
Recent advancements in AI are exciting, and will surely have a significant, yet uncertain impact on the future. I think there is a lot we can learn from another groundbreaking technology: the web. In this blog post, I’ll look at what the history of the web can teach us about the future of artificial intelligence, and what this means for developers, models, open source and regulation.
My first introduction to programming was when I discovered Microsoft Word’s ability to create web pages as a teenager. I quickly built my own website and eventually taught myself the basics of HTML, CSS and graphic design. When I discovered Natural Language Processing (NLP), I saw a lot of potential to combine web and AI technologies. Not only that – there are actually many ways in which AI development follows a similar trajectory to web development, and lessons we can learn from that.
I believe one of the biggest mistakes people make when assessing the implications of AI and new capabilities is conflating raising the floor with raising the ceiling. This becomes very clear when we compare different use cases. Technology that raises the floor for instance lets a local store set up a website or web shop without requiring help from a web developer. It also lets a todo list app add AI-powered translation features using an API. Raising the floor means lowering the barriers to entry and making technology more accessible and easier to adopt for the wider industry.
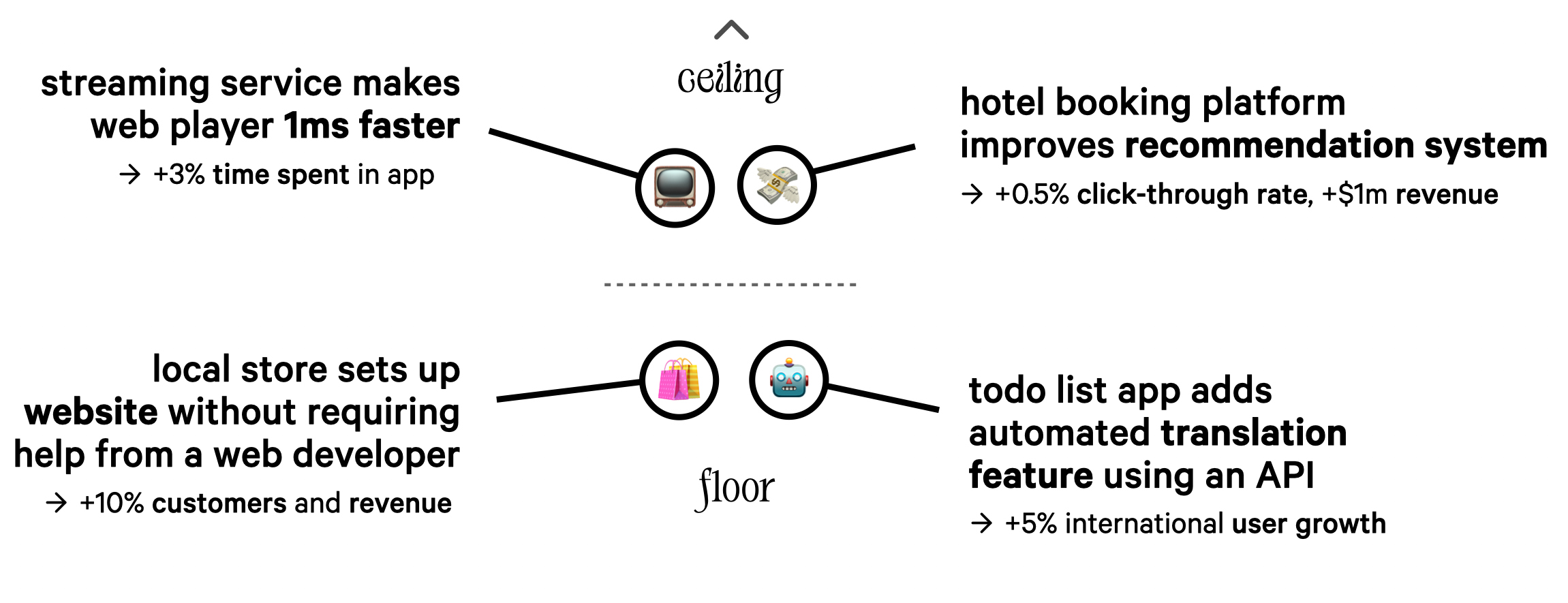
On the other end of the spectrum, the ceiling, companies invest a lot of time and effort into small improvements with big impacts, like a streaming service carefully optimizing their web-based media player to be even a millisecond faster, increasing time spent in-app by its users. A hotel booking platform may invest a lot of resources into improving their recommendation algorithm, because even a minor increase in click-through rates on their emails can significantly boost their revenue.
In the case of AI, a lot is happening at the ceiling. This includes academic research on new models and techniques, and work enhancing development environments, primitives that every project depends on, and even IDEs and the Python programming language itself. Just like browsers and web standards are continuing to push boundaries of what’s possible on the web, AI research keeps unlocking new possibilities. All of this trickles down into frameworks like React, PyTorch or spaCy, and eventually into products at the floor, such as website builders or AI APIs. At the floor, we see high adoption, whereas use cases raising the ceiling are those with particularly high value.
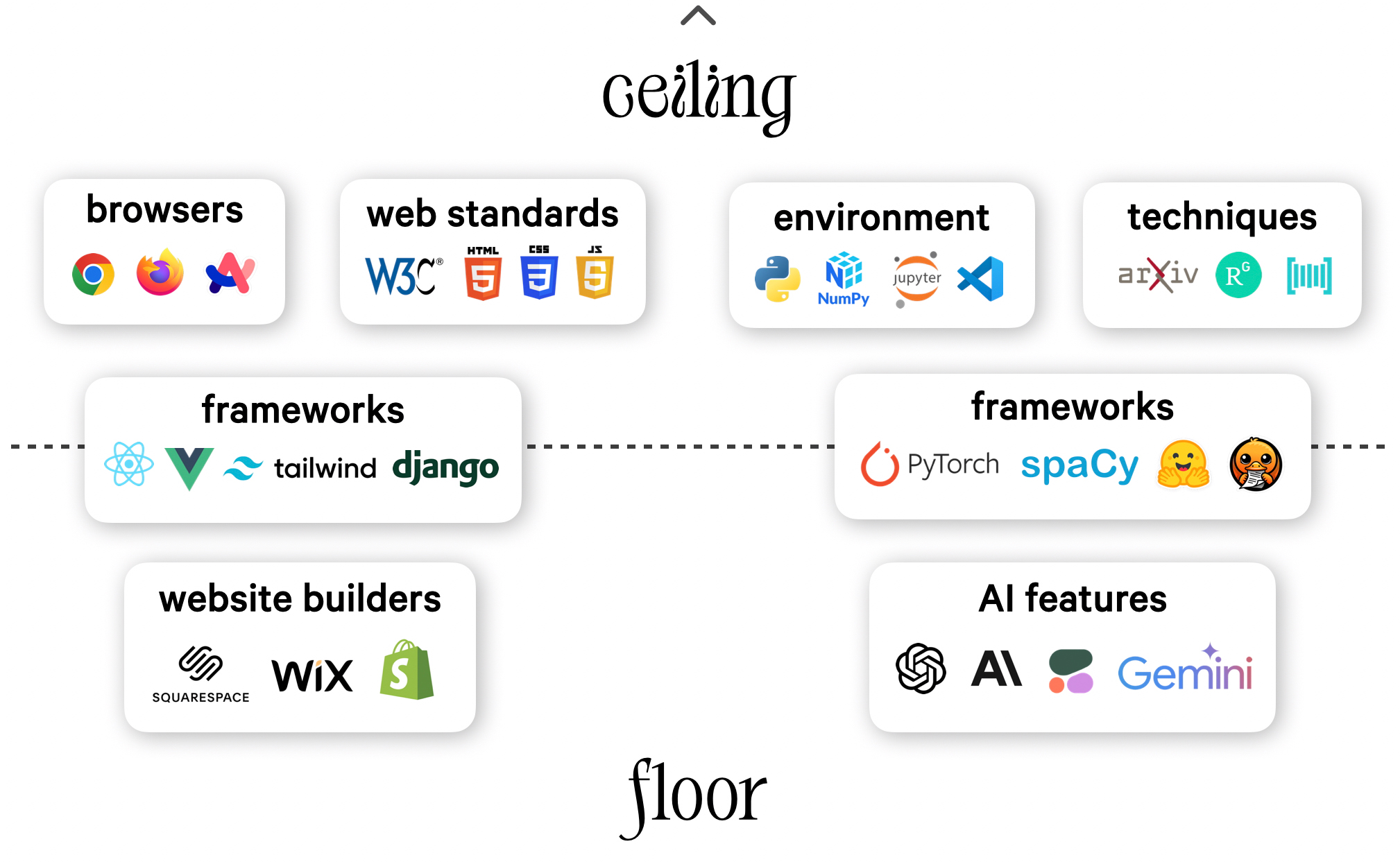
High-value use cases will always be worth the specialized development effort. They’re a clear case where “better is better”. Just because it’s easier for people to set up a website, it doesn’t mean that companies stopped investing in web development – quite the opposite. Similarly, Large Language Models (LLMs) and APIs made it a lot easier for anyone to use powerful AI features and add them to applications. But this doesn’t mean there won’t be demand for AI developers working on high-value use cases, which there’s no shortage of. Technology enables developers to do new things, but it also lets them do a lot more of the same.
The “better is better” situation is going to happen any time there’s a type of arms race or competition. Digital marketing or the attention economy follow this dynamic. If there’s an advantage to being a bit better than your competitors, then everyone has to keep investing, and there will never be a situation where “good enough is good enough”. In fact, back in the day, companies were so hungry for improvement that they invested big-time into Flash, despite generally terrible results. Being left behind seemed like an even worse option than investing more for worse, hoping it’d be an investment towards a new and better future. The same is currently playing out with Generative AI, as evident in the “put a chat bot in front of it” trend and the resulting en-Clippy-fication of consumer-facing products.
In the early days of the internet, websites were mostly static. However, we needed more flexibility so Web 2.0 became all about dynamic and interative features, rendered on the server with PHP, or augmented in the browser with JavaScript. We also saw a rise of blogging and CMS platforms like WordPress, which took care of the back-end complexity and often also hosting. However, this could make websites slower and harder to maintain, or meant giving up control and the ability to build fully custom experiences.
All of this is still relevant today, but if you’ve built a modern website or blog recently, you probably used a static site generator like Hugo or a framework like Next.js, which moves the operational complexity to the build process instead of runtime. Sites are compiled upfront instead of on the server, and optimized for performance using tree shaking and other techniques. With TypeScript, we switched from the trade-offs of a dynamic language to the trade-offs of a compiled language. It’s what people often mean when they complain about how complex web development has gotten these days. But overall, it made the web better and more accessible, and gave us more control.

This actually mirrors a lot of what we’ve been seeing in AI. When machine learning and deep learning were first widely adopted, you’d typically train your own models with libraries like scikit-learn, PyTorch or TensorFlow, or use existing implementations provided by frameworks like spaCy. This often required significant work and investment. But with bigger language models and better generalization, it became possible to rely on pretrained models instead, without or with only very minimal fine-tuning. This has inspired a rise of API platforms like OpenAI or Cohere, to provide easy access to large models and simplify the otherwise sophisticated MLOps required to host them, trading in control and privacy for convenience.
The next step in mitigating those drawbacks is the return to custom models, but with better and more powerful tooling. Here, too, we’re moving the operational complexity from runtime to the development process and are taking advantage of techniques like transfer learning. An example of this is human-in-the-loop distillation and using large generative models to create data for more accurate, smaller, faster and private models that can be deployed in-house. This usage pattern provides the needed flexibility for high-value use cases and makes it viable again to develop AI features in house, just like the modern JavaScript toolchain automates the build process for fully custom websites and web applications.
High-value use cases are worth development effort
One such example of a high-value use case is a project from S&P Global, which we recently published as a case study. To make markets more transparent and provide structured data feeds to their customers, the team developed a new system for extracting real-time commodities trading insights as structured attributes. Because the information can significantly move markets and impact the economy, it’s crucial that it stays in-house and runs in a high-security environment.
By using an LLM during annotation with Prodigy, the team was able to achieve a 10× data development speedup with humans and a model in the loop, requiring only 15 person hours per model to create specialized training and evaluation data. The 6mb spaCy pipelines run at around 16k words per second with accuracies of up to 99%.

This project is a great example of how new techniques and tooling let companies take back control of their models and move the dependency on operationally complex and expensive resources to the development and build process.
In their fight for market dominance, Big Tech companies are trying to shape how we use and deploy technology by reinventing not only the wheel, but also the road along the way. In fact, I don’t think reinventing the wheel is necessarily a bad thing. The problem is when products and companies are also trying to reinvent the road, and lock you into their way of doing things.
Google is not only the most-used search engine, the company also develops the most popular browser Chrome and its engine Chromium, which powers Edge, Opera, Arc and more, and the Gemini model and chat bot integrated into search and other applications. Those are all very useful products by themselves.
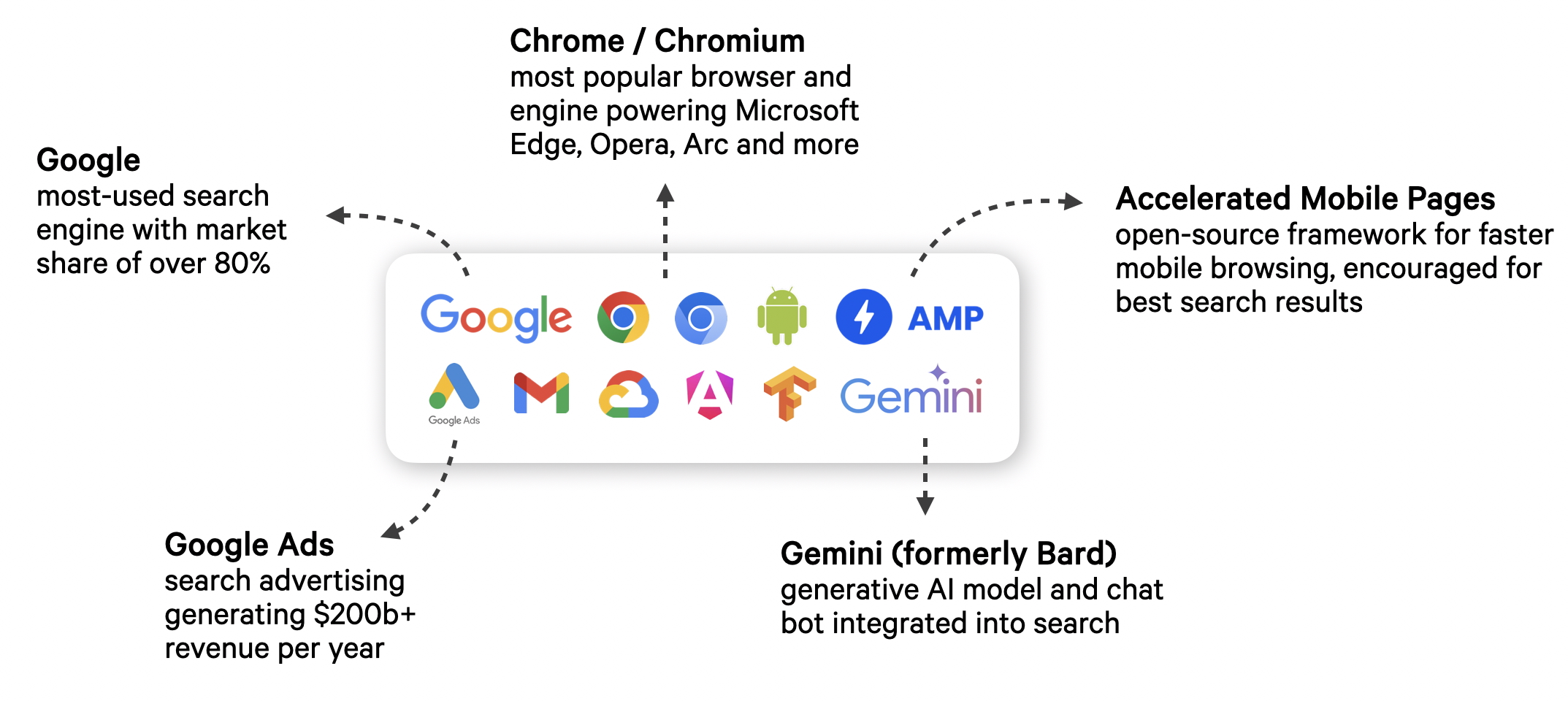
AMP, short for Accelerated Mobile Pages, is another such product, an open-source framework for faster mobile performance. It’s no secret that Google penalizes slow web pages to provide more user-friendly results and encourage websites to adopt modern techniques and web standards. However, critics note that by essentially forcing the web to adopt AMP, Google is exerting undue control and further locking publishers into their ecosystem. And of course, where it all comes together is advertising, generating the company a hefty revenue of over $200 billion a year.
This tried-and-tested strategy of reinventing both the wheel and the road is already well on its way for AI, true to Microsoft’s gameplan of “embrace, extend, extinguish”: embrace a common standard, implement your own extensions and lock users into your ecosystem, dismantling the common standard altogether.
There has been a lot of discussion about the dangers of Generative AI and the need for government regulation. However, an important distinction that’s often missing from the discourse is that between human-facing systems and machine-facing models. “AI” is typically used to refer to both products like ChatGPT, as well as the underlying models like GPT-4 and Gemini (which, in itself, also refers to Google’s chat bot product). Deliberately or not, this muddies the waters and can have lasting consequences for how regulation deals with model artifacts and open-source software.
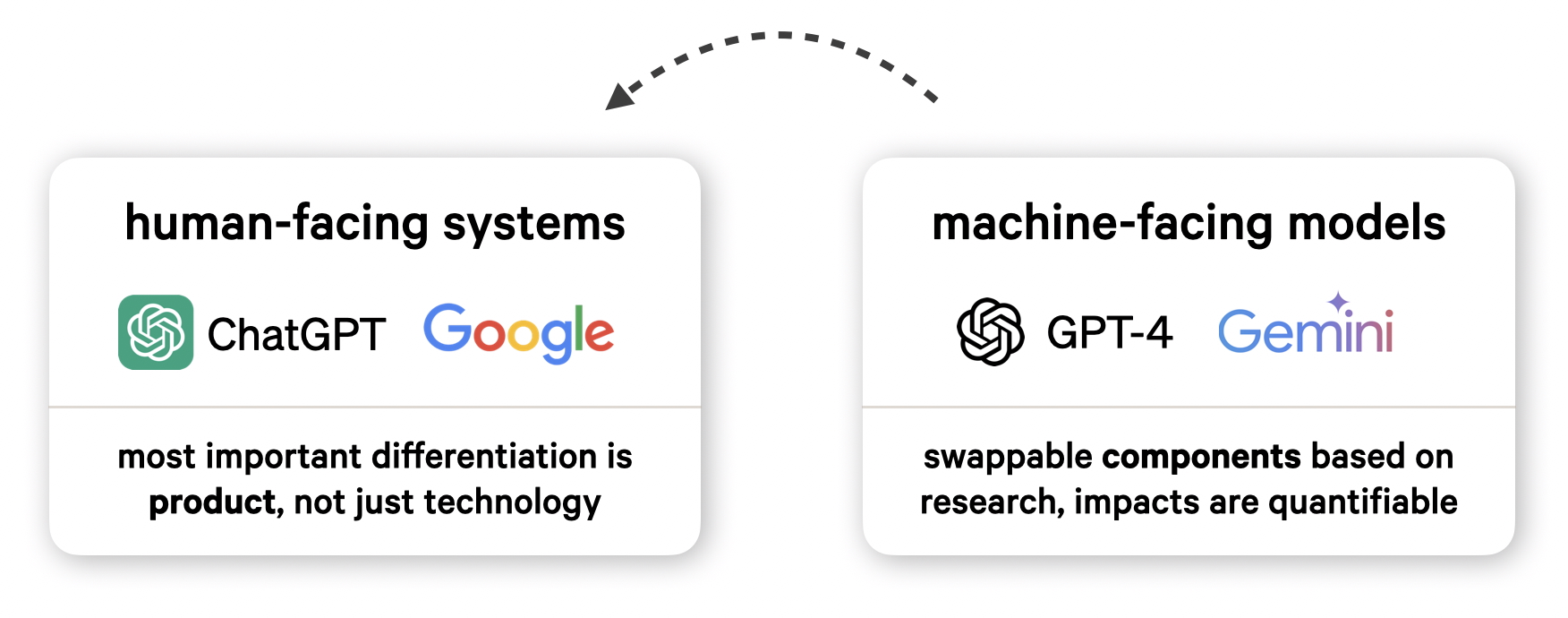
For human-facing systems, the most important differentiation is product, not just technology. This includes the user interface and user experience, how the product is marketed and the customizations implemented around the technology that powers it. We don’t fully know how ChatGPT works under the hood, but it likely implements extensive guardrails and custom logic around the models to provide the best possible user experience.
On the other hand, machine-facing models are swappable components based on publicly available academic research. Their impacts are quantifiable: for example, speed, accuracy, latency and cost. LLMs can be part of a product or process, and even swapped for entirely different approaches, without really changing the experience of the product itself.
Now the common pushback to this view of AI is, what about the data? Don’t OpenAI and Google have vast amounts of user data that allows them to build better technology? It’s important to differentiate between products and models again. User data is a big advantage for product, but not necessarily for the foundation for machine-facing tasks. If we’ve learned one thing from the recent advancements in Generative AI, it’s that you don’t need specific data to gain general knowledge. This is really what Large Language Models are all about. OpenAI may very well dominate the market of AI-powered chat assistants, but this doesn’t mean they’ll monopolize the underlying, swappable models and software components. In a way, this interoperability that’s largely enabled by open research and open-source software is the opposite of a monopoly.
With new developer tooling and the ability to compile smaller and private models at development time, companies now aren’t limited to third-party API providers that exploit economies of scale. If you’re trying to build a system that does a particular thing, you don’t need to transform your request into arbitrary language and call into the largest model that understands arbitrary language the best. The people developing those models are telling that story, but the rest of us aren’t obliged to believe them.
Resources
Source link
lol