LLMs have taken the field of natural language processing by storm. With the right prompting, LLMs can solve all sorts of tasks in a zero- or few-shot way, demonstrating impressive capabilities. However, a key weakness of current LLMs seems to be self-correction – the ability to find and fix errors in their own outputs.
A new paper by researchers at Google and the University of Cambridge digs into this issue of LLM self-correction. The authors divide the self-correction process into two distinct components:
-
Mistake finding, which refers to identifying errors in an LLM’s output
-
Output correction, which involves actually fixing those mistakes once they’ve been pinpointed.
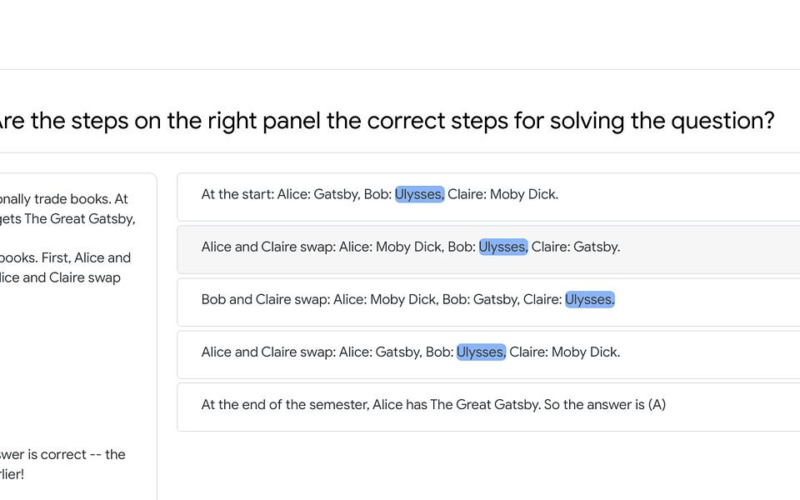
Their analysis focuses specifically on reasoning tasks, where LLMs generate a multi-step chain-of-thought (CoT) style trace showing their step-by-step reasoning process. So what did they find?
Source link
lol