In the rapidly evolving world of AI, the ability to customize language models for specific industries has become more important. Although large language models (LLMs) are adept at handling a wide range of tasks with natural language, they excel at general purpose tasks as compared with specialized tasks. This can create challenges when processing text data from highly specialized domains with their own distinct terminology or specialized tasks where intrinsic knowledge of the LLM is not well-suited for solutions such as Retrieval Augmented Generation (RAG).
For instance, in the automotive industry, users might not always provide specific diagnostic trouble codes (DTCs), which are often proprietary to each manufacturer. These codes, such as P0300 for a generic engine misfire or C1201 for an ABS system fault, are crucial for precise diagnosis. Without these specific codes, a general purpose LLM might struggle to provide accurate information. This lack of specificity can lead to hallucinations in the generated responses, where the model invents plausible but incorrect diagnoses, or sometimes result in no answers at all. For example, if a user simply describes “engine running rough” without providing the specific DTC, a general LLM might suggest a wide range of potential issues, some of which may be irrelevant to the actual problem, or fail to provide any meaningful diagnosis due to insufficient context. Similarly, in tasks like code generation and suggestions through chat-based applications, users might not specify the APIs they want to use. Instead, they often request help in resolving a general issue or in generating code that utilizes proprietary APIs and SDKs.
Moreover, generative AI applications for consumers can offer valuable insights into the types of interactions from end-users. With appropriate feedback mechanisms, these applications can also gather important data to continuously improve the behavior and responses generated by these models.
For these reasons, there is a growing trend in the adoption and customization of small language models (SLMs). SLMs are compact transformer models, primarily utilizing decoder-only or encoder-decoder architectures, typically with parameters ranging from 1–8 billion. They are generally more efficient and cost-effective to train and deploy compared to LLMs, and are highly effective when fine-tuned for specific domains or tasks. SLMs offer faster inference times, lower resource requirements, and are suitable for deployment on a wider range of devices, making them particularly valuable for specialized applications and edge computing scenarios. Additionally, more efficient techniques for customizing both LLMs and SLMs, such as Low Rank Adaptation (LoRA), are making these capabilities increasingly accessible to a broader range of customers.
AWS offers a wide range of solutions for interacting with language models. Amazon Bedrock is a fully managed service that offers foundation models (FMs) from Amazon and other AI companies to help you build generative AI applications and host customized models. Amazon SageMaker is a comprehensive, fully managed machine learning (ML) service to build, train, and deploy LLMs and other FMs at scale. You can fine-tune and deploy models with Amazon SageMaker JumpStart or directly through Hugging Face containers.
In this post, we guide you through the phases of customizing SLMs on AWS, with a specific focus on automotive terminology for diagnostics as a Q&A task. We begin with the data analysis phase and progress through the end-to-end process, covering fine-tuning, deployment, and evaluation. We compare a customized SLM with a general purpose LLM, using various metrics to assess vocabulary richness and overall accuracy. We provide a clear understanding of customizing language models specific to the automotive domain and its benefits. Although this post focuses on the automotive domain, the approaches are applicable to other domains. You can find the source code for the post in the associated Github repository.
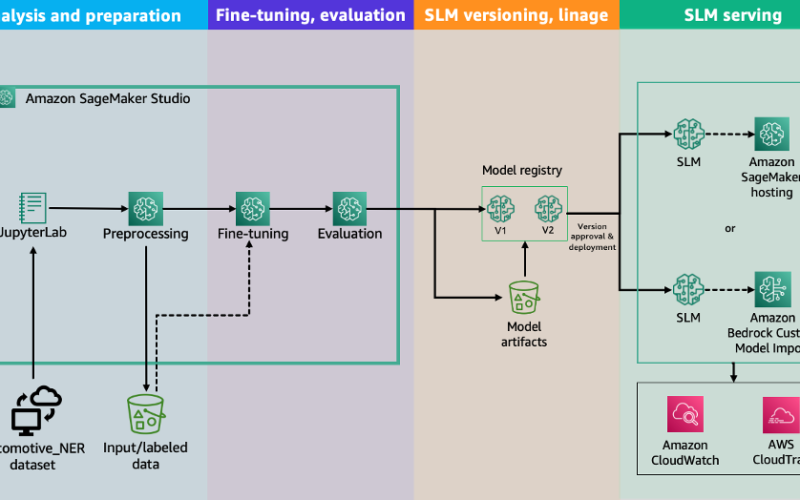
Solution overview
This solution uses multiple features of SageMaker and Amazon Bedrock, and can be divided into four main steps:
- Data analysis and preparation – In this step, we assess the available data, understand how it can be used to develop solution, select data for fine-tuning, and identify required data preparation steps. We use Amazon SageMaker Studio, a comprehensive web-based integrated development environment (IDE) designed to facilitate all aspects of ML development. We also employ SageMaker jobs to access more computational power on-demand, thanks to the SageMaker Python SDK.
- Model fine-tuning – In this step, we prepare prompt templates for fine-tuning SLM. For this post, we use Meta Llama3.1 8B Instruct from Hugging Face as the SLM. We run our fine-tuning script directly from the SageMaker Studio JupyterLab environment. We use the @remote decorator feature of the SageMaker Python SDK to launch a remote training job. The fine-tuning script uses LoRA, distributing compute across all available GPUs on a single instance.
- Model deployment – When the fine-tuning job is complete and the model is ready, we have two deployment options:
- Deploy in SageMaker by selecting the best instance and container options available.
- Deploy in Amazon Bedrock by importing the fine-tuned model for on-demand use.
- Model evaluation – In this final step, we evaluate the fine-tuned model against a similar base model and a larger model available from Amazon Bedrock. Our evaluation focuses on how well the model uses specific terminology for the automotive space, as well as the improvements provided by fine-tuning in generating answers.
The following diagram illustrates the solution architecture.
Using the Automotive_NER dataset
The Automotive_NER dataset, available on the Hugging Face platform, is designed for named entity recognition (NER) tasks specific to the automotive domain. This dataset is specifically curated to help identify and classify various entities related to the automotive industry and uses domain-specific terminologies.
The dataset contains approximately 256,000 rows; each row contains annotated text data with entities related to the automotive domain, such as car brands, models, component, description of defects, consequences, and corrective actions. The terminology used to describe defects, reference to components, or error codes reported is a standard for the automotive industry. The fine-tuning process enables the language model to learn the domain terminologies better and helps improve the vocabulary used in the generation of answers and overall accuracy for the generated answers.
The following table is an example of rows contained in the dataset.
| 1 | COMPNAME | DESC_DEFECT | CONEQUENCE_DEFECT | CORRECTIVE_ACTION |
| 2 | ELECTRICAL SYSTEM:12V/24V/48V BATTERY:CABLES | CERTAIN PASSENGER VEHICLES EQUIPPED WITH ZETEC ENGINES, LOOSE OR BROKEN ATTACHMENTS AND MISROUTED BATTERY CABLES COULD LEAD TO CABLE INSULATION DAMAGE. | THIS, IN TURN, COULD CAUSE THE BATTERY CABLES TO SHORT RESULTING IN HEAT DAMAGE TO THE CABLES. BESIDES HEAT DAMAGE, THE “CHECK ENGINE” LIGHT MAY ILLUMINATE, THE VEHICLE MAY FAIL TO START, OR SMOKE, MELTING, OR FIRE COULD ALSO OCCUR. | DEALERS WILL INSPECT THE BATTERY CABLES FOR THE CONDITION OF THE CABLE INSULATION AND PROPER TIGHTENING OF THE TERMINAL ENDS. AS NECESSARY, CABLES WILL BE REROUTED, RETAINING CLIPS INSTALLED, AND DAMAGED BATTERY CABLES REPLACED. OWNER NOTIFICATION BEGAN FEBRUARY 10, 2003. OWNERS WHO DO NOT RECEIVE THE FREE REMEDY WITHIN A REASONABLE TIME SHOULD CONTACT FORD AT 1-866-436-7332. |
| 3 | ELECTRICAL SYSTEM:12V/24V/48V BATTERY:CABLES | CERTAIN PASSENGER VEHICLES EQUIPPED WITH ZETEC ENGINES, LOOSE OR BROKEN ATTACHMENTS AND MISROUTED BATTERY CABLES COULD LEAD TO CABLE INSULATION DAMAGE. | THIS, IN TURN, COULD CAUSE THE BATTERY CABLES TO SHORT RESULTING IN HEAT DAMAGE TO THE CABLES. BESIDES HEAT DAMAGE, THE “CHECK ENGINE” LIGHT MAY ILLUMINATE, THE VEHICLE MAY FAIL TO START, OR SMOKE, MELTING, OR FIRE COULD ALSO OCCUR. | DEALERS WILL INSPECT THE BATTERY CABLES FOR THE CONDITION OF THE CABLE INSULATION AND PROPER TIGHTENING OF THE TERMINAL ENDS. AS NECESSARY, CABLES WILL BE REROUTED, RETAINING CLIPS INSTALLED, AND DAMAGED BATTERY CABLES REPLACED. OWNER NOTIFICATION BEGAN FEBRUARY 10, 2003. OWNERS WHO DO NOT RECEIVE THE FREE REMEDY WITHIN A REASONABLE TIME SHOULD CONTACT FORD AT 1-866-436-7332. |
| 4 | EQUIPMENT:OTHER:LABELS | ON CERTAIN FOLDING TENT CAMPERS, THE FEDERAL CERTIFICATION (AND RVIA) LABELS HAVE THE INCORRECT GROSS VEHICLE WEIGHT RATING, TIRE SIZE, AND INFLATION PRESSURE LISTED. | IF THE TIRES WERE INFLATED TO 80 PSI, THEY COULD BLOW RESULTING IN A POSSIBLE CRASH. | OWNERS WILL BE MAILED CORRECT LABELS FOR INSTALLATION ON THEIR VEHICLES. OWNER NOTIFICATION BEGAN SEPTEMBER 23, 2002. OWNERS SHOULD CONTACT JAYCO AT 1-877-825-4782. |
| 5 | STRUCTURE | ON CERTAIN CLASS A MOTOR HOMES, THE FLOOR TRUSS NETWORK SUPPORT SYSTEM HAS A POTENTIAL TO WEAKEN CAUSING INTERNAL AND EXTERNAL FEATURES TO BECOME MISALIGNED. THE AFFECTED VEHICLES ARE 1999 – 2003 CLASS A MOTOR HOMES MANUFACTURED ON F53 20,500 POUND GROSS VEHICLE WEIGHT RATING (GVWR), FORD CHASSIS, AND 2000-2003 CLASS A MOTOR HOMES MANUFACTURED ON W-22 22,000 POUND GVWR, WORKHORSE CHASSIS. | CONDITIONS CAN RESULT IN THE BOTTOMING OUT THE SUSPENSION AND AMPLIFICATION OF THE STRESS PLACED ON THE FLOOR TRUSS NETWORK. THE ADDITIONAL STRESS CAN RESULT IN THE FRACTURE OF WELDS SECURING THE FLOOR TRUSS NETWORK SYSTEM TO THE CHASSIS FRAME RAIL AND/OR FRACTURE OF THE FLOOR TRUSS NETWORK SUPPORT SYSTEM. THE POSSIBILITY EXISTS THAT THERE COULD BE DAMAGE TO ELECTRICAL WIRING AND/OR FUEL LINES WHICH COULD POTENTIALLY LEAD TO A FIRE. | DEALERS WILL INSPECT THE FLOOR TRUSS NETWORK SUPPORT SYSTEM, REINFORCE THE EXISTING STRUCTURE, AND REPAIR, AS NEEDED, THE FLOOR TRUSS NETWORK SUPPORT. OWNER NOTIFICATION BEGAN NOVEMBER 5, 2002. OWNERS SHOULD CONTACT MONACO AT 1-800-685-6545. |
| 6 | STRUCTURE | ON CERTAIN CLASS A MOTOR HOMES, THE FLOOR TRUSS NETWORK SUPPORT SYSTEM HAS A POTENTIAL TO WEAKEN CAUSING INTERNAL AND EXTERNAL FEATURES TO BECOME MISALIGNED. THE AFFECTED VEHICLES ARE 1999 – 2003 CLASS A MOTOR HOMES MANUFACTURED ON F53 20,500 POUND GROSS VEHICLE WEIGHT RATING (GVWR), FORD CHASSIS, AND 2000-2003 CLASS A MOTOR HOMES MANUFACTURED ON W-22 22,000 POUND GVWR, WORKHORSE CHASSIS. | CONDITIONS CAN RESULT IN THE BOTTOMING OUT THE SUSPENSION AND AMPLIFICATION OF THE STRESS PLACED ON THE FLOOR TRUSS NETWORK. THE ADDITIONAL STRESS CAN RESULT IN THE FRACTURE OF WELDS SECURING THE FLOOR TRUSS NETWORK SYSTEM TO THE CHASSIS FRAME RAIL AND/OR FRACTURE OF THE FLOOR TRUSS NETWORK SUPPORT SYSTEM. THE POSSIBILITY EXISTS THAT THERE COULD BE DAMAGE TO ELECTRICAL WIRING AND/OR FUEL LINES WHICH COULD POTENTIALLY LEAD TO A FIRE. | DEALERS WILL INSPECT THE FLOOR TRUSS NETWORK SUPPORT SYSTEM, REINFORCE THE EXISTING STRUCTURE, AND REPAIR, AS NEEDED, THE FLOOR TRUSS NETWORK SUPPORT. OWNER NOTIFICATION BEGAN NOVEMBER 5, 2002. OWNERS SHOULD CONTACT MONACO AT 1-800-685-6545. |
Data analysis and preparation on SageMaker Studio
When you’re fine-tuning LLMs, the quality and composition of your training data are crucial (quality over quantity). For this post, we implemented a sophisticated method to select 6,000 rows out of 256,000. This method uses TF-IDF vectorization to identify the most significant and the rarest words in the dataset. By selecting rows containing these words, we maintained a balanced representation of common patterns and edge cases. This improves computational efficiency and creates a high-quality, diverse subset leading to effective model training.
The first step is to open a JupyterLab application previously created in our SageMaker Studio domain.

After you clone the git repository, install the required libraries and dependencies:
The next step is to read the dataset:
The first step of our data preparation activity is to analyze the importance of the words in our dataset, for identifying both the most important (frequent and distinctive) words and the rarest words in the dataset, by using Term Frequency-Inverse Document Frequency (TF-IDF) vectorization.
Given the dataset’s size, we decided to run the fine-tuning job using Amazon SageMaker Training.
By using the @remote function capability of the SageMaker Python SDK, we can run our code into a remote job with ease.
In our case, the TF-IDF vectorization and the extraction of the top words and bottom words are performed in a SageMaker training job directly from our notebook, without any code changes, by simply adding the @remote decorator on top of our function. You can define the configurations required by the SageMaker training job, such as dependencies and training image, in a config.yaml file. For more details on the settings supported by the config file, see Using the SageMaker Python SDK
See the following code:
Next step is to define and execute our processing function:
After we extract the top and bottom 6,000 words based on their TF-IDF scores from our original dataset, we classify each row in the dataset based on whether it contained any of these important or rare words. Rows are labeled as ‘top’ if they contained important words, ‘bottom’ if they contained rare words, or ‘neither’ if they don’t contain either:
Finally, we create a balanced subset of the dataset by selecting all rows containing important words (‘top’) and an equal number of rows containing rare words (‘bottom’). If there aren’t enough ‘bottom’ rows, we filled the remaining slots with ‘neither’ rows.
| DESC_DEFECT | CONEQUENCE_DEFECT | CORRECTIVE_ACTION | word_type | |
| 2 | ON CERTAIN FOLDING TENT CAMPERS, THE FEDERAL C… | IF THE TIRES WERE INFLATED TO 80 PSI, THEY COU… | OWNERS WILL BE MAILED CORRECT LABELS FOR INSTA… | top |
| 2402 | CERTAIN PASSENGER VEHICLES EQUIPPED WITH DUNLO… | THIS COULD RESULT IN PREMATURE TIRE WEAR. | DEALERS WILL INSPECT AND IF NECESSARY REPLACE … | bottom |
| 0 | CERTAIN PASSENGER VEHICLES EQUIPPED WITH ZETEC… | THIS, IN TURN, COULD CAUSE THE BATTERY CABLES … | DEALERS WILL INSPECT THE BATTERY CABLES FOR TH… | neither |
Finally, we randomly sampled 6,000 rows from this balanced set:
Fine-tuning Meta Llama 3.1 8B with a SageMaker training job
After selecting the data, we need to prepare the resulting dataset for the fine-tuning activity. By examining the columns, we aim to adapt the model for two different tasks:
The following code is for the first prompt:
With this prompt, we instruct the model to highlight the possible consequences of a defect, given the manufacturer, component name, and description of the defect.
The following code is for the second prompt:
With this second prompt, we instruct the model to suggest possible corrective actions for a given defect and component of a specific manufacturer.
First, let’s split the dataset into train, test, and validation subsets:
Next, we create prompt templates to convert each row item into the two prompt formats previously described:
Now we can apply the template functions template_dataset_consequence and template_dataset_corrective_action to our datasets:


As a final step, we concatenate the four resulting datasets for train and test:

Our final training dataset comprises approximately 12,000 elements, properly split into about 11,000 for training and 1,000 for testing.
Now we can prepare the training script and define the training function train_fn and put the @remote decorator on the function.
The training function does the following:
- Tokenizes and chunks the dataset
- Sets up
BitsAndBytesConfig, for model quantization, which specifies the model should be loaded in 4-bit - Uses mixed precision for the computation, by converting model parameters to
bfloat16 - Loads the model
- Creates LoRA configurations that specify ranking of update matrices (
r), scaling factor (lora_alpha), the modules to apply the LoRA update matrices (target_modules), dropout probability for Lora layers (lora_dropout),task_type, and more - Starts the training and evaluation
Because we want to distribute the training across all the available GPUs in our instance, by using PyTorch Distributed Data Parallel (DDP), we use the Hugging Face Accelerate library that enables us to run the same PyTorch code across distributed configurations.
For optimizing memory resources, we have decided to run a mixed precision training:
We can specify to run a distributed job in the @remote function through the parameters use_torchrun and nproc_per_node, which indicates if the SageMaker job should use as entrypoint torchrun and the number of GPUs to use. You can pass optional parameters like volume_size, subnets, and security_group_ids using the @remote decorator.
Finally, we run the job by invoking train_fn():
The training job runs on the SageMaker training cluster. The training job took about 42 minutes, by distributing the computation across the 4 available GPUs on the selected instance type ml.g5.12xlarge.
We choose to merge the LoRA adapter with the base model. This decision was made during the training process by setting the merge_weights parameter to True in our train_fn() function. Merging the weights provides us with a single, cohesive model that incorporates both the base knowledge and the domain-specific adaptations we’ve made through fine-tuning.
By merging the model, we gain flexibility in our deployment options.
Model deployment
When deploying a fine-tuned model on AWS, multiple deployment strategies are available. In this post, we explore two deployment methods:
- SageMaker real-time inference – This option is designed for having full control of the inference resources. We can use a set of available instances and deployment options for hosting our model. By using the SageMaker built-in containers, such as DJL Serving or Hugging Face TGI, we can use the inference script and the optimization options provided in the container.
- Amazon Bedrock Custom Model Import – This option is designed for importing and deploying custom language models. We can use this fully managed capability for interacting with the deployed model with on-demand throughput.
Model deployment with SageMaker real-time inference
SageMaker real-time inference is designed for having full control over the inference resources. It allows you to use a set of available instances and deployment options for hosting your model. By using the SageMaker built-in container Hugging Face Text Generation Inference (TGI), you can take advantage of the inference script and optimization options available in the container.
In this post, we deploy the fine-tuned model to a SageMaker endpoint for running inference, which will be used for evaluating the model in the next step.
We create the HuggingFaceModel object, which is a high-level SageMaker model class for working with Hugging Face models. The image_uri parameter specifies the container image URI for the model, and model_data points to the Amazon Simple Storage Service (Amazon S3) location containing the model artifact (automatically uploaded by the SageMaker training job). We also specify a set of environment variables to configure the number of GPUs (SM_NUM_GPUS), quantization methodology (QUANTIZE), and maximum input and total token lengths (MAX_INPUT_LENGTH and MAX_TOTAL_TOKENS).
After creating the model object, we can deploy it to an endpoint using the deploy method. The initial_instance_count and instance_type parameters specify the number and type of instances to use for the endpoint. The container_startup_health_check_timeout and model_data_download_timeout parameters set the timeout values for the container startup health check and model data download, respectively.
It takes a few minutes to deploy the model before it becomes available for inference and evaluation. The endpoint is invoked using the AWS SDK with the boto3 client for sagemaker-runtime, or directly by using the SageMaker Python SDK and the predictor previously created, by using the predict API.
Model deployment with Amazon Bedrock Custom Model Import
Amazon Bedrock Custom Model Import is a fully managed capability, currently in public preview, designed for importing and deploying custom language models. It allows you to interact with the deployed model both on-demand and by provisioning the throughput.
In this section, we use the Custom Model Import feature in Amazon Bedrock for deploying our fine-tuned model in the fully managed environment of Amazon Bedrock.


After defining the model and job_name variables, we import our model from the S3 bucket by supplying it in the Hugging Face weights format.

Next, we use a preexisting AWS Identity and Access Management (IAM) role that allows reading the binary file from Amazon S3 and create the import job resource in Amazon Bedrock for hosting our model.

It takes a few minutes to deploy the model, and it can be invoked using the AWS SDK with the boto3 client for bedrock-runtime by using the invoke_model API:
Model evaluation
In this final step, we evaluate the fine-tuned model against the base models Meta Llama 3 8B Instruct and Meta Llama 3 70B Instruct on Amazon Bedrock. Our evaluation focuses on how well the model uses specific terminology for the automotive space and the improvements provided by fine-tuning in generating answers.
The fine-tuned model’s ability to understand components and error descriptions for diagnostics, as well as identify corrective actions and consequences in the generated answers, can be evaluated on two dimensions.
To evaluate the quality of the generated text and whether the vocabulary and terminology used are appropriate for the task and industry, we use the Bilingual Evaluation Understudy (BLEU) score. BLEU is an algorithm for evaluating the quality of text, by calculating n-gram overlap between the generated and the reference text.
To evaluate the accuracy of the generated text and see if the generated answer is similar to the expected one, we use the Normalized Levenshtein distance. This algorithm evaluates how close the calculated or measured values are to the actual value.
The evaluation dataset comprises 10 unseen examples of component diagnostics extracted from the original training dataset.
The prompt template for the evaluation is structured as follows:
BLEU score evaluation with base Meta Llama 3 8B and 70B Instruct
The following table and figures show the calculated values for the BLEU score comparison (higher is better) with Meta Llama 3 8B and 70 B Instruct.
| Example | Fine-Tuned Score | Base Score: Meta Llama 3 8B | Base Score: Meta Llama 3 70B | |
| 1 | 2733 | 0. 2936 | 5.10E-155 | 4.85E-155 |
| 2 | 3382 | 0.1619 | 0.058 | 1.134E-78 |
| 3 | 1198 | 0.2338 | 1.144E-231 | 3.473E-155 |
| 4 | 2942 | 0.94854 | 2.622E-231 | 3.55E-155 |
| 5 | 5151 | 1.28E-155 | 0 | 0 |
| 6 | 2101 | 0.80345 | 1.34E-78 | 1.27E-78 |
| 7 | 5178 | 0.94854 | 0.045 | 3.66E-155 |
| 8 | 1595 | 0.40412 | 4.875E-155 | 0.1326 |
| 9 | 2313 | 0.94854 | 3.03E-155 | 9.10E-232 |
| 10 | 557 | 0.89315 | 8.66E-79 | 0.1954 |


By comparing the fine-tuned and base scores, we can assess the performance improvement (or degradation) achieved by fine-tuning the model in the vocabulary and terminology used.
The analysis suggests that for the analyzed cases, the fine-tuned model outperforms the base model in the vocabulary and terminology used in the generated answer. The fine-tuned model appears to be more consistent in its performance.
Normalized Levenshtein distance with base Meta Llama 3 8B Instruct
The following table and figures show the calculated values for the Normalized Levenshtein distance comparison with Meta Llama 3 8B and 70B Instruct.
| Example | Fine-tuned Score | Base Score – Llama 3 8B | Base Score – Llama 3 70B | |
| 1 | 2733 | 0.42198 | 0.29900 | 0.27226 |
| 2 | 3382 | 0.40322 | 0.25304 | 0.21717 |
| 3 | 1198 | 0.50617 | 0.26158 | 0.19320 |
| 4 | 2942 | 0.99328 | 0.18088 | 0.19420 |
| 5 | 5151 | 0.34286 | 0.01983 | 0.02163 |
| 6 | 2101 | 0.94309 | 0.25349 | 0.23206 |
| 7 | 5178 | 0.99107 | 0.14475 | 0.17613 |
| 8 | 1595 | 0.58182 | 0.19910 | 0.27317 |
| 9 | 2313 | 0.98519 | 0.21412 | 0.26956 |
| 10 | 557 | 0.98611 | 0.10877 | 0.32620 |


By comparing the fine-tuned and base scores, we can assess the performance improvement (or degradation) achieved by fine-tuning the model on the specific task or domain.
The analysis shows that the fine-tuned model clearly outperforms the base model across the selected examples, suggesting the fine-tuning process has been quite effective in improving the model’s accuracy and generalization in understanding the specific cause of the component defect and providing suggestions on the consequences.
In the evaluation analysis performed for both selected metrics, we can also highlight some areas for improvement:
- Example repetition – Provide similar examples for further improvements in the vocabulary and generalization of the generated answer, increasing the accuracy of the fine-tuned model.
- Evaluate different data processing techniques – In our example, we selected a subset of the original dataset by analyzing the frequency of words across the entire dataset, extracting the rows containing the most meaningful information and identifying outliers. Further curation of the dataset by properly cleaning and expanding the number of examples can increase the overall performance of the fine-tuned model.
Clean up
After you complete your training and evaluation experiments, clean up your resources to avoid unnecessary charges. If you deployed the model with SageMaker, you can delete the created real-time endpoints using the SageMaker console. Next, delete any unused SageMaker Studio resources. If you deployed the model with Amazon Bedrock Custom Model Import, you can delete the imported model using the Amazon Bedrock console.
Conclusion
This post demonstrated the process of customizing SLMs on AWS for domain-specific applications, focusing on automotive terminology for diagnostics. The provided steps and source code show how to analyze data, fine-tune models, deploy them efficiently, and evaluate their performance against larger base models using SageMaker and Amazon Bedrock. We further highlighted the benefits of customization by enhancing vocabulary within specialized domains.
You can evolve this solution further by implementing proper ML pipelines and LLMOps practices through Amazon SageMaker Pipelines. SageMaker Pipelines enables you to automate and streamline the end-to-end workflow, from data preparation to model deployment, enhancing reproducibility and efficiency. You can also improve the quality of training data using advanced data processing techniques. Additionally, using the Reinforcement Learning from Human Feedback (RLHF) approach can align the model response to human preferences. These enhancements can further elevate the performance of customized language models across various specialized domains. You can find the sample code discussed in this post on the GitHub repo.
About the authors
 Bruno Pistone is a Senior Generative AI and ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations
Bruno Pistone is a Senior Generative AI and ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations
 Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive and Industrial customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive and Industrial customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
Source link
lol