1. Introduction
1.1. Objective
The approach used involves finding mentions of startups and their new technologies in news media. This process is of course possible using indicators such as mentions using “#” on Twitter/X, but in order to develop a more robust system, we decided to use Named Entity Recognition (NER). This approach allows us to automatically find mentions of new companies, technological domains, and products directly from unstructured text on the web. Furthermore, fine-tuning a system using texts directly related to renewable energies will permit us to create a specialized system that can adapt to the various challenges presented by unstructured text and provide more accurate and nuanced insights into the evolving landscape of renewable energy startups and innovations.
This process is applied to news media, and allows for a corpus of specific articles to be quickly extracted and analyzed. We detail the web-scraping process and show that it is possible to create corpora using exact dates, publishing country, and language. The goal of this process is to quickly extract names of trending companies, technological domains, and potential products for decision makers to quickly orient themselves and their potential research and investments into certain sectors, products, or approaches.
1.2. Challenges
Several challenges to this project include fine-tuning models to recognize a new category as well as adapting the ORG category to include names of companies (startups) that it may never have seen in its original training phase. The hope with this fine-tuning approach is to evaluate the model’s capacity to generalize to novel company names that may not have been specifically annotated in the model’s original training data. As many companies, especially startups, were founded after the original training of these models, it is highly unlikely that all of the startups that are in the fine-tuning dataset will be contained in the original training data. This is to say, that although these models can effectively detect company names, it may be unlikely that they detect all novel company names. We will be evaluating their performance on these unseen companies and compare the models to their baseline performance on the category “ORG”.
For this approach, we fine-tune several transformer and CNN models in order to add a category, “TECH”. This category corresponds to a technological domain or a technological product. The specificity of this category is in the renewable energy domain. This means that while an entity “solar panel” will be correctly annotated by the fine-tuned models, an entity such as “iPhone” would not be annotated.
As most models have been previously trained on a large quantity of data in their training phases, the models used are able to adapt their weights using fine-tuning techniques. Fine-tuning is necessary when adding a new category as the model needs new data in order to learn and generalize. Fine-tuning is also necessary when examining domain-specific texts and adapting to the unique challenges presented by specific domains as well as new company names.
A further challenge faced here is disambiguation of entities between the “PERSON” and the “ORG” tags. We can see several entities tagged incorrectly, and this is due to the fact that some organizations do in fact use the name of a person for their organization. In this case, it is important to ensure a high quality of training data and to ensure a sufficient amount of examples in the new data for fine-tuning.
2. Similar Projects
3. Methodology
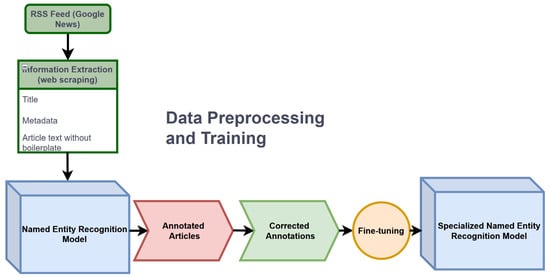
3.1. Full Preprocessing and Training Pipeline
For the creation of the model, all of the steps discussed below are combined into a single pipeline. We start with the extraction and preprocessing of news articles so that we can be sure to target the maximum quantity of the relevant texts. Next, these texts are split into individual sentences and given to a first NER model. These annotated texts are then corrected, and the “TECH” category is added. Once the annotation phase is complete, the annotations are split into a training dataset (80%) and a validation dataset (20%).
3.2. Web-Scraping
The resulting RSS feed will contain up to one hundred articles for a specific date and for a specific search term. Using this RSS feed, we automatically classify the resulting articles by the request that was made and add fields for the date as well as the source of the media.
All articles were written on either the 27 or the 28 of March 2024. While it is great to see that the category of “renewable energies” is well represented and composes 53% of the corpus, the “hydroelectric” and “energy startup” categories are underrepresented in the corpus. As the goal is to be able to find company names, technological domains, and products, this does not pose a problem in the case of fine-tuning the model, as we will see in the results.
3.3. spaCy NER
3.4. Preprocessing
After choosing our training corpus, the data were preprocessed in order to facilitate the the annotation and training processes. The process is as follows:
-
All articles were split into individual sentences;
-
All sentences were fed to spaCy, in order to create Doc objects;
-
The tokenizer was applied to all texts;
-
The default large French model “fr_core_news_lg” was used to preannotate texts with “ORG”, “LOC”, and “PER” labels.
This approach allows for us to split the data into chunks that are manageable both for the annotator and for the model.
3.5. Annotation
Annotation Guide
As there is only one annotator, these guidelines were established so that the annotator can quickly consult the guide.
3.6. Training spaCy Pipelines
3.7. Choice of Models
3.7.1. spaCy fr_core_news_lg
3.7.2. Babelscape/Wikineural-Multilingual-Ner
3.7.3. CamemBERT
The model has been trained on several downstream tasks, including NER, on which it improves the state of the art and asserts itself as a reference for French transformer models.
3.7.4. DistilCamemBERT
3.7.5. Camembert NER
4. Model Training
All models are trained using the same data and the same hyperparameters to ensure that no training is biased. The models are trained using 3260 annotations, split into 80% training and 20% validation sets. An additional 460 annotations were created and corrected from a random subset of articles. These annotations were used to evaluate all models so to ensure that they perform well when shown new data not used during training.
Hardware and Optimizer
Training was performed using a GeForce RTX 4070 Laptop GPU on a laptop with 16 GB of RAM. The Adam V1 optimizer was used. All models were trained using the default spaCy settings, which does not limit the number of epochs of training and only finishes training once no significant progress is being made from one epoch to the next.
5. Results and Discussion
When comparing these models, we can observe that the one CNN model, spaCy fr_core_news_lg, has the most difficult adaptation to our data. In response to the performance of this model, the decision was made to examine the effectiveness of transformer models on this same task. As a result, this model is the only CNN represented in this paper. This model is the least capable of the five of generalizing to new data. As discussed, the main roadblocks in this project are the addition of a new category, “TECH”, as well as expanding the “ORG” category to include names of new companies/startups that were not seen in the original training data before fine-tuning.
6. Training with Limited Data
As data annotation is a resource-intensive task, it is crucial to assess the performance of Named Entity Recognition (NER) models on smaller, frugal datasets. To this end, we conducted experiments by training our best model on various fractions (20%, 40%, 60%) of the full training data. The 80% split is the standard amount of training data as the remaining 20% is used for the validation set. This approach helps demonstrate the feasibility of deploying NER models in scenarios where only limited annotated data are available, such as in specialized domains or emerging fields.
Additionally, training with limited data highlights the importance of model efficiency and data quality. Our experiments show that careful selection and annotation of a smaller, high-quality dataset can often compensate for the lack of extensive annotated data. Future work could explore techniques such as data augmentation, active learning, and semi-supervised learning to further enhance the performance of NER models on frugal datasets, ensuring that they remain effective and reliable in various practical applications.
7. Practical Applications
These results confirm that our approach is possible and that the new category is able to be successfully integrated into the existing NER pipelines for French. With the best-performing model, the correct entities are extracted in roughly nine out of ten instances. This performance shows that a majority of technological domains, names and titles, company names, and locations can be automatically extracted and used to gain insight into industry trends.
Here, we can see that all relevant technological domains related to renewable energy have been correctly found and labeled by the model. These domains are photovoltaic, solar, wind, biogas, geothermal, and hydroelectric energy.
These results allow us to extract information on trending companies, trending technological domains, and new products. A next step, below, is the extraction of company mentions in news articles based on a simple metric of the number of articles in which a given company is mentioned.
This approach allows for a quick analysis of mentions in news media, and as these data include the top 150 news articles in renewable energies and energy startups, they give a reliable image of which companies are currently being discussed.
It is important to note that although we are interested in company names, the model is specialized in finding organization names. This means that even nonprofit organizations such as Greenpeace or conferences such as the COP28 are also detected by the model.
Once the list of companies is extracted, it is possible to access public databases on company financial information, websites, and contacts in order to manually evaluate companies that are recognized by the model.
Co-Occurrences of ORG and TECH in the Same Article
To preprocess this data, companies were all converted to lowercase as some mentions had varied casing. All technological domains were converted to a base form in order to group plural and singular forms together.
When filtering for the companies and technological domains that are mentioned the most frequently, we find certain companies and domains that are fairly well represented in our small news corpus. In order to show the information that was automatically extracted, we have ordered the top ten companies with the top three technological domains mentioned. All data have been ordered by mentions of wind power (éolien); the other columns are hydraulic power and nuclear power.
In addition to showing the trending companies and their associated domains, this functionality has another use. This approach allows for the automatic classification of companies that are only mentioned once or twice. If they are present with a mention of a specific domain, we can associate the two in order to immediately classify previously unknown companies.
8. Conclusions
This approach allowed the creation of a Named Entity Recognition model specialized in detecting startup names as well as technological domains in the renewable energies sector. We have fine-tuned the model to recognize entities specifically related to this sector and have added a new category, “TECH”. We see a high F1 score in all categories for the most optimal model, as well as performance above 65% on the new category in all CamemBERT models.
Using these models to extract information is a quick process that we have shown can have a high level of accuracy. With a small amount of code and a fine-tuned model, we can extract information from the web in a fraction of the time manual analyses would need. We have shown that it is possible to extract mentions of companies and new startups, as well as adding a new category. Statistically analyzing mentions of companies and technological domains allows for us to analyze current trends in the industry as well as to detect new technologies and companies. We have shown that regrouping and taking measures of co-occurrences of the two main categories allows for relevant information to be immediately extracted from a custom corpus.
With this new category, we have demonstrated that all that is needed is a few thousand high-quality, domain-specific examples. We can easily fine-tune a model and allow for it to generalize and find new entities in our data based on patterns that have been assimilated.
Using only a few thousand examples, it is possible to fine-tune a model capable of extracting entities correctly nine times out of ten. With this approach, spending only a few hours annotating data allows for an enormous amount of time saved for both analysts and decision makers.
Future Perspectives
As we have found that this approach of adding new, specific categories for technological domains and products is possible without an exorbitant amount of resources, it would be useful to continue this project. It is possible to use the newly developed model to annotate new texts, correct the annotations, then fine-tune the model to further improve its effectiveness.
With the addition of more annotated data, as well as a more diverse set of articles to annotate, the best-performing models can be fine-tuned in order to further increase performance and reliability. As a next step, we can also evaluate the effectiveness of training on restrained, frugal datasets in order to maximize performance.
As we have seen the successful creation of new categories with a small amount of high-quality data, it would be possible to continue expanding the capabilities of these models. A future possibility as well is to further discuss metrics that interest business use-cases to regroup and analyze the extracted information in useful ways. We can continue creating and fine-tuning new categories in line with information needed by business analysts.
Once the models are judged to be satisfactory for an industrial application, a database of trending companies, products, and domains can be established. Products can be linked to existing public patent information, information on the company, and scientific papers that the company has published. Together, these indicators and the information extracted can be a way to evaluate companies quickly in order to rate their performance and future viability.
Author Contributions
Conceptualization, C.M. and D.C.; methodology, C.M.; software, C.M.; validation, C.M. and D.C.; formal analysis, C.M.; investigation, C.M.; resources, C.M.; data curation, C.M.; writing—original draft preparation, C.M.; writing—review and editing, C.M. and D.C.; visualization, C.M.; supervision, D.C.; project administration, D.C. All authors have read and agreed to the published version of the manuscript.
Funding
Data Availability Statement
All data used in this study has been generated using the tools and methods outlined in this article. Should any difficulties arise when attempting to recreate these experiments, all data used, including annotations made during the project, can be sent upon request.
Acknowledgments
This work was accomplished in the CSIP group at the ICube laboratory, INSA of Strasbourg during a PhD contract. We extend our appreciation to all colleagues for their support, collaboration, and ideas given during this project. Special appreciation is extended to the EDF (Électricité de France) Discovery Group for their invaluable collaboration throughout this project. Their support and insights have greatly enriched the outcomes of this research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Abdullah, M. Gnews: Provide an API to Search for Articles on Google News and Returns a Usable JSON Response. Online Resource on GitHub. Available online: https://github.com/ranahaani/GNews (accessed on 5 April 2024).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Honnibal, M.; Montani, I. spaCy 2: Natural Language Understanding with Bloom Embeddings, Convolutional Neural Networks, and Incremental Parsing. Published in 2017. Available online: https://spacy.io (accessed on 2 April 2024).
- Nakayama, H.; Kubo, T.; Kamura, J.; Taniguchi, Y.; Liang, X. doccano: Text Annotation Tool for Human. 2018. Available online: https://github.com/doccano/doccano (accessed on 2 April 2024).
- Weichselbraun, A.; Streiff, D.; Scharl, A. Linked Enterprise Data for Fine Grained Named Entity Linking and Web Intelligence. In Proceedings of the 4th International Conference on Web Intelligence, Mining and Semantics (WIMS ’14), Thessaloniki, Greece, 2–4 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1–11, ISBN 978-1-4503-2538-7. [Google Scholar]
- Unanue, I.J.; Borzeshi, E.Z.; Piccardi, M. Recurrent neural networks with specialized word embeddings for health-domain named-entity recognition. J. Biomed. Inform. 2017, 76, 102–109. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Advances in Neural Information Processing Systems, 2017; volume 30, pp. 5998–6008. Available online: https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf (accessed on 3 April 2024).
- Kumar, M.; Chaturvedi, K.K.; Sharma, A.; Arora, A.; Farooqi, M.S.; Lal, S.B.; Lama, A.; Ranjan, R. An Algorithm for Automatic Text Annotation for Named Entity Recognition Using the spaCy Framework. Preprints 2023. Available online: https://typeset.io/pdf/an-algorithm-for-automatic-text-annotation-for-named-entity-3r6892x9.pdf (accessed on 3 April 2024).
- Jayathilake, H.M. Custom NER Model for Pandemic Outbreak Surveillance Using Twitter. MSc Thesis, Robert Gordon University, Aberdeen, Scotland, 2021. [Google Scholar]
- Satheesh, D.K.; Jahnavi, A.; Iswarya, L.; Ayesha, K.; Bhanusekhar, G.; Hanisha, K. Resume Ranking based on Job Description using SpaCy NER model. Int. Res. J. Eng. Technol. 2020, 7, 74–77. [Google Scholar]
- Goel, M.; Agarwal, A.; Agrawal, S.; Kapuriya, J.; Konam, A.V.; Gupta, R.; Rastogi, S.; Niharika; Bagler, G. Deep Learning Based Named Entity Recognition Models for Recipes. Preprint. Available online: https://arxiv.org/abs/2402.17447 (accessed on 4 April 2024).
- Richardson, L. Beautifulsoup4: Screen-Scraping Library. Available online: https://www.crummy.com/software/BeautifulSoup/bs4/ (accessed on 4 April 2024).
- Pomikálek, J. jusText: Heuristic-Based Boilerplate Removal Tool. Available online: https://github.com/pomikalek/jusText (accessed on 4 April 2024).
- Korbak, T.; Elsahar, H.; Kruszewski, G.; Dymetman, M. Controlling Conditional Language Models without Catastrophic Forgetting. arXiv 2022, arXiv:2112.00791. [Google Scholar]
- Ramshaw, L.A.; Marcus, M.P. Text Chunking Using Transformation-Based Learning. arXiv 1995, arXiv:cmp-lg/9505040. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Tedeschi, S.; Maiorca, V.; Campolungo, N.; Cecconi, F.; Navigli, R. WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. In Findings of the Association for Computational Linguistics: EMNLP 2021; Moens, M.-F., Huang, X., Specia, L., Wen-tau Yih, S., Eds.; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 2521–2533. [Google Scholar]
- Martin, L.; Muller, B.; Suárez, P.J.O.; Dupont, Y.; Romary, L.; de La Clergerie, É.V.; Seddah, D.; Sagot, B. CamemBERT: A tasty French language model. arXiv 2019, arXiv:1911.03894. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Delestre, C.; Amar, A. DistilCamemBERT: Une Distillation du Modèle Français CamemBERT. In CAp (Conférence sur l’Apprentissage Automatique), Vannes, France, July 2022. Available online: https://hal.archives-ouvertes.fr/hal-03674695 (accessed on 4 April 2024).
- Nothman, J.; Ringland, N.; Radford, W.; Murphy, T.; Curran, J.R. Learning multilingual named entity recognition from Wikipedia. Artif. Intell. 2013, 194, 151–175. [Google Scholar] [CrossRef]
- Polle, J.B. LSTM Model for Email Signature Detection. Medium, 24 September 2021. Available online: https://medium.com/@jean-baptiste.polle/lstm-model-for-email-signature-detection-8e990384fefa (accessed on 4 April 2024).
Figure 1.
Pipeline.
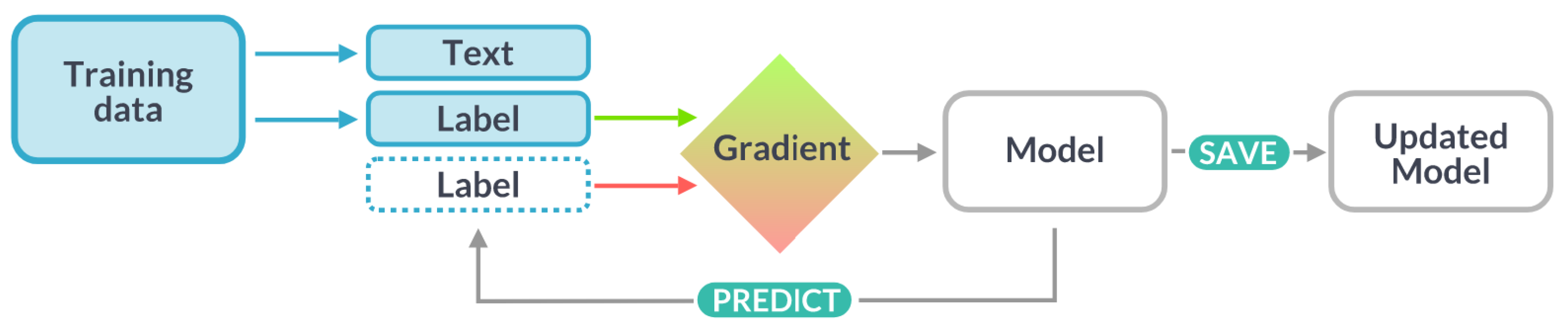
spaCy’s language processing pipeline [3].

Training spaCy’s included models [3].
Correct annotations outside of training data predicted by the trained model.
Figure 4.
Correct annotations outside of training data predicted by the trained model.

Energy domains correctly annotated by the model.
Figure 5.
Energy domains correctly annotated by the model.

Co-occurrence of organizations and technological domains in the same article.
Figure 6.
Co-occurrence of organizations and technological domains in the same article.
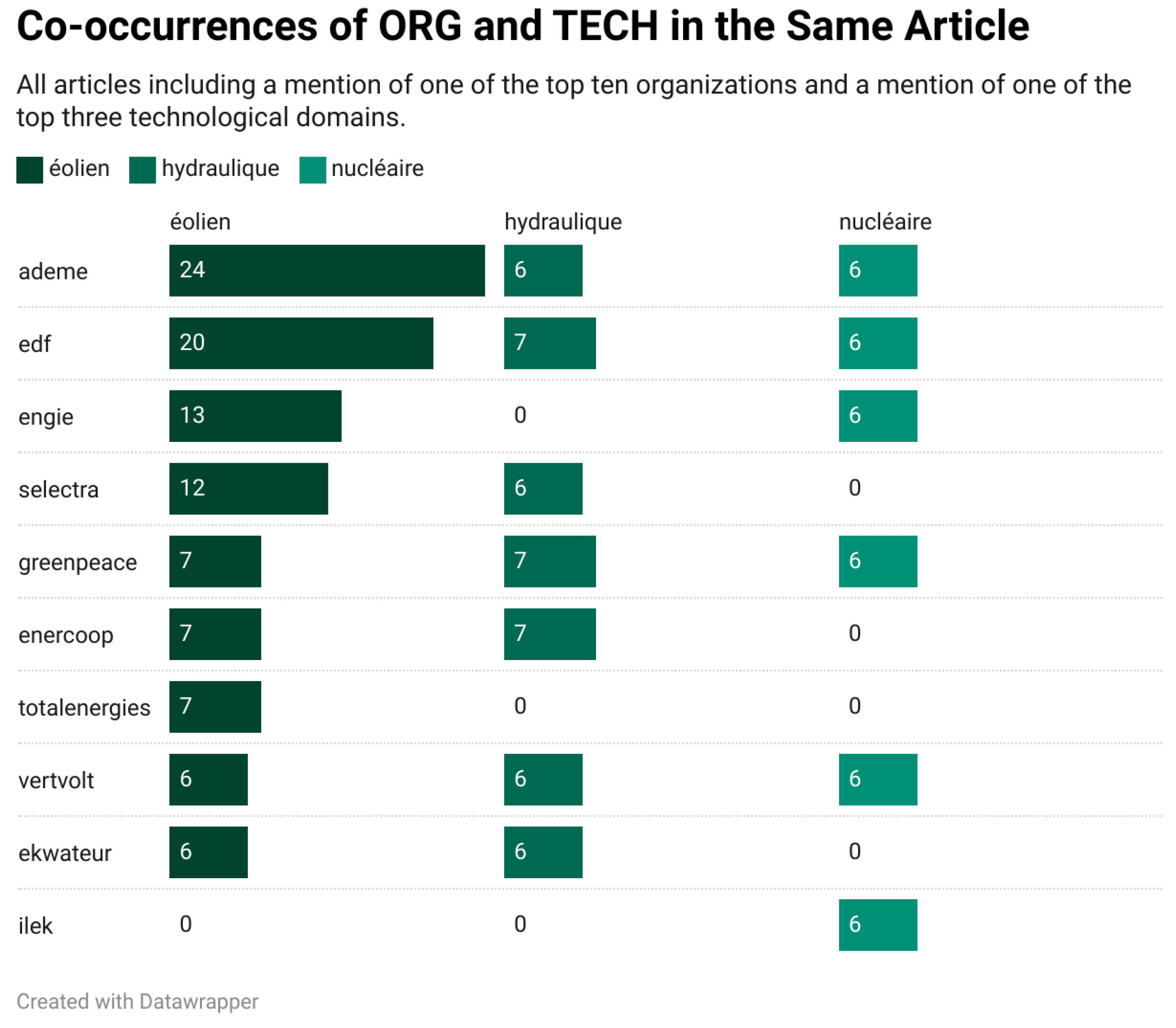
Table 1.
Categories of subjects used in training data.
Table 1.
Categories of subjects used in training data.
| Request | Translation | Number of Articles |
|---|---|---|
| énergies renouvelables | renewable energies | 26 |
| éolienne | wind turbines | 17 |
| hydroélectrique | hydroelectric | 3 |
| startup énergie | energy startup | 3 |
Table 2.
Annotation guidelines.
Table 2.
Annotation guidelines.
| Entity Tag | Description |
|---|---|
| PERSON | proper noun: name of person, position; i.e., President of XXXX, first name + last name |
| LOC | location: city, country, place |
| ORG | proper noun: company, government, committee, etc. |
| TECH | technological field or product; i.e., solar energy, solar panels |
Table 3.
Training dataset.
Table 3.
Training dataset.
| Entity Tag | Count |
|---|---|
| O | 49,773 |
| I-TECH | 1488 |
| B-TECH | 1082 |
| I-ORG | 743 |
| B-ORG | 696 |
| B-LOC | 586 |
| I-LOC | 254 |
| I-PER | 202 |
| B-PER | 196 |
| B-MISC | 1 |
| I-MISC | 1 |
Table 4.
Validation dataset.
Table 4.
Validation dataset.
| Entity Tag | Count |
|---|---|
| O | 12,524 |
| I-TECH | 411 |
| B-TECH | 271 |
| I-ORG | 208 |
| B-ORG | 182 |
| B-LOC | 161 |
| I-LOC | 84 |
| I-PER | 43 |
| B-PER | 40 |
| B-MISC | 1 |
Table 5.
Test dataset.
| Entity Tag | Count |
|---|---|
| O | 9133 |
| B-ORG | 212 |
| I-TECH | 158 |
| B-TECH | 153 |
| I-ORG | 145 |
| B-LOC | 75 |
| I-LOC | 39 |
| I-PER | 30 |
| B-PER | 22 |
Table 6.
Model accuracy of CamemBERT and DistilCamemBERT. All measurements are based on the F1 score.
Table 6.
Model accuracy of CamemBERT and DistilCamemBERT. All measurements are based on the F1 score.
| Model | Sentiment (%) | NER (%) | NLI (%) | QA (%) |
|---|---|---|---|---|
| CamemBERT | 95.74 | 88.93 | 81.68 | 79.57 |
| DistilCamemBERT | 97.57 | 89.12 | 77.48 | 62.65 |
Table 7.
Model F1 score evaluated on independent test data.
Table 7.
Model F1 score evaluated on independent test data.
| Model | F1 Score TECH | F1 Score ORG | F1 Score LOC | F1 Score PER |
|---|---|---|---|---|
| spaCy fr_core_news_lg | 56.67% | 54.35% | 73.53% | 92.68% |
| Babelscape | 58.37% | 71.81% | 76.51% | 89.36% |
| CamemBERT | 91.28% | 89.98% | 91.39% | 100.00% |
| DistilCamemBERT | 66.67% | 74.94% | 63.75% | 88.89% |
| CamemBERT NER | 68.50% | 85.10% | 74.36% | 95.45% |
Table 8.
Performance metrics for different training data proportions.
Table 8.
Performance metrics for different training data proportions.
| Training Data | Entity Type | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| 20% | TECH | 71.63% | 66.01% | 68.71% |
| ORG | 68.78% | 76.89% | 72.61% | |
| LOC | 73.17% | 80.00% | 76.43% | |
| PER | 90.91% | 90.91% | 90.91% | |
| 40% | TECH | 91.35% | 62.09% | 73.93% |
| ORG | 75.95% | 84.91% | 80.18% | |
| LOC | 64.89% | 81.33% | 72.19% | |
| PER | 95.65% | 100.00% | 97.78% | |
| 60% | TECH | 88.71% | 71.90% | 79.42% |
| ORG | 81.55% | 79.25% | 80.38% | |
| LOC | 63.22% | 73.33% | 67.90% | |
| PER | 83.33% | 90.91% | 86.96% | |
| 80% | TECH | 93.79% | 88.89% | 91.28% |
| ORG | 93.40% | 86.79% | 89.98% | |
| LOC | 90.79% | 92.00% | 91.39% | |
| PER | 100.00% | 100.00% | 100.00% |
Table 9.
Articles per query: published between 2 April and 4 April 2024.
Table 9.
Articles per query: published between 2 April and 4 April 2024.
| Query | English Translation | Count |
|---|---|---|
| énergies renouvelables | Renewable energies | 138 |
| startup énergie | Energy startups | 13 |
Table 10.
All organizations mentioned in six or more articles.
Table 10.
All organizations mentioned in six or more articles.
| Company | Number of Articles |
|---|---|
| TotalEnergies | 17 |
| Engie | 17 |
| EDF | 8 |
| Greenpeace | 7 |
| COP28 | 7 |
| Enercoop | 7 |
| Ekwateur | 6 |
| Selectra | 6 |
| ilek | 6 |
| VertVolt | 6 |
Table 11.
All technological domains and products mentioned in six or more articles.
Table 11.
All technological domains and products mentioned in six or more articles.
| Technology | English Translation | Number of Articles |
|---|---|---|
| éolien | wind | 33 |
| solaire | solar | 26 |
| hydraulique | hydraulic | 23 |
| nucléaire | nuclear | 20 |
| panneaux solaires | solar panels | 18 |
| éoliennes | wind turbines | 18 |
| hydroélectricité | hydroelectricity | 17 |
| éolienne | wind turbine | 16 |
| photovoltaïque | photovoltaic | 9 |
| hydrogène | hydrogen | 9 |
| panneaux photovoltaïques | photovoltaic panels | 9 |
| biogaz | biogas | 9 |
| centrale solaire | solar power plant | 8 |
| hydroélectriques | hydroelectric | 8 |
| parcs éoliens | wind farms | 7 |
| hydroélectrique | hydroelectric | 7 |
| centrales nucléaires | nuclear power plants | 7 |
| géothermie | geothermal | 7 |
| l’énergie solaire | solar energy | 6 |
| batteries | batteries | 6 |
| énergie éolienne | wind energy | 6 |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Source link
lol