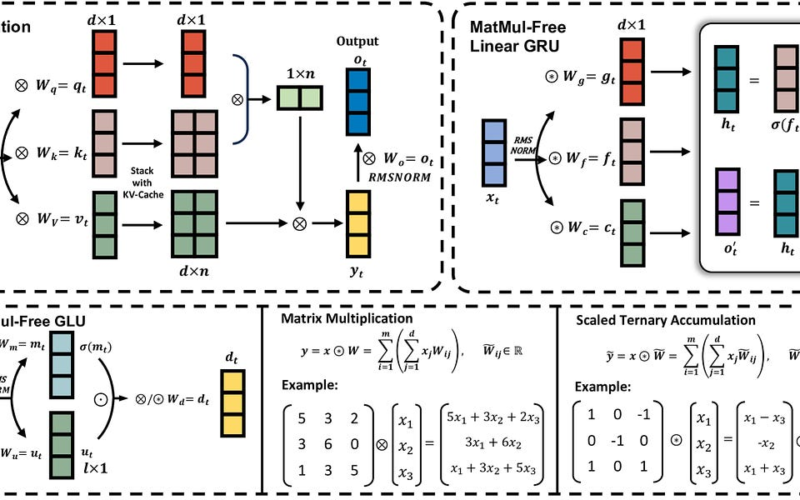
Can we build LLMs that perform on par with current state-of-the-art models while eliminating the computationally expensive matrix multiplication (MatMul) operations? This question challenges the core of neural network efficiency and scalability.
One of the top papers trending on AImodels.fyi investigates this and finds that the answer is “yes.” By replacing MatMul operations with ternary accumulations and optimized kernels, the authors aim to create models that are not only faster and more memory-efficient but also just as powerful.
Here’s an in-depth exploration of their findings and methodology centered around this pivotal question. You need to be a pro AImodels.fyi user to access this breakdown. Subscribe if you haven’t yet so you don’t miss out on this breakthrough.
Source link
lol