April 2024, what a month! My birthday, a new book release, spring is finally here, and four major open LLM releases: Mixtral, Meta AI’s Llama 3, Microsoft’s Phi-3, and Apple’s OpenELM.
This article reviews and discusses all four major transformer-based LLM model releases that have been happening in the last few weeks, followed by new research on reinforcement learning with human feedback methods for instruction finetuning using PPO and DPO algorithms.
1. How Good are Mixtral, Llama 3, and Phi-3?
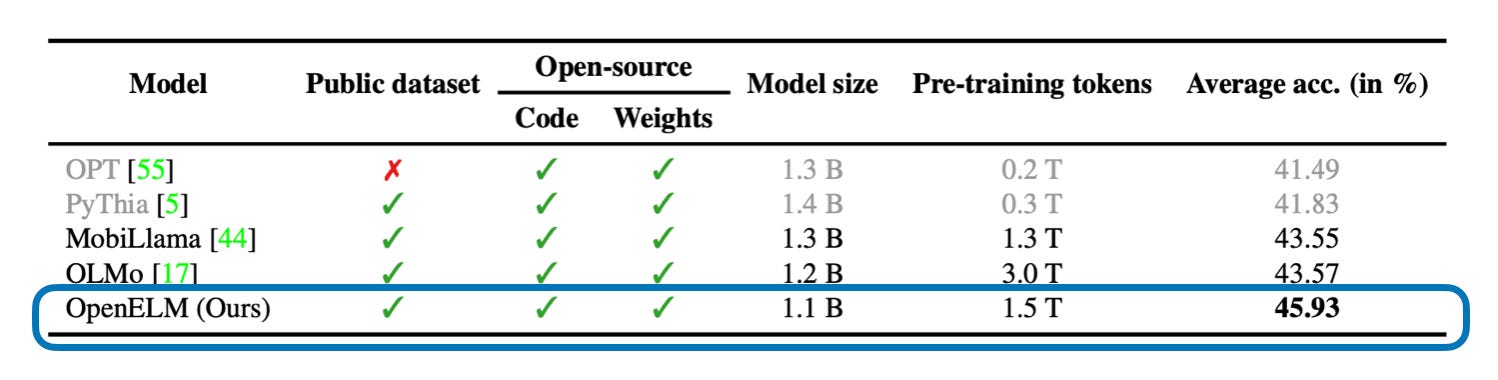
2. OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
3. Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
4. Other Interesting Research Papers In April
First, let’s start with the most prominent topic: the new major LLM releases this month. This section will briefly cover Mixtral, Llama 3, and Phi-3, which have been accompanied by short blog posts or short technical papers. The next section will cover Apple’s OpenELM in a bit more detail, which thankfully comes with a research paper that shares lots of interesting details.
Mixtral 8x22B is the latest mixture-of-experts (MoE) model by Mistral AI, which has been released under a permissive Apache 2.0 open-source license.
Similar to the Mixtral 8x7B released in January 2024, the key idea behind this model is to replace each feed-forward module in a transformer architecture with 8 expert layers. It’s going to be a relatively long article, so I am skipping the MoE explanations, but if you are interested, the Mixtral 8x7B section in an article I shared a few months ago is a bit more detailed:
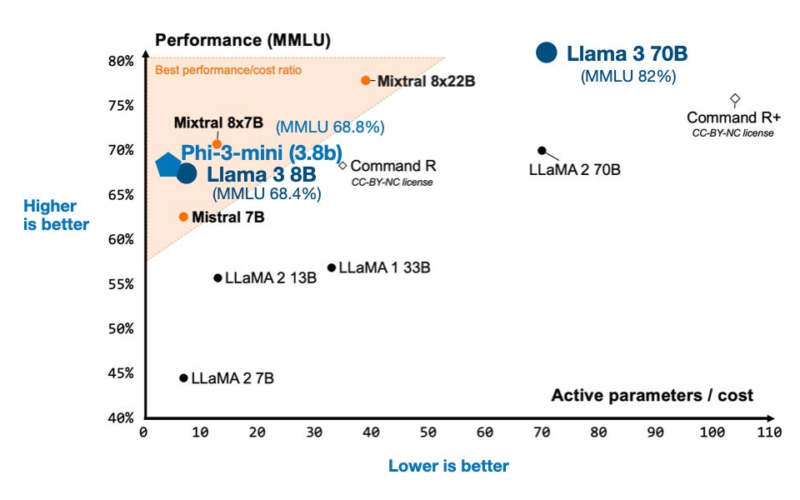
The perhaps most interesting plot from the Mixtral blog post, which compares Mixtral 8x22B to several LLMs on two axes: modeling performance on the popular Measuring Massive Multitask Language Understanding (MMLU) benchmark and active parameters (related to computational resource requirements).
Meta AI’s first Llama model release in February 2023 was a big breakthrough for openly available LLM and was a pivotal moment for open(-source) LLMs. So, naturally, everyone was excited about the Llama 2 release last year. Now, the Llama 3 models, which Meta AI has started to roll out, are similarly exciting.
While Meta is still training some of their largest models (e.g., the 400B variant), they released models in the familiar 8B and 70B size ranges. And they are good! Below, I added the MMLU scores from the official Llama 3 blog article to the Mixtral plot I shared earlier.
Overall, the Llama 3 architecture is almost identical to Llama 2. The main differences are the increased vocabulary size and the fact that Llama 3 also uses grouped-query attention for the smaller-sized model. If you are looking for a grouped-query attention explainer, I’ve written about it here:

Below are the configuration files used for implementing Llama 2 and Llama 3 in LitGPT, which help show the main differences at a glance.
Training data size
The main contributor to the substantially better performance compared to Llama 2 is the much larger dataset. Llama 3 was trained on 15 trillion tokens, as opposed to “only” 2 trillion for Llama 2.
This is a very interesting finding because, as the Llama 3 blog post notes, according to the Chinchilla scaling laws, the optimal amount of training data for an 8 billion parameter model is much smaller, approximately 200 billion tokens. Moreover, the authors of Llama 3 observed that both the 8 billion and 70 billion parameter models demonstrated log-linear improvements even at the 15 trillion scale. This suggests that we (that is, researchers in general) could further enhance the model with more training data beyond 15 trillion tokens.
Instruction finetuning and alignment
For instruction finetuning and alignment, researchers usually choose between using reinforcement learning with human feedback (RLHF) via proximal policy optimization (PPO) or the reward-model-free direct preference optimization (DPO). Interestingly, the Llama 3 researchers did not favor one over the other; they used both! (More on PPO and DPO in a later section.)
The Llama 3 blog post stated that a Llama 3 research paper would follow in the coming month, and I am looking forward to the additional details that will hopefully be shared in this article.
Just one week after the big Llama 2 release, Microsoft shared their new Phi-3 LLM. According to the benchmarks in the technical report, even the smallest Phi-3 model outperforms the Llama 3 8B model despite being less than half its size.
Notably, Phi-3, which is based on the Llama architecture, has been trained on 5x fewer tokens than Llama 3 (3.3 trillion instead of 15 trillion). Phi-3 even uses the same tokenizer with a vocabulary size of 32,064 as Llama 2, which is much smaller than the Llama 3 vocabulary size.
Also, Phi-3-mini has “only” 3.8 billion parameters, which is less than half the size of Llama 3 8B.
So, What is the secret sauce? According to the technical report, it’s dataset quality over quantity: “heavily filtered web data and synthetic data”.
The paper didn’t go into too much detail regarding the data curation, but it largely follows the recipe used for previous Phi models. I wrote more about Phi models a few months ago here:

As of this writing, people are still unsure whether Phi-3 is really as good as promised. For instance, many people I talked to noted that Phi-3 is much worse than Llama 3 for non-benchmark tasks.
Based on the three major releases described above, this has been an exceptional month for openly available LLMs. And I haven’t even talked about my favorite model, OpenELM, which is discussed in the next section.
Which model should we use in practice? I think all three models above are attractive for different reasons. Mixtral has a lower active-parameter count than Llama 3 70B but still maintains a pretty good performance level. Phi-3 3.8B may be very appealing for mobile devices; according to the authors, a quantized version of it can run on an iPhone 14. And Llama 3 8B might be the most interesting all-rounder for fine-tuning since it can be comfortably fine-tuned on a single GPU when using LoRA.
OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework is the latest LLM model suite and paper shared by researchers at Apple, aiming to provide small LLMs for deployment on mobile devices.
Similar to the OLMo, it’s refreshing to see an LLM paper that shares details discussing the architecture, training methods, and training data.
Let’s start with the most interesting tidbits:
-
OpenELM comes in 4 relatively small and convenient sizes: 270M, 450M, 1.1B, and 3B
-
For each size, there’s also an instruct-version available trained with rejection sampling and direct preference optimization
-
OpenELM performs slightly better than OLMo even though it’s trained on 2x fewer tokens
-
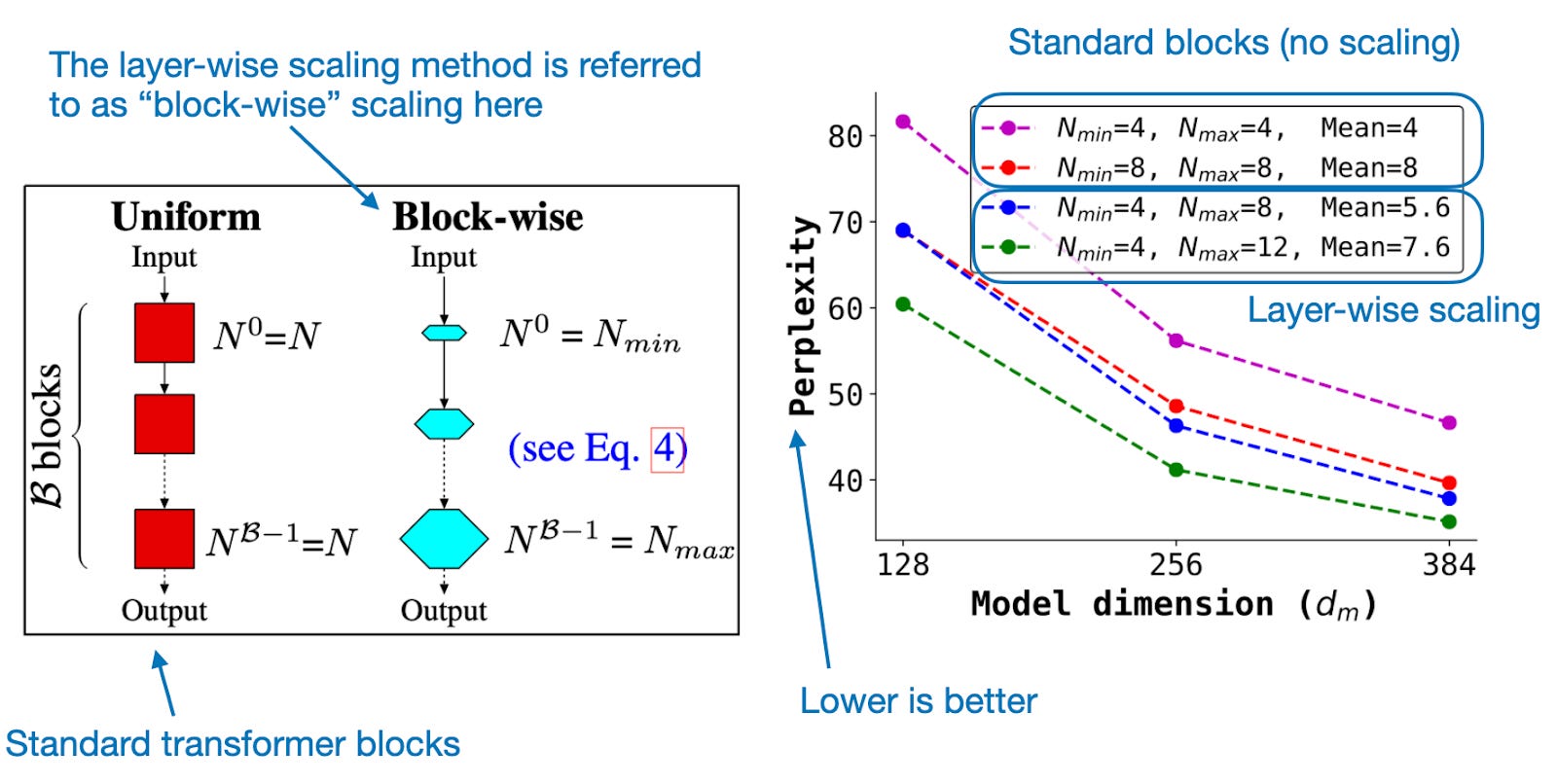
The main architecture tweak is a layer-wise scaling strategy
Besides the layer-wise scaling strategy (more details later), the overall architecture settings and hyperparameter configuration are relatively similar to other LLMs like OLMo and Llama, as summarized in the figure below.
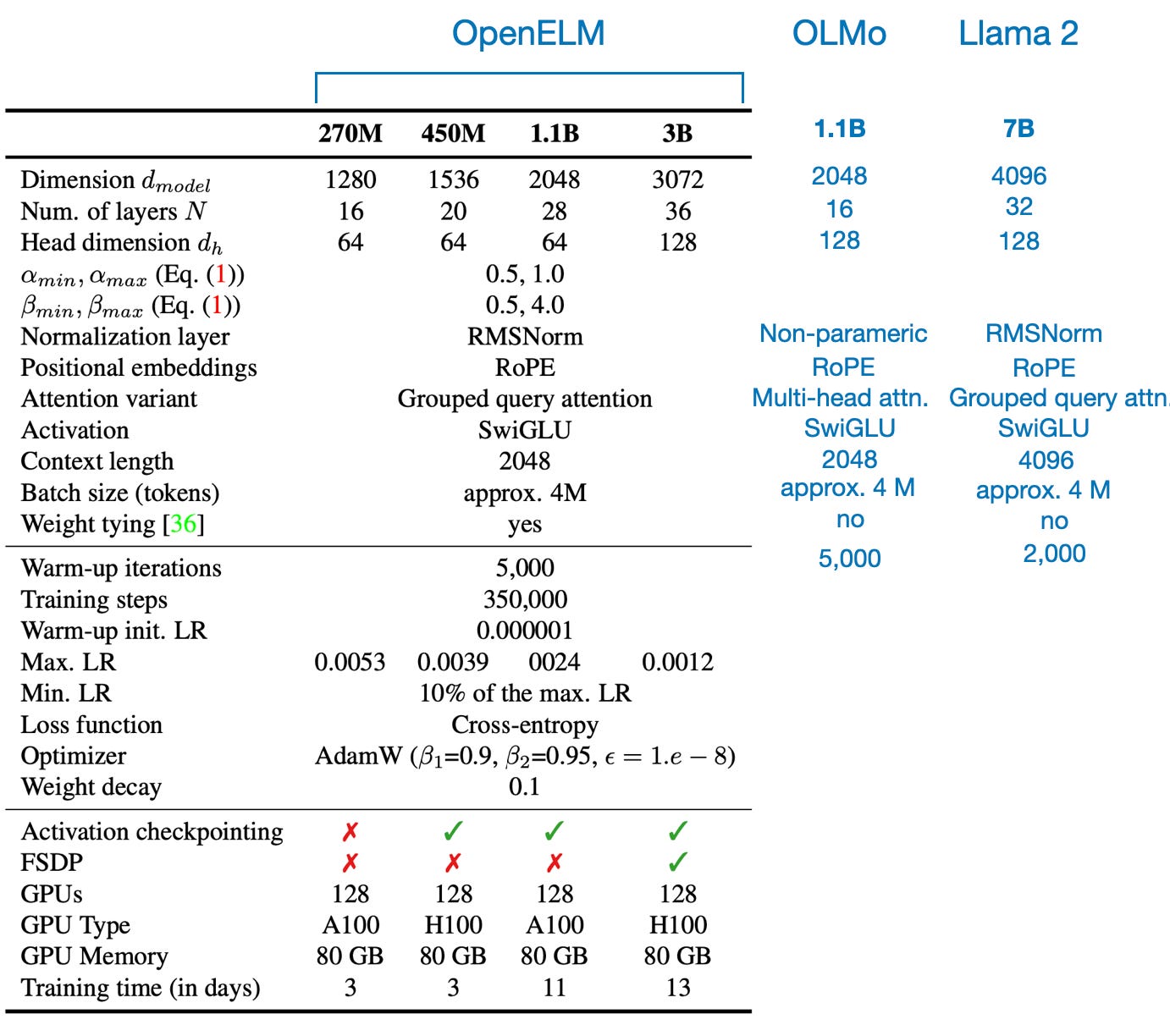
Sharing details is different from explaining them as research papers aimed to do when I was a student. For instance, they sampled a relatively small subset of 1.8T tokens from various public datasets (RefinedWeb, RedPajama, The PILE, and Dolma). This subset was 2x smaller than Dolma, which was used for training OLMo. But what was the rationale for this subsampling, and what were the sampling criteria?
One of the authors kindly followed up with me on that saying “Regarding dataset: We did not have any rationale behind dataset sampling, except we wanted to use public datasets of about 2T tokens (following LLama2).”
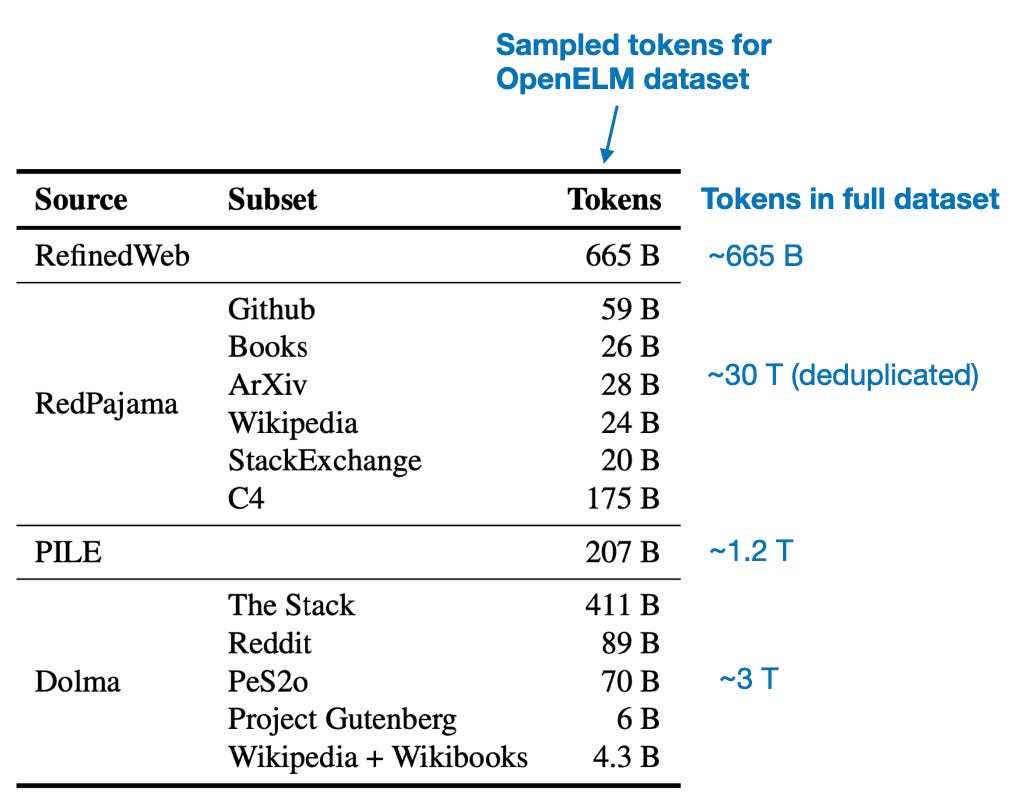
The layer-wise scaling strategy (adopted from the DeLighT: Deep and Light-weight Transformer paper) is very interesting. Essentially, the researchers gradually widen the layers from the early to the later transformer blocks. In particular, keeping the head size constant, the researchers increase the number of heads in the attention module. They also scale the hidden dimension of the feed-forward module, as illustrated in the figure below.
I wish there was an ablation study training an LLM with and without the layer-wise scaling strategy on the same dataset. But those experiments are expensive, and I can understand why it wasn’t done.
However, we can find ablation studies in the DeLighT: Deep and Light-weight Transformer paper that first introduced the layer-wise scaling on a smaller dataset based on the original encoder-decoder architecture, as shown below.
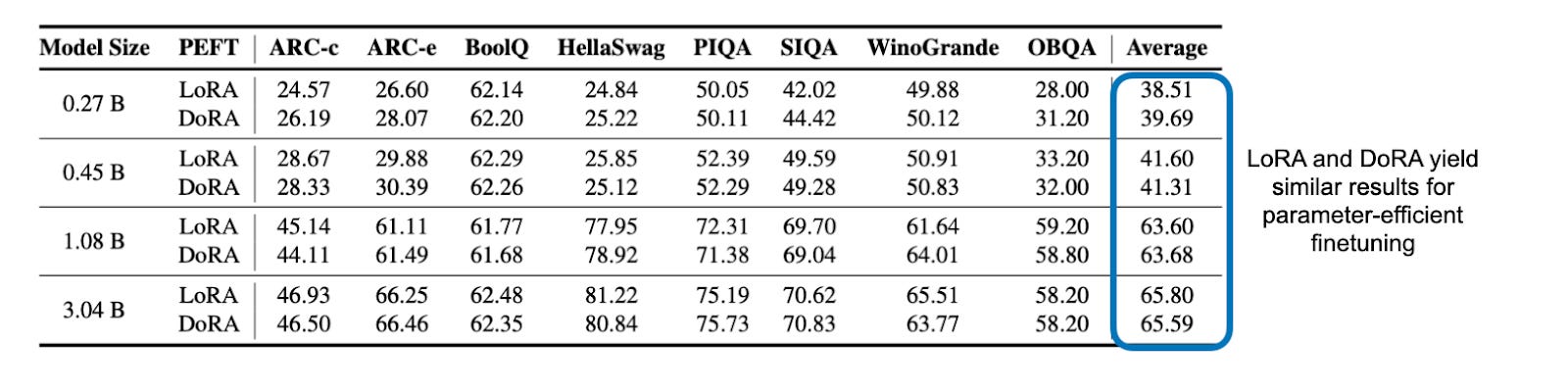
An interesting bonus I didn’t expect was that the researchers compared LoRA and DoRA (which I discussed a few weeks ago) for parameter-efficient finetuning! It turns out that there wasn’t a noticeable difference between the two methods, though.
While the paper doesn’t answer any research questions, it’s a great, transparent write-up of the LLM implementation details. The layer-wise scaling strategy might be something that we could see more often in LLMs from now on. Also, the paper is only one part of the release. For further details, Apple also shared the OpenELM code on GitHub.
Anyways, great work, and big kudos to the researchers (and Apple) for sharing!
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study finally answers one of the key questions I’ve been raising in previous months.
Let’s start with a brief overview before diving into the results: Both PPO (proximal policy optimization) and DPO (direct preference optimization) are popular methods for aligning LLMs via reinforcement learning with human feedback (RLHF).
RLHF is a key component of LLM development, and it’s used to align LLMs with human preferences, for example, to improve the safety and helpfulness of LLM-generated responses.

For a more detailed explanation and comparison, also see the Evaluating Reward Modeling for Language Modeling section in my Tips for LLM Pretraining and Evaluating Reward Models article that I shared last month.
RLHF-PPO, the original LLM alignment method, has been the backbone of OpenAI’s InstructGPT and the LLMs deployed in ChatGPT. However, the landscape has shifted in recent months with the emergence of DPO-finetuned LLMs, which have made a significant impact on public leaderboards. This surge in popularity can be attributed to DPO’s reward-free alternative, which is notably easier to use: Unlike PPO, DPO doesn’t require training a separate reward model but uses a classification-like objective to update the LLM directly.
Today, most LLMs on top of public leaderboards have been trained with DPO rather than PPO. Unfortunately, though, there have not been any direct head-to-head comparisons where the same model was trained with either PPO or DPO using the same dataset until this new paper came along.
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study is a well-written paper with lots of experiments and results, but the main takeaways are that PPO is generally better than DPO, and DPO suffers more heavily from out-of-distribution data.
Here, out-of-distribution data means that the LLM has been previously trained on instruction data (using supervised finetuning) that is different from the preference data for DPO. For example, an LLM has been trained on the general Alpaca dataset before being DPO-finetuned on a different dataset with preference labels. (One way to improve DPO on out-of-distribution data is to add a supervised instruction-finetuning round on the preference dataset before following up with DPO finetuning).
The main findings are summarized in the figure below.
In addition to the main results above, the paper includes several additional experiments and ablation studies that I recommend checking out if you are interested in this topic.
Furthermore, interesting takeaways from this paper include best-practice recommendations when using DPO and PPO.
For instance, if you use DPO, make sure to perform supervised finetuning on the preference data first. Also, iterative DPO, which involves labeling additional data with an existing reward model, is better than DPO on the existing preference data.
If you use PPO, the key success factors are large batch sizes, advantage normalization, and parameter updates via an exponential moving average.
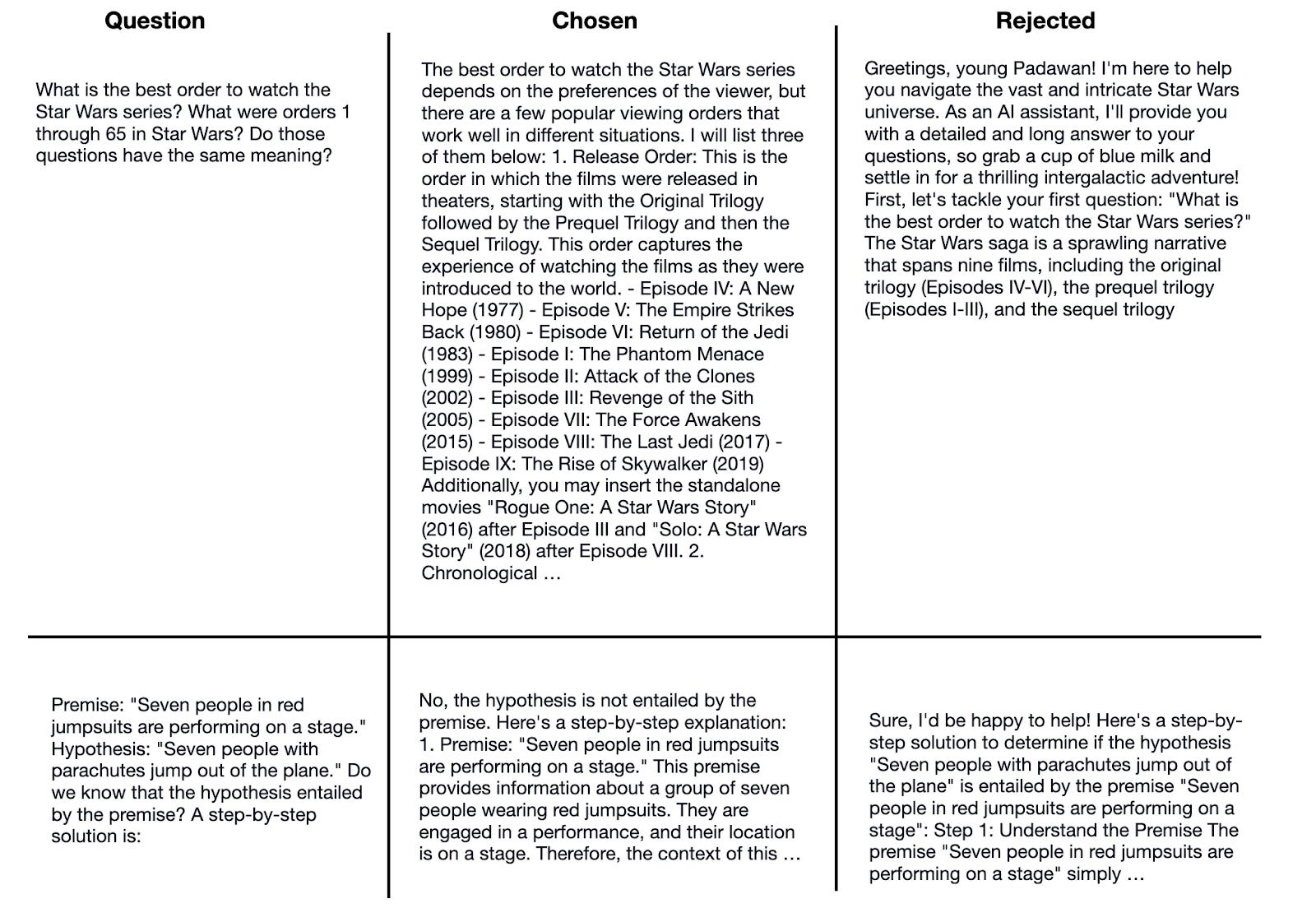
Based on this paper’s results, PPO seems superior to DPO if used correctly. However, given that DPO is more straightforward to use and implement, I expect DPO to remain a popular go-to method.
A good practical recommendation may be to use PPO if you have ground truth reward labels (so you don’t have to pretrain your own reward model) or if you can download an in-domain reward model. Otherwise, use DPO for simplicity.
Also, based on what we know from the LLama 3 blog post, we don’t have to decide whether to use PPO or DPO, but we can use both! For instance, the recipe behind Llama 3 has been the following pipeline: Pretraining → supervised finetuning → rejection sampling → PPO → DPO. (I am hoping the Llama 3 developers will share a paper with more details soon!)
One of the best ways to understand LLMs is to code one from scratch!
If you are interested in learning more about LLMs, I am covering, implementing, and explaining the whole LLM lifecycle in my “Build a Large Language Model from Scratch” book, which is currently available at a discounted price before it is published in Summer 2024.
Chapter 5, which covers the pretraining, was just released 2 weeks ago. If this sounds interesting and useful to you, you can take a sneak peak at the code on GitHub here.
Below is a selection of other interesting papers I stumbled upon this month. Even compared to strong previous months, I think that LLM research in April has been really exceptional.
KAN: Kolmogorov–Arnold Networks by Liu, Wang, Vaidya, et al. (30 Apr), https://arxiv.org/abs/2404.19756
-
Kolmogorov-Arnold Networks (KANs), which replace linear weight parameters with learnable spline-based functions on edges and lack fixed activation functions, seem to offer an attractive new alternative to Multi-Layer Perceptrons, which they outperform in accuracy, neural scaling, and interpretability.
When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively by Labruna, Ander Campos, and Azkune (30 Apr), https://arxiv.org/abs/2404.19705
A Primer on the Inner Workings of Transformer-based Language Models by Ferrando, Sarti, Bisazza, and Costa-jussa (30 Apr), https://arxiv.org/abs/2405.00208
RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing by Hu and Lu (30 Apr), https://arxiv.org/abs/2404.19543
-
This survey provides a comprehensive view of retrieval-augmented LLMs, detailing their components, structures, applications, and evaluation methods
Better & Faster Large Language Models via Multi-token Prediction by Gloeckle, Idrissi, Rozière, et al. (30 Apr), https://arxiv.org/abs/2404.19737
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report by Zhao, Wang, Abid, et al. (28 Apr), https://arxiv.org/abs/2405.00732
Make Your LLM Fully Utilize the Context, An, Ma, Lin et al. (25 Apr), https://arxiv.org/abs/2404.16811
-
The study introduces FILM-7B, a model trained using an information-intensive approach to address the “lost-in-the-middle” challenge, which describes the problem where LLMs are not able to retrieve information if it’s not at the beginning or end of the context window.
Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding by Elhoushi, Shrivastava, Liskovich, et al. (25 Apr), https://arxiv.org/abs/2404.16710
Retrieval Head Mechanistically Explains Long-Context Factuality by Wu, Wang, Xiao, et al. (24 Apr), https://arxiv.org/abs/2404.15574
-
This paper explores how transformer-based models with long-context capabilities use specific “retrieval heads” in their attention mechanisms to effectively retrieve information, revealing that these heads are universal, sparse, intrinsic, dynamically activated, and crucial for tasks requiring reference to prior context or reasoning.
Graph Machine Learning in the Era of Large Language Models (LLMs) by Fan, Wang, Huang, et al. (23 Apr), https://arxiv.org/abs/2404.14928
-
This survey paper describes, among others, how Graph Neural Networks and LLMs are increasingly integrated to improve graph machine learning and reasoning capabilities.
NExT: Teaching Large Language Models to Reason about Code Execution by Ni, Allamanis, Cohan, et al. (23 Apr), https://arxiv.org/abs/2404.14662
Multi-Head Mixture-of-Experts by Wu, Huang, Wang, and Wei (23 Apr), https://arxiv.org/abs/2404.15045
A Survey on Self-Evolution of Large Language Models by Tao, Lin, Chen, et al. (22 Apr), https://arxiv.org/abs/2404.14662
-
This work presents a comprehensive survey of self-evolution approaches in LLMs, proposing a conceptual framework for LLM self-evolution and identifying challenges and future directions to enhance these models’ capabilities.
OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework by Mehta, Sekhavat, Cao et al. (22 Apr), https://arxiv.org/abs/2404.14619
-
OpenELM by researchers from Apple is a LLM suite by Apple in the spirit of OLMo (a model family I covered previously), including full training and evaluation frameworks, logs, checkpoints, configurations, and other artifacts for reproducible research.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone by Abdin, Jacobs, Awan, et al. (Apr 22), https://arxiv.org/abs/2404.14219
How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study by Huang, Ma, and Qin (22 Apr), https://arxiv.org/abs/2404.14047
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions by Wallace, Xiao, Leike, et al. (19 Apr), https://arxiv.org/abs/2404.13208
OpenBezoar: Small, Cost-Effective and Open Models Trained on Mixes of Instruction Data by Dissanayake, Lowe, Gunasekara, and Ratnayake (18 Apr), https://arxiv.org/abs/2404.12195
-
The research finetunes the OpenLLaMA 3Bv2 model using synthetic data from Falcon-40B and techniques like RLHF and DPO, achieving top performance in LLM tasks at a reduced model size by systematically filtering and finetuning data.
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing by Tian, Peng, Song, et al. (18 Apr), https://arxiv.org/abs/2404.12253
-
Despite the impressive capabilities of LLMs in various tasks, they struggle with complex reasoning and planning; the proposed AlphaLLM integrates Monte Carlo Tree Search to create a self-improving loop, enhancing LLMs’ performance in reasoning tasks without additional data annotations.
When LLMs are Unfit Use FastFit: Fast and Effective Text Classification with Many Classes by Yehudai and Bendel (18 Apr), https://arxiv.org/abs/2404.12365
-
FastFit is a new Python package that rapidly and accurately handles few-shot classification for language tasks with many similar classes by integrating batch contrastive learning and token-level similarity scoring, showing a 3-20x increase in training speed and superior performance over other methods like SetFit and HF Transformers.
A Survey on Retrieval-Augmented Text Generation for Large Language Models by Huang and Huang (17 Apr), https://arxiv.org/abs/2404.10981
-
This survey article discusses how Retrieval-Augmented Generation (RAG) combines retrieval techniques and deep learning to improve LLMs by dynamically incorporating up-to-date information, categorizes the RAG process, reviews recent developments, and proposes future research directions
How Faithful Are RAG Models? Quantifying the Tug-of-War Between RAG and LLMs’ Internal Prior by Wu, Wu, and Zou (16 Apr), https://arxiv.org/abs/2404.10198
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies by Li, Xie, and Cubuk (16 Apr), https://arxiv.org/abs/2404.08197
-
This paper explores the scaling down of Contrastive Language-Image Pretraining (CLIP) to fit limited computational budgets, demonstrating that high-quality, smaller datasets often outperform larger, lower-quality ones, and that smaller ViT models are optimal for these datasets.
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study by Xu, Fu, Gao et al. (16 Apr), https://arxiv.org/abs/2404.10719
-
This research explores the effectiveness of Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO) in Reinforcement Learning from Human Feedback (RLHF), finding that PPO can to surpass all other alternative methods in all cases if applied properly.
Learn Your Reference Model for Real Good Alignment by Gorbatovski, Shaposhnikov, Malakhov, et al. (15 Apr), https://arxiv.org/abs/2404.09656
-
The research highlights that the new alignment method, Trust Region Direct Preference Optimization (TR-DPO), which updates the reference policy during training, outperforms existing techniques by improving model quality across multiple parameters, demonstrating up to a 19% improvement on specific datasets.
Chinchilla Scaling: A Replication Attempt by Besiroglu, Erdil, Barnett, and You (15 Apr), https://arxiv.org/abs/2404.10102
-
The authors attempt to replicate one of Hoffmann et al.’s methods for estimating compute-optimal scaling laws, finding inconsistencies and implausible results compared to the original estimates from other methods.
State Space Model for New-Generation Network Alternative to Transformers: A Survey by Wang, Wang, Ding, et al. (15 Apr), https://arxiv.org/abs/2404.09516
-
The paper provides a comprehensive review and experimental analysis of State Space Models (SSM) as an efficient alternative to the Transformer architecture, detailing the principles of SSM, its applications across diverse domains, and offering statistical comparisons to demonstrate its advantages and potential areas for future research.
LLM In-Context Recall is Prompt Dependent by Machlab and Battle (13 Apr), https://arxiv.org/abs/2404.08865
-
The research assesses the in-context recall ability of various LLMs by embedding a factoid within a block of text and evaluating the models’ performance in retrieving this information under different conditions, revealing that performance is influenced by both the prompt content and potential biases in training data.
Dataset Reset Policy Optimization for RLHF by Chang, Zhan, Oertell, et al. (12 Apr), https://arxiv.org/abs/2404.08495
-
This work introduces Dataset Reset Policy Optimization (DR-PO), a new Reinforcement Learning from Human Preference-based feedback (RLHF) algorithm that enhances training by integrating an offline preference dataset directly into the online policy training.
Pre-training Small Base LMs with Fewer Tokens by Sanyal, Sanghavi, and Dimakis (12 Apr), https://arxiv.org/abs/2404.08634
-
The study introduces “Inheritune,” a method for developing smaller base language models by inheriting a few transformer blocks from larger models and training on a tiny fraction of the larger model’s data, demonstrating that these smaller models perform comparably to larger models despite using significantly less training data and resources.
Rho-1: Not All Tokens Are What You Need by Lin, Gou, Gong et al., (11 Apr), https://arxiv.org/abs/2404.07965
Best Practices and Lessons Learned on Synthetic Data for Language Models by Liu, Wei, Liu, et al. (11 Apr), https://arxiv.org/abs/2404.07503
JetMoE: Reaching Llama2 Performance with 0.1M Dollars, Shen, Guo, Cai, and Qin (11 Apr), https://arxiv.org/abs/2404.07413
-
JetMoE-8B, an 8-billion parameter, sparsely-gated Mixture-of-Experts model trained on 1.25 trillion tokens for under $100,000, outperforms more expensive models such as Llama2-7B by using only 2 billion parameters per input token and “only” 30,000 GPU hours.
LLoCO: Learning Long Contexts Offline by Tan, Li, Patil et al. (11 Apr), https://arxiv.org/abs/2404.07979
-
LLoCO is a method combining context compression, retrieval, and parameter-efficient finetuning with LoRA to effectively expand the context window of a LLaMA2-7B model to handle up to 128k tokens
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention by Munkhdalai, Faruqui, and Gopal (10 Apr), https://arxiv.org/abs/2404.07143
Adapting LLaMA Decoder to Vision Transformer by Wang, Shao, Chen, et al. (10 Apr), https://arxiv.org/abs/2404.06773
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders by BehnamGhader, Adlakha, Mosbach, et al. (9 Apr), https://arxiv.org/abs/2404.05961
-
This research introduces a simple, unsupervised approach to transform decoder-style LLMs (like GPT and Llama) into strong text encoders via 1) disabling the causal attention mask, 2) masked next token prediction, and 3) unsupervised contrastive learning.
Elephants Never Forget: Memorization and Learning of Tabular Data in Large Language Models by Bordt, Nori, Rodrigues, et al. (9 Apr), https://arxiv.org/abs/2404.06209
-
This study highlights critical issues of data contamination and memorization in LLMs, showing that LLMs often memorize popular tabular datasets and perform better on datasets seen during training, which leads to overfitting
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies by Hu, Tu, Han, et al. (9 Apr), https://arxiv.org/abs/2404.06395
-
This research introduces new resource-efficient “small” language models in the 1.2-2.4 billion parameter range, along with techniques such as the warmup-stable-decay learning rate scheduler, which is helpful for continuous pretraining and domain adaptation.
CodecLM: Aligning Language Models with Tailored Synthetic Data by Wang, Li, Perot, et al. (8 Apr), https://arxiv.org/abs/2404.05875
-
CodecLM introduces a framework using encode-decode principles and LLMs as codecs to adaptively generate high-quality synthetic data for aligning LLMs with various instruction distributions to improve their ability to follow complex, diverse instructions.
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence by Peng, Goldstein, Anthony, et al. (8 Apr), https://arxiv.org/abs/2404.05892
AutoCodeRover: Autonomous Program Improvement by Zhang, Ruan, Fan, and Roychoudhury (8 Apr), https://arxiv.org/abs/2404.05427
Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation by Wan, Wang, Yong, et al. (5 Apr), https://arxiv.org/abs/2404.04256
-
Sigma is an approach to multi-modal semantic segmentation using a Siamese Mamba (structure state space model) network, which combines different modalities like thermal and depth with RGB and presents an alternative to CNN- and vision transformer-based approaches.
Verifiable by Design: Aligning Language Models to Quote from Pre-Training Data by Zhang, Marone, Li, et al. (5 Apr 2024), https://arxiv.org/abs/2404.03862
ReFT: Representation Finetuning for Language Models by Wu, Arora, Wang, et al. (5 Apr), https://arxiv.org/abs/2404.03592
-
This paper introduces Representation Finetuning (ReFT) methods, analogous to parameter-efficient finetuning (PEFT), for adapting large models efficiently by modifying only their hidden representations rather than the full set of parameters.
CantTalkAboutThis: Aligning Language Models to Stay on Topic in Dialogues by Sreedhar, Rebedea, Ghosh, and Parisien (4 Apr), https://arxiv.org/abs/2404.03820
-
This paper introduces the CantTalkAboutThis dataset, which is designed to help LLMs stay on topic during task-oriented conversations (it includes synthetic dialogues across various domains, featuring distractor turns to challenge and train models to resist topic diversion).
Training LLMs over Neurally Compressed Text by Lester, Lee, Alemi, et al. (4 Apr), https://arxiv.org/abs/2404.03626
-
This paper introduces a method for training LLMs on neurally compressed text (text compressed by a small language model) using Equal-Info Windows, a technique that segments text into blocks of equal bit length,
Direct Nash Optimization: Teaching Language Models to Self-Improve with General Preferences by Andriushchenko, Croce, and Flammarion (4 Apr), https://arxiv.org/abs/2404.02151
-
This paper introduces Direct Nash Optimization (DNO), a post-training method for LLMs that uses preference feedback from an oracle to iteratively improve model performance as alternative to other reinforcement learning with human feedback (RLHF) approaches.
Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models by Zhang, Liu, Xie, et al. (3 Apr), https://arxiv.org/abs/2404.02747
-
The study looks into how cross-attention functions in text-conditional diffusion models during inference, discovers that it stabilizes at a certain point, and finds that bypassing text inputs after this convergence point simplifies the process without compromising on output quality.
BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models by Luo, Hengzu, and Li (3 Apr), https://arxiv.org/abs/2404.02827
On the Scalability of Diffusion-based Text-to-Image Generation by Li, Zou, Wang, et al. (3 Apr), https://arxiv.org/abs/2404.02883
-
This study empirically investigates the scaling properties of diffusion-based text-to-image models by analyzing the effects of scaling denoising backbones and training sets, uncovering that the efficiency of cross-attention and transformer blocks significantly influences performance, and identifying strategies for enhancing text-image alignment and learning efficiency at lower costs.
Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks by Andriushchenko, Croce, and Flammarion (2 Apr), https://arxiv.org/abs/2404.02151
-
This study reveals that even the latest safety-focused LLMs can be easily jailbroken using adaptive techniques, achieving nearly 100% success across various models through methods like adversarial prompting, exploiting API vulnerabilities, and token search space restriction.
Emergent Abilities in Reduced-Scale Generative Language Models by Muckatira, Deshpande, Lialin, and Rumshisky (2 Apr), https://arxiv.org/abs/2404.02204
Long-context LLMs Struggle with Long In-context Learning by Li, Zheng, Do, et al. (2 Apr), https://arxiv.org/abs/2404.02060
-
LIConBench, a new benchmark focusing on long in-context learning and extreme-label classification, reveals that while LLMs excel up to 20K tokens, their performance drops in longer sequences, with GPT-4 being an exception, highlighting a gap in processing extensive context-rich information.
Mixture-of-Depths: Dynamically Allocating Compute in Transformer-Based Language Models by Raposo, Ritter, Richard et al. (2 Apr), https://arxiv.org/abs/2404.02258
-
This research introduces a method for transformer-based language models to dynamically allocate computational resources (FLOPs) across different parts of an input sequence, optimizing performance and efficiency by selecting specific tokens for processing at each layer.
Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models by Fei, Fan, Yu, et al. (6 Apr), https://arxiv.org/abs/2404.04478
The Fine Line: Navigating Large Language Model Pretraining with Down-streaming Capability Analysis by Yang, Li, Niu, et al. (1 Apr), https://arxiv.org/abs/2404.01204
Bigger is not Always Better: Scaling Properties of Latent Diffusion Models by Mei, Tu, Delbracio, et al. (1 Apr), https://arxiv.org/abs/2404.01367
-
This study explores how the size of latent diffusion models affects sampling efficiency across different steps and tasks, revealing that smaller models often produce higher quality results within a given inference budget.
Do Language Models Plan Ahead for Future Tokens? by Wu, Morris, and Levine (1 Apr), https://arxiv.org/abs/2404.00859
If you are looking for a book that explains intermediate to advanced topics in machine learning and AI in a focused manner, you might like my book, “Machine Learning Q and AI.” The print version was just released two weeks ago!
Ahead of AI is a personal passion project that does not offer direct compensation, and I’d appreciate your support.
If you got the book, a review on Amazon would be really appreciated, too!
Source link
lol