL) processes, so multiple long-running ETL jobs run in order and complete successfully without manual orchestration. By combining multiple Lambda functions, Step Functions allows you to create responsive serverless applications and orchestrate microservices. Moreover, it can orchestrate large-scale parallel workloads, enabling you to iterate over and process large datasets, such as security logs, transaction data, or image and video files. The definition of our end-to-end orchestration is detailed in the GitHub repo.
Step Functions invokes multiple Lambda functions for the end-to-end workflow:
Step Functions uses the Map state processing modes to orchestrate large-scale parallel workloads. You can modify the Step Functions state machine to adapt to your own workflow, or modify the Lambda function for your own processing logic.

Prompt engineering
To invoke Amazon Bedrock, you can follow our code sample that uses the Python SDK. A prompt is natural language text describing the task that an AI should perform. Prompt engineering may involve phrasing a query, specifying a style, providing relevant context, or assigning a role to the AI, such as “You are helpful assistant.” We provide a prompt example for feedback categorization. For more information, refer to Prompt engineering. You can modify the prompt to adapt to your own workflow.
This framework uses a sample prompt to generate tags for user feedback from the predefined tags listed. You can engineer the prompt based on your user feedback style and business requirements.
Visualization with QuickSight
We have successfully used an LLM to categorize the feedback into predefined categories. After the data is categorized and stored in Amazon RDS, you can use QuickSight to generate an overview and visualize the insights from the dataset. For deployment guidance, refer to GitHub Repository: Result Visualization Guide.
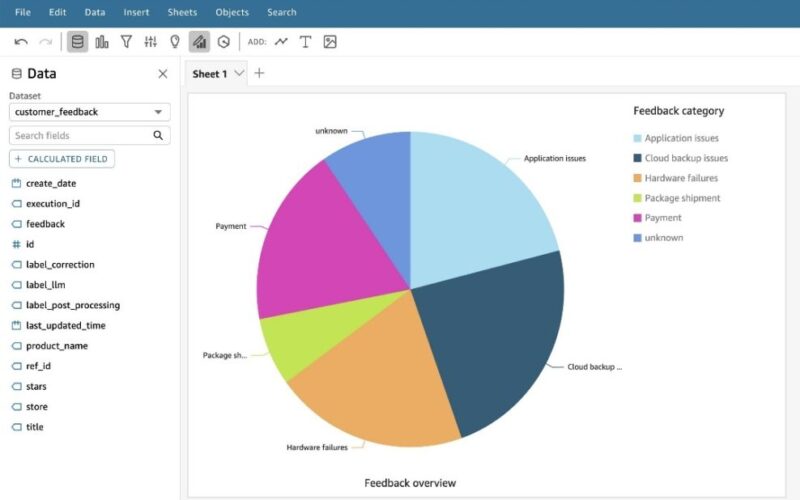
We use an LLM from Amazon Bedrock to generate a category label for each piece of feedback. This generated label is stored in the label_llm field. To analyze the distribution of these labels, select the label_llm field along with other relevant fields and visualize the data using a pie chart. This will provide an overview of the different categories and their proportions within the feedback dataset, as shown in the following screenshot.

In addition to the category overview, you can also generate a trend analysis of the feedback or issues over time. The following screenshot demonstrates a trend where the number of issues peaked in March but then showed immediate improvement, with a reduction in the number of issues in subsequent months.

Sometimes, you may need to create paginated reports to present to a company management team about customer feedback. You can use Amazon QuickSight Paginated Reports to create highly formatted multi-page reports from the insight extracted by LLMs, define report layouts and formatting, and schedule report generation and distribution.
Clean up
If you followed the GitHub deployment guide and want to clean up afterwards, delete the stack customer-service-dev on the CloudFormation console or run the command cdk destroy customer-service-dev. You can also refer to the cleanup section in the GitHub deployment guide.
Applicable real-world applications and scenarios
You can use this automated architecture for content processing for various real-world applications and scenarios:
- Customer feedback categorization and sentiment classification – In the context of modern application services, customers often leave comments and reviews to share their experiences. To effectively utilize this valuable feedback, you can use LLMs to analyze and categorize the comments. The LLM extracts specific aspects mentioned in the feedback, such as food quality, service, ambiance, and other relevant factors. Additionally, it determines the sentiment associated with each aspect, classifying it as positive, negative, or neutral. With LLMs, businesses can gain valuable insights into customer satisfaction levels and identify areas that require improvement, enabling them to make data-driven decisions to enhance their offerings and overall customer experience.
- Email categorization for customer service – When customers reach out to a company’s customer service department through email, they often have various inquiries or issues that need to be addressed promptly. To streamline the customer service process, you can use LLMs to analyze the content of each incoming email. By examining the email’s content and understanding the nature of the inquiry, the LLM categorizes the email into predefined categories such as billing, technical support, product information, and more. This automated categorization allows the emails to be efficiently routed to the appropriate departments or teams for further handling and response. By implementing this system, companies can make sure customer inquiries are promptly addressed by the relevant personnel, improving response times and enhancing customer satisfaction.
- Web data analysis for product information extraction – In the realm of ecommerce, extracting accurate and comprehensive product information from webpages is crucial for effective data management and analysis. You can use an LLM to scan and analyze product pages on an ecommerce website, extracting key details such as the product title, pricing information, promotional status (such as on sale or limited-time offer), product description, and other relevant attributes. The LLM’s ability to understand and interpret the structured and unstructured data on these pages allows for the efficient extraction of valuable information. The extracted data is then organized and stored in a database, enabling further utilization for various purposes, including product comparison, pricing analysis, or generating comprehensive product feeds. By using the power of an LLM for web data analysis, ecommerce businesses can provide accuracy and completeness of their product information, facilitating improved decision-making and enhancing the overall customer experience.
- Product recommendation with tagging – To enhance the product recommendation system and improve search functionality on an online website, implementing a tagging mechanism is highly beneficial. You can use LLMs to generate relevant tags for each product based on its title, description, and other available information. The LLM can generate two types of tags: predefined tags and free tags. Predefined tags are assigned from a predetermined set of categories or attributes that are relevant to the products, providing consistency and structured organization. Free tags are open-ended and generated by the LLM to capture specific characteristics or features of the products, providing a more nuanced and detailed representation. These tags are then associated with the corresponding products in the database. When users search for products or browse recommendations, the tags serve as powerful matching criteria, enabling the system to suggest highly relevant products based on user preferences and search queries. By incorporating an LLM-powered tagging system, online websites can significantly improve the user experience, increase the likelihood of successful product discovery, and ultimately drive higher customer engagement and satisfaction.
Conclusion
In this post, we explored how you can seamlessly integrate LLMs into enterprise applications to take advantage of their powerful generative AI capabilities. With AWS services such as Amazon Bedrock, Step Functions, and QuickSight, businesses can create intelligent workflows that automate processes, generate insights, and enhance decision-making.
We have provided a comprehensive overview of the technical aspects involved in implementing such a workflow, along with code samples that you can deploy or customize to meet your organization’s specific needs. By following the step-by-step guide and using the provided resources, you can quickly incorporate this generative AI application into your current workload. We encourage you to check out the GitHub repository, deploy the solution to your AWS environment, and modify it according to your own user feedback and business requirements.
Embracing LLMs and integrating them into your enterprise applications can unlock a new level of efficiency, innovation, and competitiveness. You can learn from AWS Generative AI Customer Stories how others harness the power of generative AI to drive their business forward, and check out our AWS Generative AI blogs for the latest technology updates in today’s rapidly evolving technological landscape.
About the Authors
 Jacky Wu, is a Senior Solutions Architect at AWS. Before AWS, he had been implementing front-to-back cross-asset trading system for large financial institutions, developing high frequency trading system of KRX KOSPI Options and long-short strategies of APJ equities. He is very passionate about how technology can solve capital market challenges and provide beneficial outcomes by AWS latest services and best practices. Outside of work, Jacky enjoys 10km run and traveling.
Jacky Wu, is a Senior Solutions Architect at AWS. Before AWS, he had been implementing front-to-back cross-asset trading system for large financial institutions, developing high frequency trading system of KRX KOSPI Options and long-short strategies of APJ equities. He is very passionate about how technology can solve capital market challenges and provide beneficial outcomes by AWS latest services and best practices. Outside of work, Jacky enjoys 10km run and traveling.
 Yanwei Cui, PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building AI-powered industrial applications in computer vision, natural language processing, and online user behavior prediction. At AWS, he shares his domain expertise and helps customers unlock business potentials and drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
Yanwei Cui, PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building AI-powered industrial applications in computer vision, natural language processing, and online user behavior prediction. At AWS, he shares his domain expertise and helps customers unlock business potentials and drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
 Michelle Hong, PhD, works as Prototyping Solutions Architect at Amazon Web Services, where she helps customers build innovative applications using a variety of AWS components. She demonstrated her expertise in machine learning, particularly in natural language processing, to develop data-driven solutions that optimize business processes and improve customer experiences.
Michelle Hong, PhD, works as Prototyping Solutions Architect at Amazon Web Services, where she helps customers build innovative applications using a variety of AWS components. She demonstrated her expertise in machine learning, particularly in natural language processing, to develop data-driven solutions that optimize business processes and improve customer experiences.
Source link
lol