
Image labeling or image annotation is the cornerstone of computer vision. It is the process of assigning meaningful labels or annotations to image data to enable computer vision models to learn patterns and make predictions. Whether it is object detection, image classification, or image segmentation, accurate image labels provide the necessary context so that models can effectively interpret image data.
Labeling holds the most significant role in the entire computer vision model development process as high-quality labels can increase the robustness of machine learning (ML) models. Poorly labeled or inconsistent data is the main source of noise in the ML training data that compels the model to make inaccurate predictions and affects its generalization capability for real-world data. If you want your model to learn meaningful patterns, your labels or annotations need to be precise. Moreover, these precise labels can help reduce the need for extensive fine-tuning and can save you both time and money spent on computational resources.
In this article, you will learn about some of the essential best practices for image labeling that can help you improve your computer vision model accuracy. Also, note that the words “labels” and “annotations” might be used interchangeably throughout the article.
Why Accurate Image Labeling is Crucial for Model Performance?
Accurate image labeling is a non-negotiable requirement for effective model training and validation. During the data labeling process, you need to accurately label the necessary features in a dataset as these labels serve as ground truth and guide the models during the entire learning process. This precise annotation helps models to identify and generalize relevant patterns and improves the performance of the model on the new unseen dataset. On the other hand, if the data is poorly annotated, the model tries to learn the noise and irrelevant patterns from the data which results in degraded training efficiency and validation metrics. While noise is one thing in poorly annotated data, mislabeling is another major issue due to which models struggle in differentiating key features. For example, if some “car” objects are labeled as “airplanes” then the models might have a hard time differentiating the features of cars and airplanes.
Real-World Applications Where Accurate Labels Are Critical
While accurate labeling and annotation are crucial for all real-world applications (no exceptions), some of the high-stakes applications in which the quality of labels is critical are as follows:
- Autonomous Vehicles: Autonomous vehicles are by far the best application of object detection and image segmentation. These systems rely on highly accurate labels to identify pedestrians, traffic signals, and obstacles. A slight error in labeling can lead to catastrophic failures including harm to human life.
- Healthcare Diagnostics: Medical imaging models like cancer cell detection, disease classification using X-ray images, etc. rely on correct annotations to detect diseases. If the data is poorly labeled for these use cases, it can lead to incorrect diagnostics and can endanger patient safety.
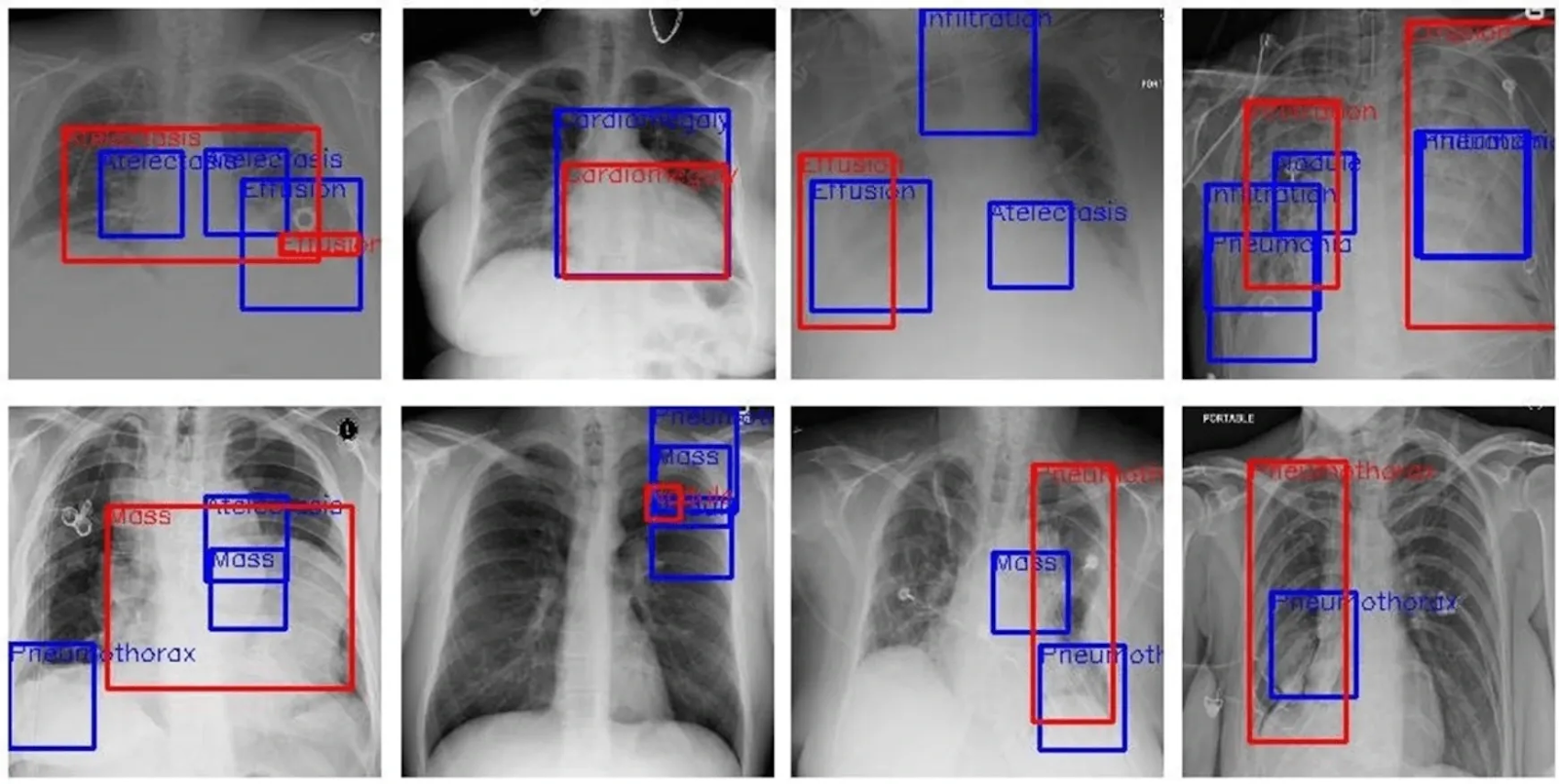
- Retail and E-commerce: Most retail and e-commerce applications now utilize visual search engines to filter the products of users’ needs quickly. These visual search engines require accurately labeled product images to ensure that users find the right items efficiently. If image labeling somehow results in mislabeled classes of products, it can negatively impact the user experience and revenue.

- Agriculture: Computer vision in agriculture is one of the highly focused areas these days. Satellite and drone images are being used to monitor crop health and diagnose plant diseases. If the data is wrongly labeled, it can lead to inaccurate yield predictions and can potentially cost a lot of money to farmers.

To sum up. From autonomous vehicles identifying road signs to healthcare systems detecting anomalies in medical scans, the quality of image labeling can directly impact the model’s performance and reliability.
Consequences of Poorly Labeled Data
While good labeling can enhance the effectiveness of overall computer vision solutions, poorly labeled data can have far-reaching consequences. Some of the most significant consequences of poorly labeled data are as follows:
- Model Performance Degradation: Erroneous and inconsistent labels pose a significant challenge as the model learns patterns that reflect noise or inaccuracies in the training data rather than meaningful relationships. It can degrade the model’s real-world performance. For instance, if labels are mixed up or incorrect, the model’s predictions might align with those errors, making them unreliable or unusable for the final application. This inconsistent data can sometimes result in overfitting where the model performs well on training data but poorly on new data.
- Bias: Labels are usually created by humans (now with automated tools as well) so the problem of mislabeling and underrepresentation of certain classes can skew the training data. This can lead to biased prediction and degradation of user’s trust in the technology.
- Resource Wastage: training the models on the wrongly labeled data often leads to computational and human resources wastage as engineers might need additional cycles for retraining and data cleaning.
Key Challenges in Image Labeling
While image labeling is a critical task for computer vision models, it comes with its own set of challenges. These challenges can compromise the quality of the labeled dataset and ultimately affect the performance of the machine-learning models. Let’s take a closer look at some of the most significant challenges in the labeling process.
Subjectivity in Interpreting Image Content
For real-world computer vision use cases, there is often a significant amount of data (possibly in hundreds of thousands of examples) that needs labeling. It is nearly impossible for a single person to annotate all these images. This is the reason why annotation task is often distributed among team members or outsourced using various platforms like Amazon Mechanical Turk or Appen. As different labelers get involved in the task, the involvement of subjectivity becomes higher as different annotators can perceive and label the same image type differently based on their personal biases or understanding.
For example, in an image of a simple street, some annotators might focus on labeling people, while others can prioritize labeling objects like cars and traffic lights. Moreover, sometimes even with clear guidelines, subjectivity can persist due to differences in annotators’ knowledge, cultural familiarity, etc. For example, an annotator unfamiliar with Chinese traditions might label an image of a traditional Chinese wedding as a ‘party,’ as he might not be able to recognize the specific cultural details that identify it as a wedding. This type of subjectivity can lead to inconsistent annotations and noisy training data, ultimately affecting the model’s performance.
Lack of Domain Expertise Among Annotators
As you might have understood by now annotation is not something that can be taken lightly in the model development lifecycle. This is the reason why it should be done by professionals with some idea about the use case they are about to work on. In many specialized fields like healthcare or satellite imagery, annotators with limited or without any domain expertise often struggle to label images accurately.
For example, labeling medical images requires knowledge of anatomy and pathology, while labeling satellite images requires an understanding of geographical features. If the annotators lack such expertise they might not be able to correctly mark the required objects in the images leading to inaccurate dataset generation.
Balancing Speed and Quality During Labeling
While working with large datasets, striking a balance between annotation speed and quality is a big challenge. Manually labeling large datasets can be really time-consuming and expensive as it might require human resources and some other specialized annotation tools. While automated image annotation software and tools can speed up the labeling process, they often lead to higher costs and affect the annotation quality and consistency a bit. On the other hand, meticulous labeling processes can lead to high quality but can be time-consuming and resource-intensive.
Handling Edge Cases and Ambiguous Images
Most of the time during the labeling process, you might find some edge cases and ambiguous images present in the dataset. These images usually do not fit in the predefined categories or contain overlapping labels. For example, an image of a partially visible object or an object blending with its background can confuse annotators. Handling these kinds of ambiguities is very challenging and leads to inconsistencies in the dataset and makes it harder for models to generalize effectively.
Apart from these major challenges, the image labeling process is also affected by data privacy and security issues as some datasets might require the secure handling of images. Annotators need to adhere to privacy regulations like GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act). For example, if some images contain personally identifiable information (PII), then annotators should either identify and flag the privacy violations or they must follow a specific guideline on how to handle these images. Moreover, maintaining the scalability and cost can be challenging factors while labeling large datasets.
Overlapping or Inconsistent Labels
For some of the cases, especially in the image segmentation tasks, the boundaries of objects can sometimes be overlapping or inconsistent. For these cases, annotators may assign overlapping or inconsistent labels when the boundaries between classes are unclear, resulting in a noisy dataset.

For example, in the above image the boundaries of “kite” and “person” are overlapping. In this case, if you do not have strict guidelines for annotations, the resultant data can be ambiguous.
Missing Annotations for Relevant Objects or Features
Sometimes there are observed cases where objects or features in images may go unlabeled due to oversight or lack of clear instructions. After all the annotations are done by humans, there is of course a little margin or error. However, these missing annotations can cause models to ignore these aspects during training and often lead to class imbalance and model overfitting issues.
Essential Best Practices for Image Labeling
Next, you will see a list of best practices that can help you get the most out of your image labeling process.
Setting Up Effective Labeling Guidelines
Creating effective labeling guidelines is really important for successful image annotation projects. As discussed in the first and second challenges, including multiple people in the annotation can lead to subjectivity and bias in the annotation process. Not providing explicit instructions to annotators is the primary reason why they interpret the task differently and produce different annotations for the same types of images. Defining clear labeling guidelines helps annotators to align on the same project objective and expectations. Moreover, these comprehensive guidelines can ensure that annotators apply the same criteria for annotation even when dealing with complex, ambiguous, and domain-specific images.
The next plausible question that you should be asking is, what one must define in the labeling guidelines so that the resultant annotations can be of good quality. So, here is a list of components in an image labeling guideline:
- Clear Definitions for Each Label/Class: A good guideline should provide a precise definition of each label or class to be assigned to an image. For example, if annotators are labeling vehicles in traffic images, the guideline should clarify whether motorcycles, bicycles, and buses are included under “vehicles” or treated as separate classes. This clear definition reduces the issues like subjectivity as each annotator will follow the same set of instructions and the produced annotations will be uniform.
- Examples of Correct and Incorrect Labeling: While defining the clear objectives and class labels is necessary, including examples of both correct and incorrect labeling practices can make the guidelines intuitive and easier to follow. Showing the annotators what an accurate image label looks like and highlighting common mistakes to avoid increases the chance of producing high-quality annotations.
- Guidance on Handling Uncertain or Edge Cases: As described earlier, almost every dataset contains ambiguous or edge-case images. Guidelines should effectively define how to handle edge cases such as objects with unclear boundaries, overlapping categories, or partial visibility. One good example of this solution is specifying the “not sure” category for ambiguous cases or flagging such images for review by a subject matter expert.
Once a guideline has these components, annotators will have a clear objective to follow. But wait, for real-world projects, it is often observed that the requirements change as the project progresses. In this case, keeping the guidelines static throughout the entire project lifecycle can be harmful to the project. These guidelines should always be dynamic and should be ready for change. As annotators encounter edge cases or provide feedback, the guidelines should be updated to reflect new insights and challenges. This iterative refinement of the instructions ensures that the labeling process remains accurate and efficient as the project evolves.
Data Quality and Consistency in Labeling
While high data quality and consistent labeling across the dataset are crucial, achieving them can be a little challenging if you do not follow and standardized approach, proper guidelines, and efficient tools and software. In this section, let’s discuss the strategies to ensure uniformity and reliability in image labeling, focusing on manual, tool-based, and automated approaches.
Strategies to Maintain Uniformity Across Annotators
Let’s start with discussing the strategies that can help annotators to produce uniform and trustworthy labels.
Regular Quality Checks and Inter-Annotator Agreement Metrics
Regularly conducting quality checks ensures that the produced annotations meet project standards. While proper guidelines can lower the subjectivity up to a certain extent, they do not guarantee the complete resolution of subjectivity. This is where Inter Annotator Agreement (IAA) metrics come into the picture. These metrics measure the consistency between different annotators among all categories of the dataset. IAA can be used per task, between annotators, between labels, or on the entire dataset. Here are some of the most common IAA metrics used across industries for producing standardized annotations:
- Cohen’s Kappa: This metric measures the agreement between two annotators on qualitative categories while accounting for the agreement that might happen by chance. It is given by the formula: Κ = (po − pe) / (1 − pe)
Here:
po: Observed agreement (proportion of instances where both annotators agree).
pe: Expected agreement by chance (calculated based on the marginal totals).
The value of K ranges from 0 to 1 where 0 represents the “Poor Agreement” and 1 represents the “Almost Perfect Agreement”.
- Krippendorff’s Alpha: This metric measures the reliability of the agreement between annotators and handles various data types (nominal, ordinal, interval, or ratio). It also accounts for missing data and reliability for datasets with more than two annotators. It is given by the formula: a = 1 − (Do / De)
Here:
Do: Observed disagreement.
De: Expected disagreement by chance.
- Fleiss’ Kappa: This metric is the extension of Cohen’s Kappa as it measures agreement among multiple annotators. It assesses whether annotators classify items into categories more consistently than would be expected by chance.
- Percent Agreement: This is one of the simplest IAA metrics that measures the proportion of items on which all annotators agree, without accounting for chance. It is given by the following formula:
Percent Agreement = (Number of agreements / Total number of items) × 100
Once the discrepancies are identified through IAA analysis, training sessions can be conducted to align annotators on best practices, reducing inconsistencies in the dataset.
Use of Tools to Enforce Consistency
Labeling images manually is a time-consuming task. As this task is carried out quite often for computer vision use cases, different organizations have heavily invested in developing labeling tools that can reduce labeling time while increasing productivity. Some of the most common tools include DagsHub, LabelBox, Label Studio, SuperAnnotate, Shaip, etc.
Leveraging tools like DagsHub can significantly enhance the consistency of labeled datasets. DagsHub enables collaborative annotation workflows, version control, and centralized guideline management. With DagsHub, annotators can refer to shared guidelines, review each other’s work, and ensure consistency through peer validation. Finally, it provides built-in metrics and visualization tools to help monitor annotation quality in real-time, making it easier to identify and address inconsistencies.
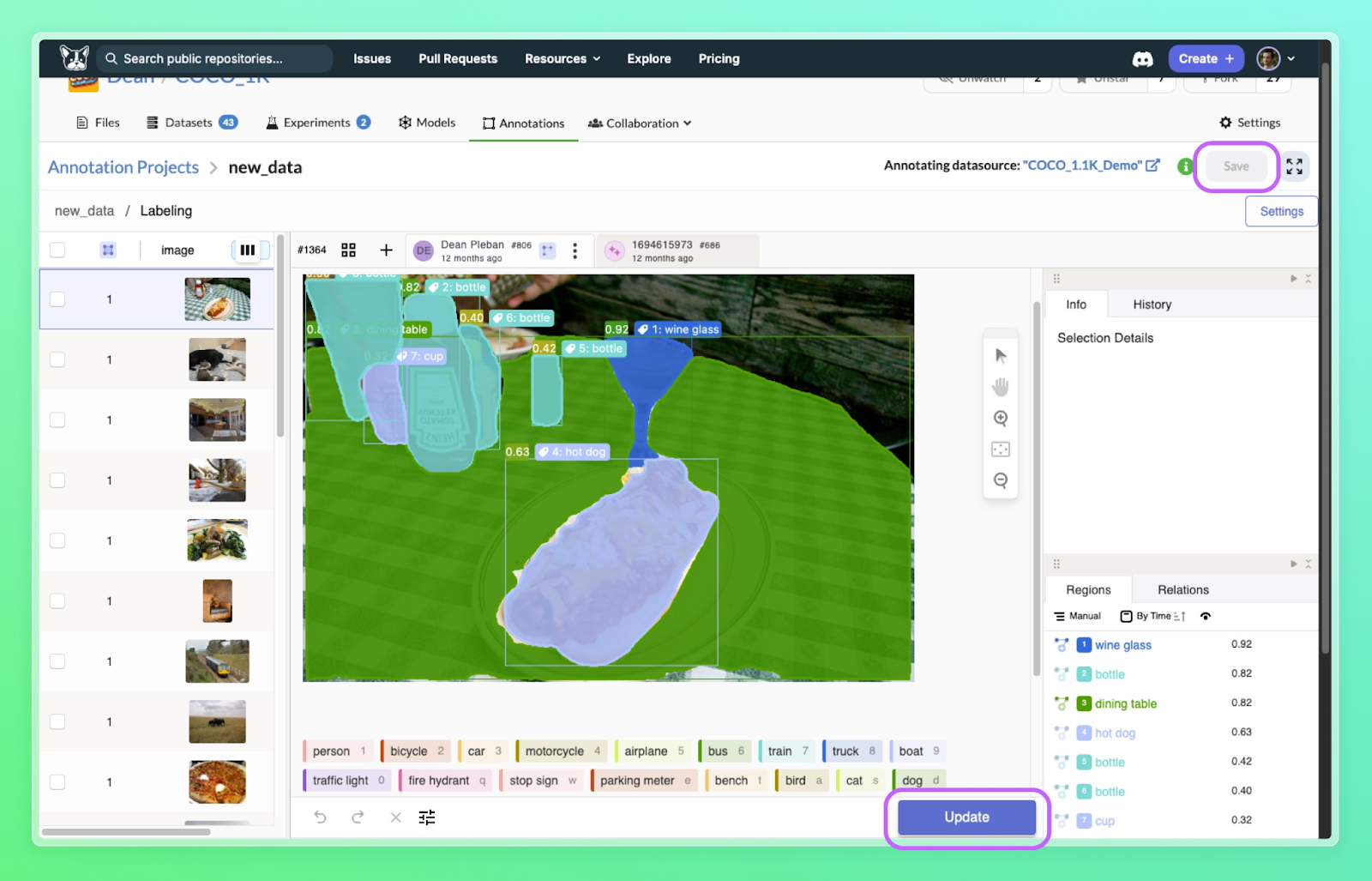
To learn more about the best data annotation tools available in the market, you can refer to this article.
Methods for Ensuring Data Diversity While Maintaining Quality
While consistency in annotation is critical, diversity in the data is equally important for producing robust annotations. You need to make sure that your dataset captures images for different scenarios, classes, and edge cases to prevent overfitting and enhance generalization. Here are the solutions you can try to maintain the label’s quality while ensuring diversity:
- Try to use stratified sampling to select images across different categories or conditions.
- Apply data augmentation techniques to the original dataset to introduce variety without altering label reliability.
- Regularly review underrepresented (minority) classes and scenarios to ensure balanced representation.
Role of Automation in Enhancing Consistency
Since the introduction of transformer-based models, the size of image datasets has increased a lot. Labeling these large datasets even with the help of annotation tools is a challenging task. But you need not worry, as for every problem there exists one or more solutions, for this scalability issue as well the development of automated annotation tools is getting some acceleration. There are two main technologies that are empowering these automation labeling tools:
- Semi-Supervised Learning: This technique combines the labeled and unlabeled data to improve consistency while reducing manual workload. In this technique, a model is trained on an initial labeled dataset. Once trained, the model can generate predictions for unlabeled data, which are then reviewed and refined by annotators. This way it automates and accelerates the labeling process.
- Active Learning: Active learning identifies the most informative samples—such as edge cases or images where the model is uncertain—for annotation. By focusing human efforts on challenging cases, active learning enhances dataset quality and consistency without wasting resources on straightforward samples.
The best part about this automation capability is that you might not have to implement these technologies on your own. Tools like DagsHub Data Engine come prebuilt with automated annotation capability for large-scale datasets.
Conclusion and Recommendations
After reading this article, you now know that even after being a straightforward approach, image labeling needs a lot of attention for generating high-quality data for computer vision model building. You have seen the importance of image labeling, the different challenges in effective labeling, and the best practices for effective image labeling.
As machine learning applications are becoming increasingly sophisticated, the demand for labeled data is growing in demand and scale. While there are traditional tools available for image labeling, innovative technologies such as active learning, model-assisted labeling, and collaborative tools are complementing these tools. With this evolving landscape, annotators, project managers, and data scientists must stay agile, continuously adopt new tools, and refine their processes to meet emerging challenges. To improve your annotation approach, especially for large-scale datasets, you can use the DagHub annotation tool. Refer to this detailed documentation to learn more about it.
Source link
lol