In the field of generative AI, latency and cost pose significant challenges. The commonly used large language models (LLMs) often process text sequentially, predicting one token at a time in an autoregressive manner. This approach can introduce delays, resulting in less-than-ideal user experiences. Additionally, the growing demand for AI-powered applications has led to a high volume of calls to these LLMs, potentially exceeding budget constraints and creating financial pressures for organizations.
This post presents a strategy for optimizing LLM-based applications. Given the increasing need for efficient and cost-effective AI solutions, we present a serverless read-through caching blueprint that uses repeated data patterns. With this cache, developers can effectively save and access similar prompts, thereby enhancing their systems’ efficiency and response times. The proposed cache solution uses Amazon OpenSearch Serverless and Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Solution overview
The cache in this solution acts as a buffer, intercepting prompts—requests to the LLM expressed in natural language—before they reach the main model. The semantic cache functions as a memory bank storing previously encountered similar prompts. It’s designed for efficiency and swiftly matching a user’s prompt with its closest semantic counterparts. However, in a practical cache system, it’s crucial to refine the definition of similarity. This refinement is necessary to strike a balance between two key factors: increasing cache hits and reducing cache collisions. A cache hit occurs when a requested prompt is found in the cache, meaning the system doesn’t need to send it to the LLM for a new generation. Conversely, a cache collision happens when multiple prompts are mapped to the same cache location due to similarities in their semantic features. To better understand these concepts, let’s examine a couple of examples.
Imagine a concierge AI assistant powered by an LLM, specifically designed for a travel company. It excels at providing personalized responses drawn from a pool of past interactions, making sure that each reply is relevant and tailored to travelers’ needs. Here, we might prioritize high recall, meaning we’d rather have more cached responses even if it occasionally leads to overlapping prompts.
Now, consider a different scenario: an AI assistant, designed to assist back desk agents at this travel company, uses an LLM to translate natural language queries into SQL commands. This enables the agents to generate reports from invoices and other financial data, applying filters such as dates and total amounts to streamline report creation. Precision is key here. We need every user request mapped accurately to its corresponding SQL command, leaving no room for error. In this case, we’d opt for a tighter similarity threshold, making sure that cache collisions are kept to an absolute minimum.
In essence, the read-through semantic cache isn’t just a go-between; it’s a strategic tool for optimizing system performance based on the specific demands of different applications. Whether it’s prioritizing recall for a chatbot or precision for a query parser, the adjustable similarity feature makes sure that the cache operates at peak efficiency, enhancing the overall user experience.
A semantic cache system operates at its core as a database storing numerical vector embeddings of text queries. Before being stored, each natural language query is transformed into a corresponding embedding vector. With Amazon Bedrock, you have the flexibility to select from various managed embedding models, including Amazon’s proprietary Amazon Titan embedding model or third-party alternatives like Cohere. These embedding models are specifically designed to map similar natural language queries to vector embeddings with comparable Euclidean distances, providing semantic similarity. With OpenSearch Serverless, you can establish a vector database suitable for setting up a robust cache system.
By harnessing these technologies, developers can build a semantic cache that efficiently stores and retrieves semantically related queries, improving the performance and responsiveness of their systems. In this post, we demonstrate how to use various AWS technologies to establish a serverless semantic cache system. This setup allows for quick lookups to retrieve available responses, bypassing the time-consuming LLM calls. The result is not only faster response times, but also a notable reduction in price.
The solution presented in this post can be deployed through an AWS CloudFormation template. It uses the following AWS services:
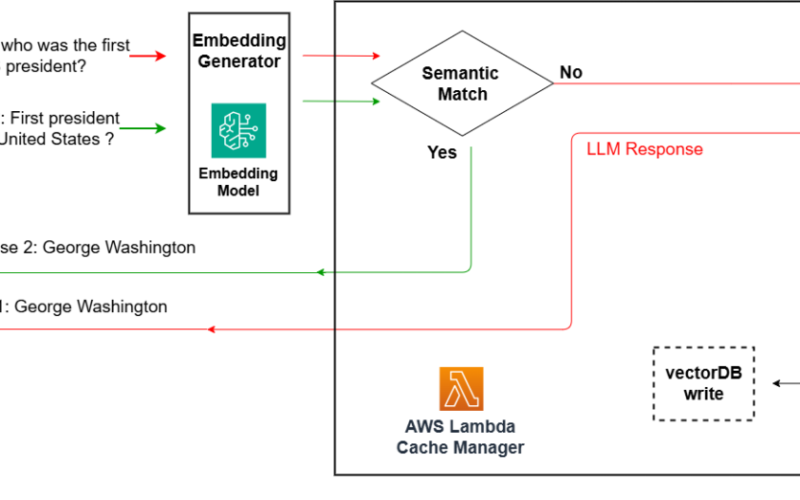
The following architecture shows a serverless read-through semantic cache pattern you can use to integrate into an LLM-based solution.
In this architecture, examples of cache miss and hit are shown in red and green, respectively. In this particular scenario, the client sends a query, which is then semantically compared to previously seen queries. The Lambda function, acting as the cache manager, prompts an LLM for a new generation due to a lack of cache hits given the similarity threshold. The new generation is then sent to the client and used to update the vector database. In the case of a cache hit (green path), the previously generated semantically similar query is sent to the client immediately.
For this short query, the following table summarizes the response latency using the test results of “Who was the first US president” queries, tested on Anthropic Claude V2.
| Query Under Test | Without Cache Hit | With Cache Hit |
|---|---|---|
| Who was the first US president? | 2 seconds | Under 0.5 seconds |
Prerequisites
Amazon Bedrock users need to request access to FMs before they are available for use. This is a one-time action and takes less than a minute. For this solution, you’ll need one of the embedding models such as Cohere Embed-English on Amazon Bedrock or Amazon Titan Text Embedding. For text generation, you can choose from Anthropic’s Claude models. For a complete list of text generation models, refer to Amazon Bedrock.

Deploy the solution
This solution entails setting up a Lambda layer that includes dependencies to interact with services like OpenSearch Serverless and Amazon Bedrock. A pre-built layer is compiled and added to a public Amazon Simple Storage Service (Amazon S3) prefix, available in the provided CloudFormation template. You have the option to build your own layer with other libraries; for more information, refer to the following GitHub repo.
You can deploy this solution with the required roles by using the provided template:![]()
This solution uses the following input parameters:
- Embedding model
- LLM
- Similarity threshold
After a successful deployment (which takes about 2 minutes), you can get your Lambda function name and start experimenting. You can find the Lambda function name on the Outputs tab of your CloudFormation stack, as shown in the following screenshot.

You can invoke the Lambda function from the Lambda console or through the AWS Command Line Interface (AWS CLI):
Your payload can have other options to control cache and generation as follows:
Test the solution
To test your cache using the Lambda console, open the Functions page. Navigate to the function you retrieved from the output of your stack. Set up a test event as illustrated in the following screenshot.

Upon a successful run, the result appears similar to the following screenshot.

Let’s try another experiment to take a closer look into the functioning of our cache. For this experiment, we use the Cohere embedding model on Amazon Bedrock and a similarity threshold of 0.75. We asked the following question, and it took about 15 seconds for the model to generate the complete response with Anthropic’s Claude V2:
Prompt: What are the potential long-term impacts of artificial intelligence and blockchain technology on the global financial industry?
Generation: Here are some potential long-term impacts of AI and blockchain on the global financial industry:
Automation of routine tasks – AI and machine learning can automate many routine financial tasks like loan processing, fraud detection, client onboarding etc. This could lead to lower operational costs and improved efficiency for financial firms.
Better data analytics and insights – AI can analyze large volumes of financial data more efficiently than humans. This can lead to better insights, personalized recommendations for clients and improved risk management by firms.
Improved trading and investment platforms – AI algorithms can potentially execute trades faster and more optimally than human traders. They can also enable robo-advisors that provide automated investment advice and portfolio management.
Enhanced security and fraud detection – Machine learning models can detect patterns in data to identify potential fraud, money laundering or cybersecurity threats. Blockchain provides a decentralized, encrypted record of transactions that is harder to tamper with.
When we tried these prompt variations, the cache system successfully returned the previously generated response (under 0.5 seconds):
Similar Prompt 1: What are the potential future implications of AI and blockchain on the worldwide financial sector?
Similar Prompt 2: Discuss the possible effects of artificial intelligence and blockchain advancements on the global finance landscape over the coming decades.
Let’s replace the term “financial sector” with “healthcare sector”; we expect no cache collision and new generation:
Prompt: Could you outline the future implications of AI and blockchain on the worldwide healthcare sector?
Generation: Here are some potential long-term impacts AI could have on the healthcare sector:
Personalized medicine – AI can analyze huge datasets about genetics, lifestyle, medical history etc. to provide personalized treatment plans tailored to each individual patient’s needs and risks. This could improve outcomes and reduce waste in the system.
Early disease detection – Algorithms are getting very good at analyzing medical images and data to identify potential diseases and conditions much earlier than human doctors. This could lead to earlier treatment and prevention of serious illness.
Reduced costs – AI has the potential to automate and streamline many processes in healthcare leading to greater efficiency and lower costs. For example, AI chatbots and virtual assistants could provide some basic services at a fraction of the cost of human staff.
The following table summarizes the query latency test results without and with cache hit tested on Anthropic’s Claude V2.
| Query Under Test | Without Cache Hit | With Cache Hit |
|---|---|---|
| Could you outline the future implications of AI and blockchain on the worldwide healthcare sector? | 15 seconds | Under 0.5 seconds |
In addition to latency, you can also save costs for your LLM system. Typically, embedding models are more cost-efficient than generation models. For example, Amazon Titan Text Embedding V2 costs $0.00002 per 1,000 input tokens, whereas Anthropic’s Claude V2 costs $0.008 per 1,000 input tokens and $0.024 for 1,000 output tokens. Even considering an additional cost from OpenSearch Service, depending on the scale of cache data, the cache system can be cost-efficient for many use cases.
Clean up
After you are done experimenting with the Lambda function, you can quickly delete all the resources you used to build this semantic cache, including your OpenSearch Serverless collection and Lambda function. To do so, locate your CloudFormation stack on the AWS CloudFormation console and delete it.
Make sure that the status of your stack changes from Delete in progress to Deleted.
Conclusion
In this post, we walked you through the process of setting up a serverless read-through semantic cache. By implementing the pattern outlined here, you can elevate the latency of your LLM-based applications while simultaneously optimizing costs and enriching user experience. Our solution allows for experimentation with embedding models of varying sizes, conveniently hosted on Amazon Bedrock. Moreover, it enables fine-tuning of similarity thresholds to strike the perfect balance between cache hit and cache collision rates. Embrace this approach to unlock enhanced efficiency and effectiveness within your projects.
For more information, refer to the Amazon Bedrock User Guide and Amazon OpenSearch Serverless Developer Guide.
About the Authors
 Kamran Razi is a Data Scientist at the Amazon Generative AI Innovation Center. With a passion for delivering cutting-edge generative AI solutions, Kamran helps customers unlock the full potential of AWS AI/ML services to solve real-world business challenges. Leveraging over a decade of experience in software development, he specializes in building AI-driven solutions, including chatbots, document processing, and retrieval-augmented generation (RAG) pipelines. Kamran holds a PhD in Electrical Engineering from Queen’s University.
Kamran Razi is a Data Scientist at the Amazon Generative AI Innovation Center. With a passion for delivering cutting-edge generative AI solutions, Kamran helps customers unlock the full potential of AWS AI/ML services to solve real-world business challenges. Leveraging over a decade of experience in software development, he specializes in building AI-driven solutions, including chatbots, document processing, and retrieval-augmented generation (RAG) pipelines. Kamran holds a PhD in Electrical Engineering from Queen’s University.
 Sungmin Hong is a Senior Applied Scientist at Amazon Generative AI Innovation Center where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds Ph.D. in Computer Science from New York University. Outside of work, Sungmin enjoys hiking, reading and cooking.
Sungmin Hong is a Senior Applied Scientist at Amazon Generative AI Innovation Center where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds Ph.D. in Computer Science from New York University. Outside of work, Sungmin enjoys hiking, reading and cooking.
 Yash Shah is a Science Manager in the AWS Generative AI Innovation Center. He and his team of applied scientists and machine learning engineers work on a range of machine learning use cases from healthcare, sports, automotive and manufacturing.
Yash Shah is a Science Manager in the AWS Generative AI Innovation Center. He and his team of applied scientists and machine learning engineers work on a range of machine learning use cases from healthcare, sports, automotive and manufacturing.
 Anila Joshi has more than a decade of experience building AI solutions. As a Senior Manager, Applied Science at AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and accelerate the adoption of AWS services with customers by helping customers ideate, identify, and implement secure generative AI solutions.
Anila Joshi has more than a decade of experience building AI solutions. As a Senior Manager, Applied Science at AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and accelerate the adoption of AWS services with customers by helping customers ideate, identify, and implement secure generative AI solutions.
Source link
lol