Today, we’re excited to share the journey of the VW—an innovator in the automotive industry and Europe’s largest car maker—to enhance knowledge management by using generative AI, Amazon Bedrock, and Amazon Kendra to devise a solution based on Retrieval Augmented Generation (RAG) that makes internal information more easily accessible by its users. This solution efficiently handles documents that include both text and images, significantly enhancing VW’s knowledge management capabilities within their production domain.
The challenge
The VW engaged with AWS Industries Prototyping & Customer Engineering Team (AWSI-PACE) to explore ways to improve knowledge management in the production domain by building a prototype that uses advanced features of Amazon Bedrock, specifically Anthropic’s Claude 3 models, to extract and analyze information from private documents, such as PDFs containing text and images. The main technical challenge was to efficiently retrieve and process data in a multi-modal setup to provide comprehensive and accurate information from Chemical Compliance private documents.
PACE, a multi-disciplinary rapid prototyping team, focuses on delivering feature-complete initial products that enable business evaluation, determining feasibility, business value, and path to production. Using the PACE-Way (an Amazon-based development approach), the team developed a time-boxed prototype over a maximum of 6 weeks, which included a full stack solution with frontend and UX, backed by specialist expertise, such as data science, tailored for VW’s needs.
The choice of Anthropic’s Claude 3 models within Amazon Bedrock was driven by Claude’s advanced vision capabilities, enabling it to understand and analyze images alongside text. This multimodal interaction is crucial for applications that require extracting insights from complex documents containing both textual content and images. These features open up exciting possibilities for multimodal interactions, making it ideal for querying private PDF documents that include both text and images.
The integrated approach and ease of use of Amazon Bedrock in deploying large language models (LLMs), along with built-in features that facilitate seamless integration with other AWS services like Amazon Kendra, made it the preferred choice. By using Claude 3’s vision capabilities, we could upload image-rich PDF documents. Claude analyzes each image contained within these documents to extract text and understand the contextual details embedded in these visual elements. The extracted text and context from the images are then added to Amazon Kendra, enhancing the search-ability and accessibility of information within the system. This integration ensures that users can perform detailed and accurate searches across the indexed content, using the full depth of information extracted by Claude 3.
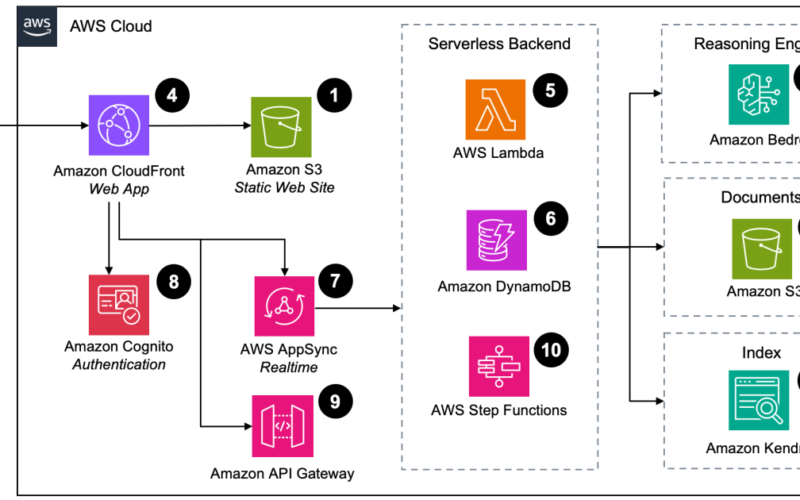
Architecture overview
Because of the need to provide access to proprietary information, it was decided early that the prototype would use RAG. The RAG approach, at this time an established solution to enhance LLMs with private knowledge, is implemented using a blend of AWS services that enable us to streamline the processing, searching, and querying of documents while at same time meeting non-functional requirements related to efficiency, scalability, and reliability. The architecture is centered around a native AWS serverless backend, which ensures minimal maintenance and high availability together with fast development.
Core components of the RAG system
- Amazon Simple Storage Service (Amazon S3): Amazon S3 serves as the primary storage for source data. It’s also used for hosting static website components, ensuring high durability and availability.
- Amazon Kendra: Amazon Kendra provides semantic search capabilities for ranking of documents and passages, it also deals with the overhead of handling text extraction, embeddings, and managing vector datastore.
- Amazon Bedrock: This component is critical for processing and inference. It uses machine learning models to analyze and interpret the text and image data extracted from documents, integrating these insights to generate context-aware responses to queries.
- Amazon CloudFront: Distributes the web application globally to reduce latency, offering users fast and reliable access to the RAG system’s interface.
- AWS Lambda: Provides the serverless compute environment for running backend operations without provisioning or managing servers, which scales automatically with the application’s demands.
- Amazon DynamoDB: Used for storing metadata and other necessary information for quick retrieval during search operations. Its fast and flexible NoSQL database service accommodates high-performance needs.
- AWS AppSync: Manages real-time data synchronization and communication between the users’ interfaces and the serverless backend, enhancing the interactive experience.
- Amazon Cognito: Manages user authentication and authorization, providing secure and scalable user access control. It supports integration with various identity providers to facilitate easy and secure user sign-in and registration processes.
- Amazon API Gateway: Acts as the entry point for all RESTful API requests to the backend services, offering features such as throttling, monitoring, and API version management.
- AWS Step Functions: Orchestrates the various AWS services involved in the RAG system, ensuring coordinated execution of the workflow.
Solution walkthrough
The process flow handles complex documents efficiently from the moment a user uploads a PDF. These documents are often large and contain numerous images. This workflow integrates AWS services to extract, process, and make content available for querying. This section details the steps involved in processing uploaded documents and ensuring that extracted data is searchable and contextually relevant to user queries (shown in the following figure).

Initiation and initial processing:
- User access: A user accesses the web interface through CloudFront, which allows users to upload PDFs as shown in Image A in Results. These PDFs are stored in Amazon S3.
- Text extraction: With the Amazon Kendra S3 connector, the solution indexes the S3 bucket repository of documents that the user has uploaded in Step 1. Amazon Kendra supports popular document types or formats such as PDF, HTML, Word, PowerPoint, and more. An index can contain multiple document formats. Amazon Kendra extracts the content inside the documents to make the documents searchable. The documents are parsed to optimize search on the extracted text within the documents. This means structuring the documents into fields or attributes that are used for search.
- Step function activation: When an object is created in S3, such as a user uploading a file in Step 1, the solution will launch a step function that orchestrates the document processing workflow for adding image context to the Kendra index.
Image extraction and analysis:
- Extract images: While Kendra indexes the text from the uploaded file, the step function extracts the images from the document. Extracting the images from the uploaded file allows the solution to process the images using Amazon Bedrock to extract text and contextual information. The code snippet that follows provides a sample of the code used to extract the images from the PDF file and save them back to S3.
import json
import fitz # PyMuPDF
import os
import boto3
# Initialize the S3 client
s3 = boto3.client('s3')
def lambda_handler(event, context):
bucket_name = event['bucket_name']
pdf_key = event['pdf_key']
# Define the local paths
local_pdf_path="/tmp/" + os.path.basename(pdf_key)
local_image_dir="/tmp/images"
# Ensure the image directory exists
if not os.path.exists(local_image_dir):
os.makedirs(local_image_dir)
# Download the PDF from S3
s3.download_file(bucket_name, pdf_key, local_pdf_path)
# Open the PDF file using PyMuPDF
pdf_file = fitz.open(local_pdf_path)
pdf_name = os.path.splitext(os.path.basename(local_pdf_path))[0] # Extract PDF base name for labeling
total_images_extracted = 0 # Counter for all images extracted from this PDF
image_filenames = [] # List to store the filenames of extracted images
# Iterate through each page of the PDF
for current_page_index in range(len(pdf_file)):
# Extract images from the current page
for img_index, img in enumerate(pdf_file.get_page_images(current_page_index)):
xref = img[0]
image = fitz.Pixmap(pdf_file, xref)
# Construct image filename with a global counter
image_filename = f"{pdf_name}_image_{total_images_extracted}.png"
image_path = os.path.join(local_image_dir, image_filename)
total_images_extracted += 1
# Save the image appropriately
if image.n < 5: # GRAY or RGB
image.save(image_path)
else: # CMYK, requiring conversion to RGB
new_image = fitz.Pixmap(fitz.csRGB, image)
new_image.save(image_path)
new_image = None
image = None
# Upload the image back to S3
s3.upload_file(image_path, bucket_name, f'images/{image_filename}')
# Add the image filename to the list
image_filenames.append(image_filename)
# Return the response with the list of image filenames and total images extracted
return {
'statusCode': 200,
'image_filenames': image_filenames,
'total_images_extracted': total_images_extracted
}
-
- Lambda function code:
- Initialization: The function initializes the S3 client.
- Event extraction: Extracts the bucket name and PDF key from the incoming event payload.
- Local path set up: Defines local paths for storing the PDF and extracted images.
- Directory creation: Ensures the directory for images exists.
- PDF download: Downloads the PDF file from S3.
- Image extraction: Opens the PDF and iterates through its pages to extract images.
- Image processing: Saves the images locally and uploads them back to S3.
- Filename collection: Collects the filenames of the uploaded images.
- Return statement: Returns the list of image filenames and the total number of images extracted.
- Lambda function code:
- Text extraction from images: The image files processed from the previous step are then sent to Amazon Bedrock, where advanced models extract textual content and contextual details from the images. The step function uses a map state to iterate over the list of images, processing each one individually. Claude 3 offers image-to-text vision capabilities that can process images and return text outputs. It excels at analyzing and understanding charts, graphs, technical diagrams, reports, and other visual assets. Claude 3 Sonnet achieves comparable performance to other best-in-class models with image processing capabilities while maintaining a significant speed advantage. The following is a sample snippet that extracts the contextual information from each image in the map state.
import json
import base64
import boto3
from botocore.exceptions import ClientError
# Initialize the boto3 client for BedrockRuntime and S3
s3 = boto3.client('s3', region_name="us-west-2")
bedrock_runtime = boto3.client('bedrock-runtime', region_name="us-west-2")
def lambda_handler(event, context):
source_bucket = event['bucket_name']
destination_bucket = event['destination_bucket']
image_filename = event['image_filename']
try:
# Get the image from S3
image_file = s3.get_object(Bucket=source_bucket, Key=image_filename)
contents = image_file['Body'].read()
# Encode the image to base64
encoded_string = base64.b64encode(contents).decode('utf-8')
# Prepare the payload for Bedrock
payload = {
"modelId": "anthropic.claude-3-sonnet-20240229-v1:0",
"contentType": "application/json",
"accept": "application/json",
"body": {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096,
"temperature": 0.7,
"top_p": 0.999,
"top_k": 250,
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": encoded_string
}
},
{
"type": "text",
"text": "Extract all text."
}
]
}
]
}
}
# Call Bedrock to extract text from the image
body_bytes = json.dumps(payload['body']).encode('utf-8')
response = bedrock_runtime.invoke_model(
body=body_bytes,
contentType=payload['contentType'],
accept=payload['accept'],
modelId=payload['modelId']
)
response = json.loads(response['body'].read().decode('utf-8'))
response_content = response['content'][0]
response_text = response_content['text']
# Save the extracted text to S3
text_file_key = image_filename.replace('.png', '.txt')
s3.put_object(Bucket=destination_bucket, Key=text_file_key, Body=str(response_text))
return {
'statusCode': 200,
'text_file_key': text_file_key,
'message': f"Processed and saved text for {image_filename}"
}
except Exception as e:
return {
'statusCode': 500,
'error': str(e),
'message': f"An error occurred processing {image_filename}"
}
-
- Lambda function code:
- Initialization: The script initializes the boto3 clients for
BedrockRuntimeand S3 services to interact with AWS resources. - Lambda handler: The main function (
lambda_handler) is invoked when the Lambda function is run. It receives the event and context parameters. - Retrieve image: The image file is retrieved from the specified S3 bucket using the
get_objectmethod. - Base64 encoding: The image is read and encoded to a base64 string, which is required for sending the image data to Bedrock.
- Payload preparation: A payload is constructed with the base64 encoded image and a request to extract text.
- Invoke Amazon Bedrock: The Amazon Bedrock model is invoked using the prepared payload to extract text from the image.
- Process response: The response from Amazon Bedrock is parsed to extract the textual content.
- Save text to S3: The extracted text is saved back to the specified S3 bucket with a filename derived from the original image filename.
- Return statement: The function returns a success message and the key of the saved text file. If an error occurs, it returns an error message.
- Initialization: The script initializes the boto3 clients for
- Lambda function code:
Data storage and indexing:
- Save to S3: The extracted text from the images are saved back to S3 as text files.
- Indexing by Amazon Kendra: After being saved in S3, the data is indexed by Amazon Kendra, making it searchable and accessible for queries. This indexing adds the image context to perform similarity searches in the RAG system.
User query with semantic search and inference
The semantic search and inference process of our solution plays a critical role in providing users with accurate and contextually relevant information based on their queries.
Semantic search focuses on understanding the intent and contextual meaning behind a user’s query instead of relying solely on keyword matching. Amazon Kendra, an advanced enterprise search service, uses semantic search to deliver more accurate and relevant results. By using natural language processing (NLP) and machine learning algorithms, Amazon Kendra can interpret the nuances of a query, ensuring that the retrieved documents and data align closely with the user’s actual intent.

User query handling:
- User interaction: Users submit their queries through a user-friendly interface.
Semantic search with Amazon Kendra:
- Context retrieval: Upon receiving a query, Amazon Kendra performs a semantic search to identify the most relevant documents and data. The advanced NLP capabilities of Amazon Kendra allow it to understand the intent and contextual nuances of the query.
- Provision of relevant context: Amazon Kendra provides a list of documents that are ranked based on their relevance to the user’s query. This ensures that the response is not only based on keyword matches but also on the semantic relevance of the content. Note that Amazon Kendra also uses the text extracted from images, which was processed with Amazon Bedrock, to enhance the search results.
Inference with Amazon Bedrock:
- Contextual analysis and inference: The relevant documents and data retrieved by Amazon Kendra are then passed to Amazon Bedrock. The inference models available in Amazon Bedrock consider both the context provided by Kendra and the specific details of the user query. This dual consideration allows Amazon Bedrock to formulate responses that are not only accurate but also finely tuned to the specifics of the query. The following are the snippets for generating prompts that help Bedrock provide accurate and contextually relevant responses:
def get_qa_prompt(self):
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}"""
return PromptTemplate(template=template, input_variables=["context", "question"])
def get_prompt(self):
template = """The following is a friendly conversation between a human and an AI. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{chat_history}
Question: {input}"""
input_variables = ["input", "chat_history"]
prompt_template_args = {
"chat_history": "{chat_history}",
"input_variables": input_variables,
"template": template,
}
prompt_template = PromptTemplate(**prompt_template_args)
return prompt_template
def get_condense_question_prompt(self):
template = """<conv>
{chat_history}
</conv>
<followup>
{question}
</followup>
Given the conversation inside the tags <conv></conv>, rephrase the follow up question you find inside <followup></followup> to be a standalone question, in the same language as the follow up question.
"""
return PromptTemplate(input_variables=["chat_history", "question"], template=template)
-
- QA prompt explanation:
- QA Prompt:
- This prompt is designed to use the context provided by Amazon Kendra to answer a question accurately. The context provided by Amazon Kendra is from the most relevant documents and data processed by the semantic search from the user query.
- It instructs the AI to use the given context and only provide an answer if it is certain; otherwise, it should admit not knowing the answer.
- QA Prompt:
- QA prompt explanation:
Response delivery:
- Delivery to user: This response is then delivered back to the user; completing the cycle of query and response.
Results
Our evaluation of the system revealed significant multi-lingual capabilities, enhancing user interaction with documents in multiple languages:
- Multilingual support: The model showed strong performance across different languages. Despite the documents being primarily in German, the system handled queries in English effectively. It translated the extracted text from the PDFs or images from German to English, providing responses in English. This feature was crucial for English-speaking users.
- Seamless language transition: The system also supports transitions between languages. Users could ask questions in German and receive responses in German, maintaining context and accuracy. This dual-language functionality significantly enhanced efficiency, catering to documents containing both German and English.
- Enhanced user experience: This multilingual capability broadened the system’s accessibility and ensured users could receive information in their preferred language, making interactions more intuitive.
Image A demonstrates a user querying their private data. The solution successfully answers the query using the private data. The answer isn’t derived from the extracted text within the files, but from an image embedded in the uploaded file.

Image B shows the specific image from which Amazon Bedrock extracted the text and added it to the index, enabling the system to provide the correct answer.

Image C also shows a scenario where, without the image context, the question cannot be answered.

Following the successful prototype development, Stefan Krawinkel from VW shared his thoughts:
“We are thrilled by the AWS team’s joy of innovation and the constant questioning of solutions for the requirements we brought to the prototype. The solutions developed give us a good overview of what is possible with generative AI, and what limits still exist today. We are confident that we will continue to push existing boundaries together with AWS to be able to offer attractive products to our customers.”
This testimonial highlights how the collaborative effort addressed the complex challenges and underscores the ongoing potential for innovation in future projects.
Additional thanks to Fabrizio Avantaggiato, Verena Koutsovagelis and Jon Reed for their work on this prototype.
About the Authors
 Rui Costa specializes in Software Engineering and currently holds the position of Principal Solutions Developer within the AWS Industries Prototyping and Customer Engineering (PACE) Team based out of Jersey City, New Jersey.
Rui Costa specializes in Software Engineering and currently holds the position of Principal Solutions Developer within the AWS Industries Prototyping and Customer Engineering (PACE) Team based out of Jersey City, New Jersey.
 Mahendra Bairagi is a Generative AI specialist who currently holds a position of Principal Solutions Architect – Generative AI within the AWS Industries and Customer Engineering (PACE) team. Throughout his more than 9 years at AWS, Mahendra has held a variety of pivotal roles, including Principal AI/ML Specialist, IoT Specialist, Principal Product Manager and head of Sports Innovations Lab. In these capacities, he has consistently led innovative solutions, driving significant advancements for both customers and partners.
Mahendra Bairagi is a Generative AI specialist who currently holds a position of Principal Solutions Architect – Generative AI within the AWS Industries and Customer Engineering (PACE) team. Throughout his more than 9 years at AWS, Mahendra has held a variety of pivotal roles, including Principal AI/ML Specialist, IoT Specialist, Principal Product Manager and head of Sports Innovations Lab. In these capacities, he has consistently led innovative solutions, driving significant advancements for both customers and partners.
Source link
lol