Managing cloud costs and understanding resource usage can be a daunting task, especially for organizations with complex AWS deployments. AWS Cost and Usage Reports (AWS CUR) provides valuable data insights, but interpreting and querying the raw data can be challenging.
In this post, we explore a solution that uses generative artificial intelligence (AI) to generate a SQL query from a user’s question in natural language. This solution can simplify the process of querying CUR data stored in an Amazon Athena database using SQL query generation, running the query on Athena, and representing it on a web portal for ease of understanding.
The solution uses Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Challenges addressed
The following challenges can hinder organizations from effectively analyzing their CUR data, leading to potential inefficiencies, overspending, and missed opportunities for cost-optimization. We aim to target and simplify them using generative AI with Amazon Bedrock.
- Complexity of SQL queries – Writing SQL queries to extract insights from CUR data can be complex, especially for non-technical users or those unfamiliar with the CUR data structure (unless you’re a seasoned database administrator)
- Data accessibility – To gain insights from structured data in databases, users need to get access to databases, which can be a potential threat to overall data protection
- User-friendliness – Traditional methods of analyzing CUR data often lack a user-friendly interface, making it challenging for non-technical users to take advantage of the valuable insights hidden within the data
Solution overview
The solution that we discuss is a web application (chatbot) that allows you to ask questions related to your AWS costs and usage in natural language. The application generates SQL queries based on the user’s input, runs them against an Athena database containing CUR data, and presents the results in a user-friendly format. The solution combines the power of generative AI, SQL generation, database querying, and an intuitive web interface to provide a seamless experience for analyzing CUR data.
The solution uses the following AWS services:
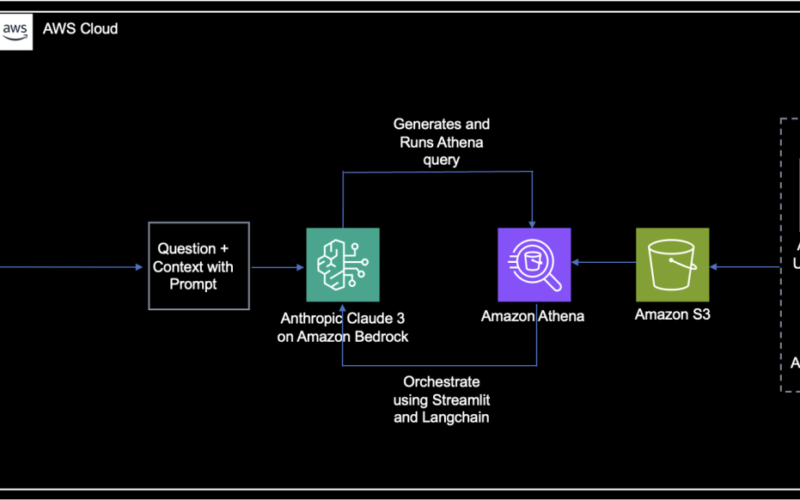
The following diagram illustrates the solution architecture.
Figure 1. Architecture of Solution
The data flow consists of the following steps:
- The CUR data is stored in Amazon S3.
- Athena is configured to access and query the CUR data stored in Amazon S3.
- The user interacts with the Streamlit web application and submits a natural language question related to AWS costs and usage.

Figure 2. Shows the Chatbot Dashboard to ask question
- The Streamlit application sends the user’s input to Amazon Bedrock, and the LangChain application facilitates the overall orchestration.
- The LangChain code uses the BedrockChat class from LangChain to invoke the FM and interact with Amazon Bedrock to generate a SQL query based on the user’s input.

Figure 3. Shows initialization of SQL chain
- The generated SQL query is run against the Athena database using the FM on Amazon Bedrock, which queries the CUR data stored in Amazon S3.
- The query results are returned to the LangChain application.

Figure 4. Shows generated Query in the application output logs
- LangChain sends the SQL query and query results back to the Streamlit application.
- The Streamlit application displays the SQL query and query results to the user in a formatted and user-friendly manner.

Figure 5. Shows final output presented on the chat bot webapp including SQL Query and the Query results
Prerequisites
To set up this solution, you should have the following prerequisites:
Configure the solution
Complete the following steps to set up the solution:
- Create an Athena database and table to store your CUR data. Make sure the necessary permissions and configurations are in place for Athena to access the CUR data stored in Amazon S3.
- Set up your compute environment to call Amazon Bedrock APIs. Make sure you associate an IAM role with this environment that has IAM policies that grant access to Amazon Bedrock.
- When your instance is up and running, install the following libraries that are used for working within the environment:
- Use the following code to establish a connection to the Athena database using the langchain library and the pyathena Configure the language model to generate SQL queries based on user input using Amazon Bedrock. You can save this file as cur_lib.py.
- Create a Streamlit web application to provide a UI for interacting with the LangChain application. Include the input fields for users to enter their natural language questions and display the generated SQL queries and query results. You can name this file cur_app.py.
- Connect the LangChain application and Streamlit web application by calling the get_response Format and display the SQL query and result in the Streamlit web application. Append the following code with the preceding application code:
- Deploy the Streamlit application and LangChain application to your hosting environment, such as Amazon EC2, or a Lambda function.
Clean up
Unless you invoke Amazon Bedrock with this solution, you won’t incur charges for it. To avoid ongoing charges for Amazon S3 storage for saving the CUR reports, you can remove the CUR data and S3 bucket. If you set up the solution using Amazon EC2, make sure you stop or delete the instance when you’re done.
Benefits
This solution offers the following benefits:
- Simplified data analysis – You can analyze CUR data using natural language using generative AI, eliminating the need for advanced SQL knowledge
- Increased accessibility – The web-based interface makes it efficient for non-technical users to access and gain insights from CUR data without needing credentials for the database
- Time-saving – You can quickly get answers to your cost and usage questions without manually writing complex SQL queries
- Enhanced visibility – The solution provides visibility into AWS costs and usage, enabling better cost-optimization and resource management decisions
Summary
The AWS CUR chatbot solution uses Anthropic Claude on Amazon Bedrock to generate SQL queries, database querying, and a user-friendly web interface to simplify the analysis of CUR data. By allowing you to ask natural language questions, the solution removes barriers and empowers both technical and non-technical users to gain valuable insights into AWS costs and resource usage. With this solution, organizations can make more informed decisions, optimize their cloud spending, and improve overall resource utilization. We recommend that you do due diligence while setting this up, especially for production; you can choose other programming languages and frameworks to set it up according to your preference and needs.
Amazon Bedrock enables you to build powerful generative AI applications with ease. Accelerate your journey by following the quick start guide on GitHub and using Amazon Bedrock Knowledge Bases to rapidly develop cutting-edge Retrieval Augmented Generation (RAG) solutions or enable generative AI applications to run multistep tasks across company systems and data sources using Amazon Bedrock Agents.
About the Author
 Anutosh is a Solutions Architect at AWS India. He loves to dive deep into his customers’ use cases to help them navigate through their journey on AWS. He enjoys building solutions in the cloud to help customers. He is passionate about migration and modernization, data analytics, resilience, cybersecurity, and machine learning.
Anutosh is a Solutions Architect at AWS India. He loves to dive deep into his customers’ use cases to help them navigate through their journey on AWS. He enjoys building solutions in the cloud to help customers. He is passionate about migration and modernization, data analytics, resilience, cybersecurity, and machine learning.
Source link
lol