
In 2018, there were extensive news reports that an Uber self-driving car made an accident with a pedestrian in Tempe, Arizona. The pedestrian died, and investigators found that there was an issue with the machine learning (ML) model in the car, so it failed to identify the pedestrian beforehand.
Image Credits: The New York Times
Read more: https://link.springer.com/chapter/10.1007/978-3-030-12388-8_19
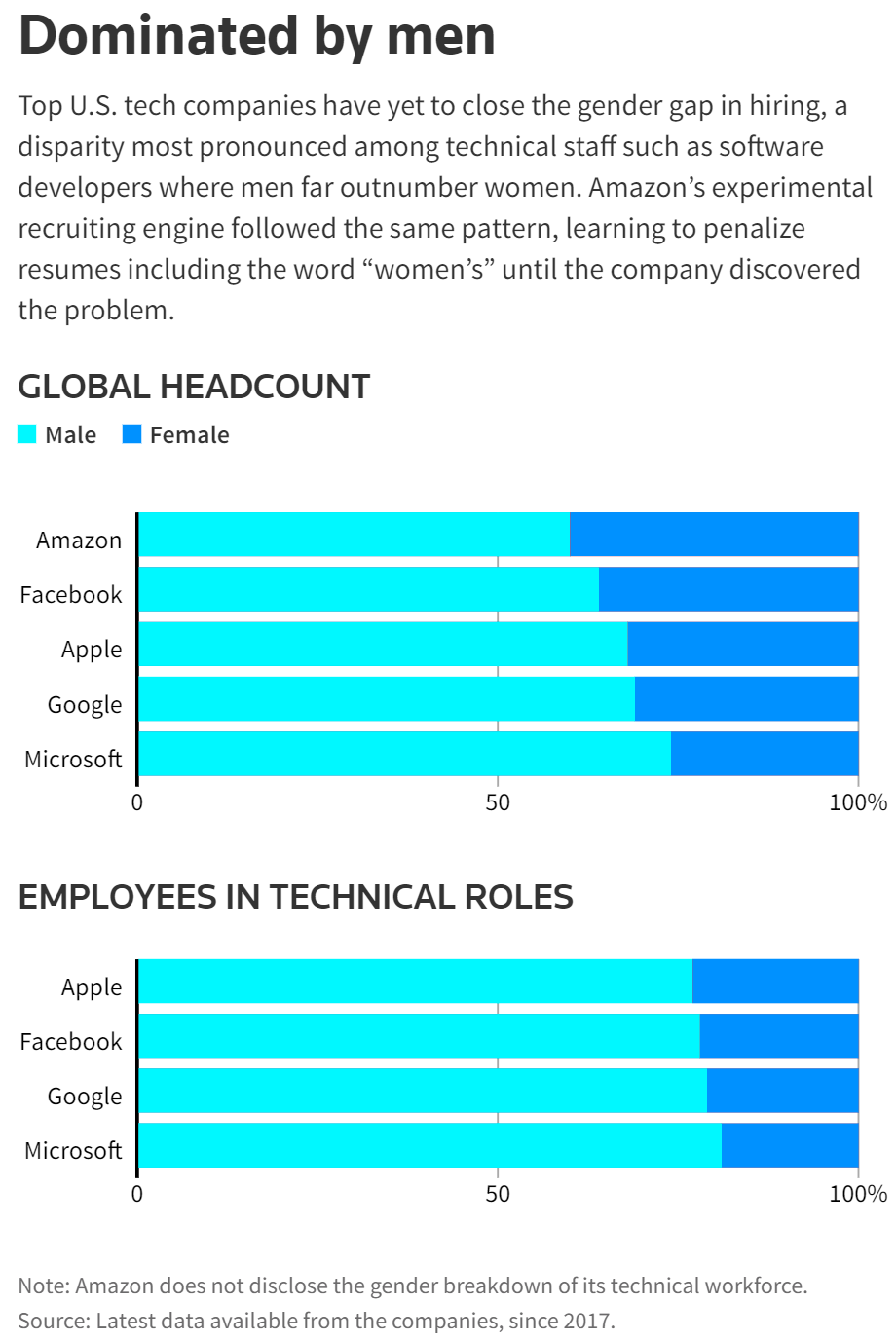
In another 2018 story, Amazon was found to show bias toward male candidates in the recruitment process because of an issue with their AI-powered HR recruiting tool. According to reports, their tool has been trained using a biased data sample sourced from a male-dominated industry.
As a result, Amazon’s tool has learned to show favours to men rather than women. Amazon had to abandon the tool due to potential legal and ethical concerns.
These scenarios indicate that you need to continuously focus on improving the performance of your models through continuous and iterative development. It is not just about enhancing the accuracy of these systems but also about ensuring they are developed and deployed in ethical, equitable, and safe ways. If not, it could lead to negative consequences such as loss of life, perpetuation of biases, and reduced trust in technology.
Therefore, developers need to adopt a proactive approach to fixing such issues. This can be done with rigorous testing and validation of models before deployment and ongoing monitoring and updating to adapt to new challenges and data and further improve their accuracy.
Therefore, let’s examine how you can improve the overall accuracy of your machine learning models so that they perform well and make reliable and safe predictions.
But First, Do You Really Need to Fix Your ML Model?
It is important to conduct an evaluation of your model first and determine if there is a need to enhance the accuracy. The signs are,
- Model predictions deviate a lot from your evaluative benchmarks.
- There’s an increase in false positives within the model’s predictions.
- The model often produces inconsistent results.
If benchmarks are a part of your model’s evaluative process, it is highly advisable to prioritize conducting them first. Read more about benchmarking ML models. https://www.tutorialspoint.com/what-are-the-machine-learning-benchmarks
With benchmark figures, you can crunch numbers and quantitatively analyze the model’s current accuracy level. Then, you may decide whether to apply some techniques to improve it further.
Let’s explore methods to improve the accuracy of an ML model.
Top 5 Methods to Improve the Accuracy of a Machine Learning Model
- Feature Engineering
- Model Selection
- Hyperparameter Tuning
- Ensemble Methods
- Advanced Techniques
Let’s look at each of these techniques and practical examples.
How to Improve ML Model Performance Through Feature Engineering?
The process of using raw data to make accurate representations of ML models that can be understood and learned effectively is referred to as Feature Engineering. This involves several steps, including,
- Feature selection
- Transformation
- Feature extraction
- Feature engineering
Consider predicting a person’s weight based on their height and age. While height and age are relevant features, they may not fully capture the underlying relationship with weight. By creating a new feature called “body mass index” (BMI), which combines height and weight in a specific formula, you can provide a more informative representation of the model. This is an example of transforming available data sets to derive new features by combining multiple attributes and, more broadly, feature engineering.
Feature engineering improves model accuracy by introducing variables that encapsulate crucial and complex data relationships. For instance, the creation of BMI from height and weight directly integrates two influential factors into a single predictive feature. This feature combination not only simplifies the model’s input by reducing feature set dimensionality but also highlights interactions that might not be evident when considering these features independently.
By doing so, feature engineering allows the model to focus on more relevant attributes, reducing noise and improving the model’s ability to generalize from the training data to real-world scenarios. This reassures you about the reliability and robustness of your predictive models, thereby boosting predictive accuracy.
Choosing the Right Tool for the Job: Model Selection
Machine learning models have a dedicated purpose and are designed to solve different types of problems. Some models are better at predicting, such as identifying spam messages or emails; these types of tasks are called classification tasks. Other models may specialize in regression tasks such as forecasting stock prices. So, picking the suitable model that fits your needs is essential.
How do you choose an appropriate ML model?
- Problem Type
You can mainly identify the ML mode by considering the type of problem you will solve.
With Machine Learning, you can solve two main types of problems. These are:
1. Classification
2. Regression
A classification problem helps a model predict a categorical output. For example, you might want to build a ML model that determines if an email is spam or not. This can be done by training machine learning algorithms such as logistic regression, decision trees, random forests, and support vector machines on a dataset containing categorical outputs.
On the other hand, a regression problem helps you predict a continuous value. For example, this could be the weather based on past weather information or a particular stock’s price. This can be done by training continuous data over algorithms like linear regression, logistic regression, random forests, and neural networks.
2. Number of Features vs. Samples
Next, you’d need to consider the number of features and sample size before determining the suitable model to use. Some models perform well with low data points, while others require thousands of data points for optimal results. Additionally, some algorithms don’t perform well with a high number of features, while some do.
So, if you have a large number of features but fewer samples, consider using an algorithm like a decision tree or a linear model. For example, if you were training a model with data for gene expression in bioinformatics, there would be thousands of genes (features) but relatively few samples. In such cases, you’d benefit more from a decision tree or a linear model.
On the other hand, if you were building a model that has a large data set with complex features, such as a dataset consisting of images, you’d benefit from training it on a neural network, as these algorithms are capable of understanding and analyzing complex feature sets.
3. Linearity of Relationships
This factor refers to the nature of the relationships between the features (input variables) and the target variable (output) in your data. You can group the linearity of relationships into two types.
For example, if there is a linear relationship between your target and features, consider using a model such as linear regression, logistic regression, or support vector machines(SVM). This is particularly useful in linear relationships, like predicting a car’s fuel consumption considering its engine capacity and weight.
But if there is a non-linear or complex relationship between your target and features, consider using a model such as decision trees, random forests, gradient boosting machines, and neural networks. This is particularly useful for scenarios where you’d want to predict rainfall at a specific location based on various indicators and historical data that follow non-linear relationships.
4. Handling Categorical Features
Proper handling of categorical features when training a model is important, as it can impact the accuracy of predictions.
Some algorithms natively handle categorical features very well. These algorithms are mostly tree-based, like a Decision Tree or a Random Forest. They are best suited for use cases like predicting customer churn rates based on features like subscription category and account age.
On the other hand, specific algorithms, such as linear regression, logistic regression, or support vector machines, require preprocessed categorical features through techniques like one-hot encodings. These algorithms are best suited for use cases like credit risk assessment, which considers employment status, education level, and marital status. Such categorical features should be one-hot encoded before being used in ML models.
5. Interpretability vs. Accuracy
Some models are best suited for their interpretability, while others are preferred for their accuracy, even if they are less interpretable.
For example, when it comes to assessing loan risk, models like linear regression, logistic regression, and decision trees are popular choices. These models are straightforward, and their decisions are easy to understand, which is essential for meeting regulatory and legal requirements.
On the other hand, for applications like recommender systems, where understanding the exact reasoning behind each decision isn’t as crucial, more complex models such as random forests, gradient boosting machines, and neural networks are often used. These models can deliver higher accuracy, but their inner workings are more complex and harder to interpret.
Following the above guide, you can shortlist potential ML models and pick the ideal candidate for your specific needs. This will significantly increase the ML model’s accuracy and deliver a robust output.
Hyperparameter Tuning: Fine-Tuning The Model
Another step to improving accuracy is fine-tuning the parameters controlling the algorithm’s behaviour. We call these parameters “hyperparameters.” They also play an important role in the performance aspect of the ML model.
Hyperparameters can range from the learning rate in neural networks to the depth of decision trees or linear models’ regularisation strength.
To fine-tune these Hyperparameters, you can employ hyperparameter tuning techniques. There are two common approaches.
- Grid Search
This technique needs to determine a grid of possible values for each hyperparameter and deeply evaluate the ML model performance for every combination of these values. However, grid search can be computationally expensive, especially for models with many hyperparameters or large datasets.
2. Random Search:
This method randomly samples combinations of hyperparameter values from a predefined data sample. It is way more efficient than grid search, especially when some hyperparameters are more influential than others.
However, grid search typically finds the best set of hyperparameters. The Random search might leave large regions unexplored.
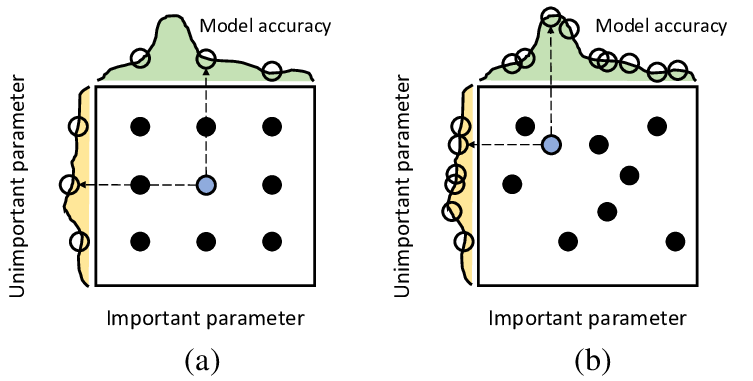
Comparison between (a) Grid search and (b) Random search (Image Credits: ResearchGate)
Hyperparameter tuning is common in CNN models designed for computer vision applications. Factors like the number of layers, filter sizes, and learning rates can greatly impact the model’s performance and accuracy.
Improving ML Model Performance with Ensemble Methods
Ensemble methods train several base models and then strategically combine their predictions. Rather than relying on a single model, incorporating multiple models helps enhance the model’s performance and accuracy rather than relying on a single model. However, it would help if you were super careful when applying ensemble techniques, as incorrect applications may further negatively impact the ML model’s accuracy.
There are two popular ensemble techniques.
- Bagging (aka Bootstrap Aggregating) is a technique in which multiple ML models are developed on different subsets of the data through resampling with replacement. Random Forests for classification and regression tasks are suitable for this technique.
- Boosting is another technique that sequentially trains weak models on data examples that previous models struggled with, combining them into a strong ensemble. Gradient Boosting Machines (GBMs) and AdaBoost approaches have shown success in applications like fraud detection and customer churn prediction.
It has been industry proven that the ensemble methods can achieve higher ML model accuracy, compared to individual models, making them a powerful tool for various real-world ML applications.
Beyond the Basics: Advanced Techniques to Improve ML Model Performance
There are several advanced techniques that you can apply to further improve the accuracy of your ML model. Below are some of the advanced techniques to consider.
- Transfer learning is an approach that involves reusing knowledge from pre-trained models on large datasets and applying it to another related task, potentially improving accuracy and reducing training time. This is highly used in the computer vision field. Pre-trained models like ResNet can be fine-tuned for specific applications, such as medical image analysis or self-driving cars, following this technique.
- Active learning is the other approach. In this approach, the ML model selects the most informative data points for human labeling, increasing the value of each labeled instance and improving accuracy, especially when labeled data is rare. ML models for text classifications and object recognition use this technique extensively.
- Cross-validation techniques, such as nested cross-validation or stratified cross-validation, can provide more reliable error estimates and help prevent overfitting. This ensures that the model’s performance generalizes well to unseen data.
These advanced techniques, combined with other methods mentioned in this article, can significantly enhance the accuracy and robustness of machine learning models across various domains.
Wrapping Up
This article explored several ways to improve the accuracy of machine learning models and provided guidelines on the proper technique to adopt for your use case.
To unleash the true potential of ML models, it is important to prioritize high-quality data collection, use effective data cleaning and preprocessing techniques, and leverage data augmentation strategies when necessary.
Following these steps, you can create more accurate and efficient machine learning models that provide valuable insights and solutions to various problems.
Thank you for reading.
Source link
lol