
Table of Contents
In this tutorial, you will learn how to find outliers in data using a popular statistical technique called the Grubbs test.

In the world of data analytics, detecting anomalies is crucial for uncovering patterns that deviate from the norm. Whether it’s identifying fraudulent transactions, spotting manufacturing defects, or analyzing climate data, the ability to find outliers can significantly enhance decision-making processes. One of the robust statistical methods employed for this purpose is the Grubbs test. Named after Frank E. Grubbs, this test is specifically designed to detect a single outlier in a normally distributed dataset.
The Grubbs test works by comparing the maximum deviation of the data points from the mean relative to the standard deviation. It effectively identifies whether an extreme value within the dataset is indeed an outlier or just a part of the natural variation.
In this blog post, we will delve into the mechanics of the Grubbs test, its application in anomaly detection, and provide a practical guide on how to implement it using real-world data.
This lesson is the last of a 4-part series on Anomaly Detection:
- Credit Card Fraud Detection Using Spectral Clustering
- Predictive Maintenance Using Isolation Forest
- Build a Network Intrusion Detection System with Variational Autoencoders
- Anomaly Detection: How to Find Outliers Using the Grubbs Test (this tutorial)
To learn how to use the Grubbs test for outlier detection, just keep reading.
An outlier (Figure 1) is a data point that significantly differs from other observations in a dataset. It stands out due to its unusually high or low value compared to the rest of the data, which can indicate that it’s an anomaly, error, or something noteworthy. Outliers can arise for various reasons (e.g., measurement errors, data entry mistakes, or genuine but rare events). Regardless of their origin, identifying outliers is crucial because they can distort statistical analyses, leading to incorrect conclusions.
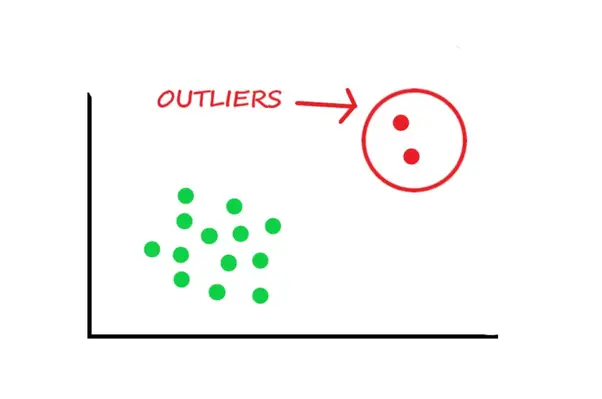
Outliers are important in fields (e.g., healthcare, and engineering), where detecting anomalies can have significant implications. For instance, in fraud detection, an outlier might represent an unusual transaction that warrants further investigation. In quality control, an outlier could indicate a defect in a manufacturing process. By understanding and identifying outliers, we can improve data quality, make better decisions, and gain deeper insights into the underlying patterns of the data. The Grubbs test is one of the statistical methods used to identify these outliers, ensuring that the integrity of the analysis is maintained.
The Grubbs test is a statistical method used to identify outliers in a normally distributed dataset. It is particularly useful when you suspect that a single data point is significantly different from the rest of the data. Further, one should first verify that a normal distribution can reasonably approximate the data before applying the Grubbs test.
The Grubbs test evaluates whether the most extreme value in the dataset deviates significantly from the mean of the rest of the data. This involves comparing the largest deviation from the mean, normalized by the standard deviation, against a critical value.
Performing the Grubbs test involves the following steps.
Formulating the Hypotheses
Formulating the hypotheses is a crucial step in statistical testing, including the Grubbs test for outlier detection. Hypotheses provide a framework for making decisions based on statistical evidence. In the context of the Grubbs test, we define two competing hypotheses (Figure 2): the null hypothesis  and the alternative hypothesis
and the alternative hypothesis  .
.

Null Hypothesis
The null hypothesis () represents a statement of no effect or no difference. It is the hypothesis that there is no significant outlier in the dataset. Essentially, assumes that all data points belong to the same distribution and that none of them are extreme enough to be considered outliers.
Mathematically, the null hypothesis for the Grubbs test can be stated as:

Alternative Hypothesis
The alternative hypothesis () represents a statement that contradicts the null hypothesis. It is the hypothesis that there is at least one significant outlier in the dataset. If the data provide sufficient evidence against , then we reject in favor of .
For the Grubbs test, the alternative hypothesis can be stated as:

Calculate the Test Statistic
Calculating the test statistic helps us quantify how extreme the most distant data point is compared to the rest of the data. The Grubbs test statistic ( ) is designed to measure the largest standardized deviation from the mean. It is given by the formula:
) is designed to measure the largest standardized deviation from the mean. It is given by the formula:
}{s}")
where:
Determining the Critical Value with t-Distribution
The t-distribution (Figure 3), also known as Student’s t-distribution, is a probability distribution that is symmetric and bell-shaped like the normal distribution but has heavier tails. This distribution is particularly useful when dealing with small sample sizes or when the population standard deviation is unknown.
Key Characteristics of the t-Distribution
- Degrees of Freedom: The shape of the t-distribution is determined by the degrees of freedom, which are typically the sample size minus one (
 ). As the degrees of freedom increase, the t-distribution approaches the normal distribution.
). As the degrees of freedom increase, the t-distribution approaches the normal distribution. - Heavier Tails: Compared to the normal distribution, the t-distribution has thicker tails, meaning it gives more weight to extreme values. This characteristic accounts for the increased variability expected in smaller samples.
- Symmetry: Like the normal distribution, the t-distribution is symmetric around its mean, which is zero.
In the context of the Grubbs test for outlier detection, the t-distribution is used to determine the critical value for the test statistic. A critical value allows us to compare the calculated test statistic to a threshold to decide whether an outlier is present. The critical value is essentially a threshold that defines the boundary for determining whether a data point is an outlier.
If the test statistic exceeds this critical value (Figure 4), we reject the null hypothesis and conclude that there is an outlier in the dataset. Conversely, if is less than or equal to the critical value, we do not reject .
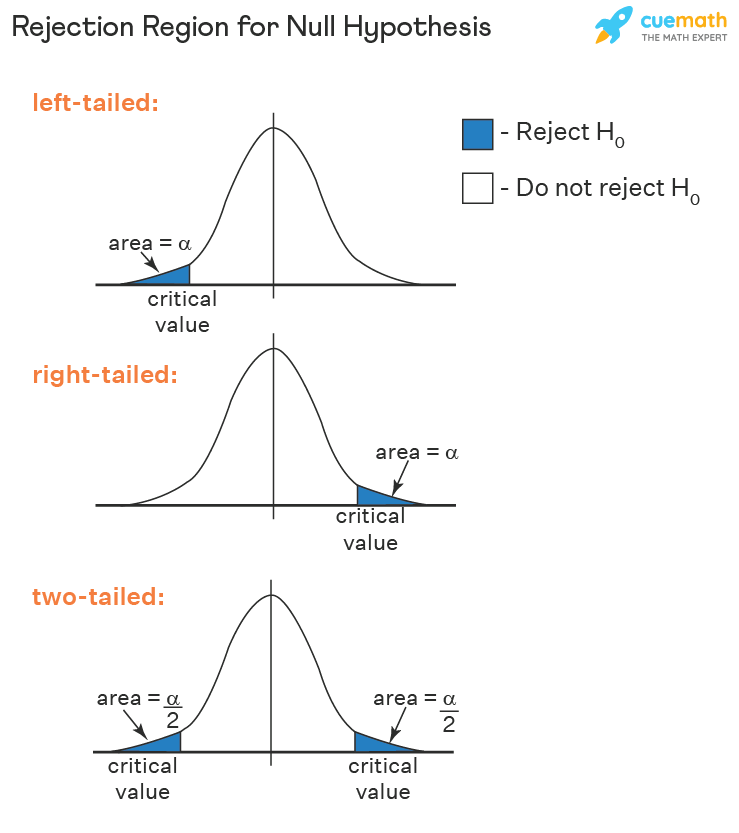
The critical value for the Grubbs test  for a “two-tailed” distribution (Figure 4, bottom plot) is calculated using the following formula:
for a “two-tailed” distribution (Figure 4, bottom plot) is calculated using the following formula:
 sqrt{t^2_{(alpha / (2n), n-2)}}}{sqrt{n} sqrt{n-2 + t^2_{(alpha / (2n), n-2)}}}")
where:
For a “left-tailed” or “right-tailed” Grubbs test (Figure 4, top and middle plots), the critical value can be calculated using a similar formula:
 sqrt{t^2_{(alpha / (n), n-2)}}}{sqrt{n} sqrt{n-2 + t^2_{(alpha / (n), n-2)}}}")
where instead of using , n-2)}") , we use
, we use , n-2)}") as the critical value from the
as the critical value from the  -distribution.
-distribution.
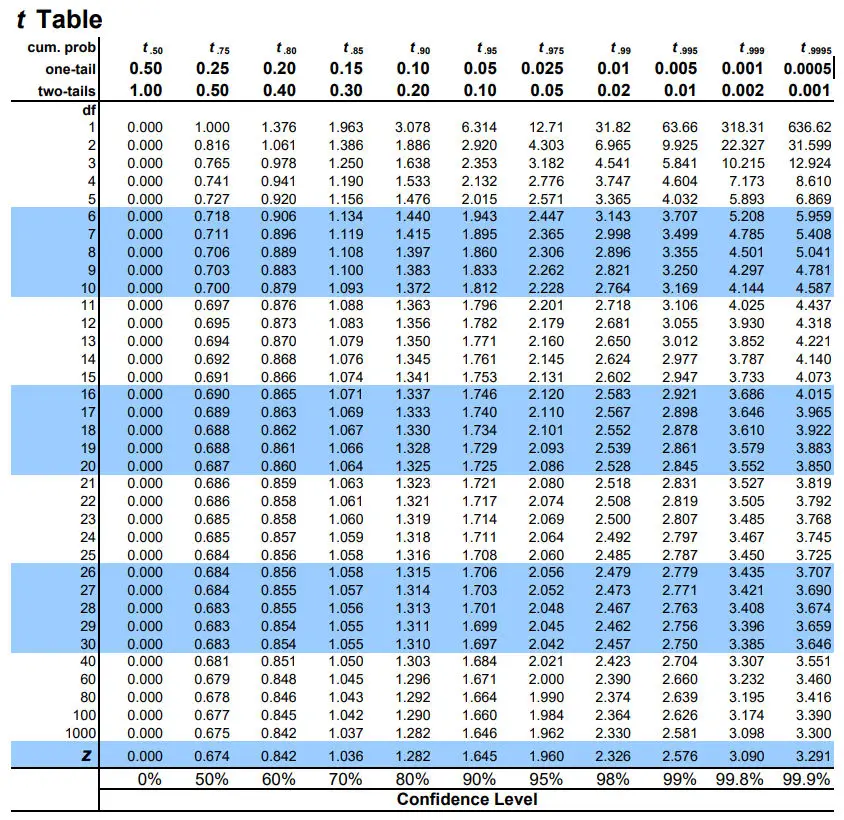
Note: We need to use statistical tables (Table 1) or software (e.g., Python or R) to find the critical value from the -distribution for the chosen  and degrees of freedom (
and degrees of freedom ( ).
).
In this section, we will see how to perform the Grubbs test in Python for sample datasets with small sample sizes. We will use the outliers package that has a predefined implementation of the Grubbs test for the left-, right-, and two-tailed distributions. We will install the outliers package via pip install outlier_utils.
Left-Tailed Grubbs Test
The left-tailed Grubbs test is a variation of the traditional Grubbs test, specifically designed to detect a single outlier that is significantly lower than the other values in a dataset (Figure 4, top plot). While the standard Grubbs test can identify both high and low outliers, the left-tailed version focuses exclusively on identifying values that are unusually small compared to the rest of the data.
The following code snippet uses smirnov_grubbs.min_test_indices() from the outliers package to obtain the outlier on the left side of the distribution.
import numpy as np
from outliers import smirnov_grubbs as grubbs
# define sample data
data1 = np.array([20, 21, 26, 24, 29,
22, 21, 50, 28, 27, 5])
# perform min Grubbs' test
data1_without_outlier = grubbs.min_test(data1, alpha=.05)
print(f"After removing left outlier(s) in {data1} is : ", data1_without_outlier)
# define sample data
data2 = np.array([20, 21, 26, 24, 29,
22, 21, 30, 28, 27, 5])
# perform min Grubbs' test
data2_without_outlier = grubbs.min_test(data2, alpha=.05)
print(f"After removing left outlier(s) in {data2} is : ", data2_without_outlier)
After removing left outlier(s) in [20 21 26 24 29 22 21 50 28 27 5] is : [20 21 26 24 29 22 21 50 28 27 5] After removing left outlier(s) in [20 21 26 24 29 22 21 30 28 27 5] is : [20 21 26 24 29 22 21 30 28 27]
This Python code demonstrates how to detect and remove left-sided outliers from datasets using the Grubbs test provided by the smirnov_grubbs module. On Lines 1 and 2, we import the necessary libraries, numpy for numerical operations and smirnov_grubbs for the Grubbs test. Lines 5 and 6 define the first sample dataset, data1, which includes a potential outlier. On Lines 10 and 11, we perform the left-tailed Grubbs test on data1 to detect and remove any low outliers, printing the dataset after the outlier removal.
Similarly, Lines 15 and 16 define the second sample dataset, data2. On Lines 20 and 21, we again apply the left-tailed Grubbs test to data2 to identify and remove any left outliers and then print the resulting dataset. This process helps us clean the data by removing values that are significantly lower than the others, ensuring more accurate analysis.
The output of the code shows the result of applying the left-tailed Grubbs test to each dataset to detect and remove low outliers.
- For the first dataset,
[20, 21, 26, 24, 29, 22, 21, 50, 28, 27, 5], the test does not identify any significant low outlier, so the dataset remains unchanged. - In contrast, for the second dataset,
[20, 21, 26, 24, 29, 22, 21, 30, 28, 27, 5], the test detects the value5as a low outlier and removes it, resulting in the updated dataset[20, 21, 26, 24, 29, 22, 21, 30, 28, 27].
Thus, this process helps clean the data by eliminating extreme values that could skew the analysis.
Right-Tailed Grubbs Test
Similar to the left-tailed Grubbs test, the right-tailed Grubbs test is used to detect a single outlier that is significantly larger than the other values in a dataset (Figure 4, middle plot).
The following code snippet uses smirnov_grubbs.max_test_indices() from the outliers package to get the outlier on the right side of the distribution.
import numpy as np
from outliers import smirnov_grubbs as grubbs
# define sample data
data1 = np.array([20, 21, 26, 24, 29,
22, 21, 50, 28, 27, 5])
# perform max Grubbs' test
data1_without_outlier = grubbs.max_test(data1, alpha=.05)
print(f"After removing right outlier(s) in {data1} is : ", data1_without_outlier)
# define sample data
data2 = np.array([20, 21, 26, 24, 29,
22, 21, 30, 28, 27, 5])
# perform max Grubbs' test
data2_without_outlier = grubbs.max_test(data2, alpha=.05)
print(f"After removing right outlier(s) in {data2} is : ", data2_without_outlier)
Output:
After removing right outlier(s) in [20 21 26 24 29 22 21 50 28 27 5] is : [20 21 26 24 29 22 21 28 27 5] After removing right outlier(s) in [20 21 26 24 29 22 21 30 28 27 5] is : [20 21 26 24 29 22 21 30 28 27 5]
The output of the code shows the result of applying the right-tailed Grubbs test to each dataset to detect and remove low outliers.
- For the first dataset,
[20, 21, 26, 24, 29, 22, 21, 50, 28, 27, 5], the test detects the value50as a high outlier and removes it, resulting in the updated dataset[20, 21, 26, 24, 29, 22, 21, 28, 27, 5]. - In contrast, for the second dataset,
[20, 21, 26, 24, 29, 22, 21, 30, 28, 27, 5], the test does not identify any significant low outlier, so the dataset remains unchanged.
Two-Tailed Grubbs Test
The two-tailed Grubbs test (Figure 4, bottom plot) is designed to identify both high and low outliers (as discussed in the theory section). This test is an extension of the original Grubbs test, which can be used to find a single outlier that significantly deviates from the mean of the dataset. However, it does so on both ends of the distribution simultaneously.
The following code snippet uses smirnov_grubbs.test() from the outliers package to get the outlier on the right side of the distribution.
import numpy as np
from outliers import smirnov_grubbs as grubbs
# define sample data
data1 = np.array([20, 21, 26, 24, 29,
22, 21, 55, 28, 27, -1])
# perform two-sided Grubbs' test
data1_without_outlier = grubbs.test(data1, alpha=.05)
print(f"After removing outliers in {data1} is : ", data1_without_outlier)
# define sample data
data2 = np.array([20, 21, 26, 24, 29,
22, 21, 30, 28, 27, 5])
# perform two-sided Grubbs' test
data2_without_outlier = grubbs.test(data2, alpha=.05)
print(f"After removing outliers in {data2} is : ", data2_without_outlier)
After removing outliers in [20 21 26 24 29 22 21 55 28 27 -1] is : [20 21 26 24 29 22 21 28 27] After removing outliers in [20 21 26 24 29 22 21 30 28 27 5] is : [20 21 26 24 29 22 21 30 28 27]
The output of the code shows the result of applying the two-tailed Grubbs test to each dataset to detect and remove low outliers.
- For the first dataset,
[20, 21, 26, 24, 29, 22, 21, 55, 28, 27, -1], the test detects the values55and-1as two outliers and removes them, resulting in the updated dataset[20, 21, 26, 24, 29, 22, 21, 28, 27]. - In contrast, for the second dataset,
[20, 21, 26, 24, 29, 22, 21, 30, 28, 27, 5], the test detects the value5as the only outlier and removes it, resulting in the updated dataset[20, 21, 26, 24, 29, 22, 21, 30, 28, 27].
In this blog post, we delve into the essential task of identifying anomalies within datasets, a critical step for improving data integrity and analysis accuracy. We start by defining what an outlier is and explain its importance in various fields (e.g., finance, healthcare, and quality control). Understanding outliers helps in enhancing decision-making processes by identifying irregularities that could indicate significant events or errors.
The core of the blog post focuses on the Grubbs test, a powerful statistical method for detecting outliers in normally distributed data. We provide detailed steps on how to formulate hypotheses, calculate the test statistic, and determine the critical value using the t-distribution. We explain the significance of both the null and alternative hypotheses, and cover different variations of the Grubbs test, including left-tailed, right-tailed, and two-tailed tests, each tailored to detect specific types of outliers.
By the end of the post, readers will have a comprehensive understanding of how to apply the Grubbs test to their datasets, effectively identifying and addressing outliers to maintain data accuracy.
Citation Information
Mangla, P. “Anomaly Detection: How to Find Outliers Using the Grubbs Test,” PyImageSearch, P. Chugh, S. Huot, and P. Thakur, eds., 2025, https://pyimg.co/a5mlu
@incollection{Mangla_2025_anomaly-detection-find-outliers-using-grubbs-test,
author = {Puneet Mangla},
title = {{Anomaly Detection: How to Find Outliers Using the Grubbs Test}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Piyush Thakur},
year = {2025},
url = {https://pyimg.co/a5mlu},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.
Source link
lol