
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. We envision a future where AI seamlessly integrates into our teams’ workflows, automating repetitive tasks, providing intelligent recommendations, and freeing up time for more strategic, high-value interactions. Our field organization includes customer-facing teams (account managers, solutions architects, specialists) and internal support functions (sales operations).
Prospecting, opportunity progression, and customer engagement present exciting opportunities to utilize generative AI, using historical data, to drive efficiency and effectiveness. Personalized content will be generated at every step, and collaboration within account teams will be seamless with a complete, up-to-date view of the customer. Our internal AI sales assistant, powered by Amazon Q Business, will be available across every modality and seamlessly integrate with systems such as internal knowledge bases, customer relationship management (CRM), and more. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
Through this series of posts, we share our generative AI journey and use cases, detailing the architecture, AWS services used, lessons learned, and the impact of these solutions on our teams and customers. In this first post, we explore Account Summaries, one of our initial production use cases built on Amazon Bedrock. Account Summaries equips our teams to be better prepared for customer engagements. It combines information from various sources into comprehensive, on-demand summaries available in our CRM or proactively delivered based on upcoming meetings. From the period of September 2023 to March 2024, sellers leveraging GenAI Account Summaries saw a 4.9% increase in value of opportunities created.
The business opportunity
Data often resides across multiple internal systems, such as CRM and financial tools, and external sources, making it challenging for account teams to gain a comprehensive understanding of each customer. Manually connecting these disparate datasets can be time-consuming, presenting an opportunity to improve how we uncover valuable insights and identify opportunities. Without proactive insights and recommendations, account teams can miss opportunities and deliver inconsistent customer experiences.
Use case overview
Using generative AI, we built Account Summaries by seamlessly integrating both structured and unstructured data from diverse sources. This includes sales collateral, customer engagements, external web data, machine learning (ML) insights, and more. The result is a comprehensive summary tailored for our sellers, available on-demand in our CRM and proactively delivered through Slack based on upcoming meetings.
Account Summaries provides a 360-degree account narrative with customizable sections, showcasing timely and relevant information about customers. Key sections include:
- Executive summary – A concise overview highlighting the latest customer updates, ideal for quick, high-level briefings.
- Organization overview – Analysis of external organization and industry news along with citations to sources, providing account teams with timely discussion topics and positioning strategies.
- Product consumption – Summaries of how customers are using AWS services over time.
- Opportunity pipeline – Overview of open and stalled opportunities, including partner engagements and recent customer interactions.
- Investments and support – Information on customer issues, promotional programs, support cases, and product feature requests.
- AI-driven recommendations – By combining generative AI with ML, we deliver intelligent suggestions for products, services, applicable use cases, and next steps. Recommendations include citations to source materials, empowering account teams to more effectively drive customer strategies.
The following screenshot shows a sample account summary. All data in this example summary is fictitious.
Solution impact
Since its inception in 2023, more than 100,000 GenAI Account Summaries have been generated, and AWS sellers report an average of 35 minutes saved per GenAI Account Summary. This is boosting productivity and freeing up time for customer engagements. The impact goes beyond just efficiency. Since its inception in September 2023 up through March 2024, approximately one-third of surveyed sellers reported that GenAI Account Summaries had a positive impact on their approach to a customer, and sellers leveraging GenAI Account Summaries saw a 4.9% increase in value of opportunities created.
The impact of this use case has been particularly pronounced among teams who support a large number of customers. Users such as specialists who move between multiple accounts have seen a dramatic improvement in their ability to quickly understand and add value to diverse customer situations. During account transitions, they enable new account managers to rapidly get up to date on inherited accounts. At events, our teams now approach customer interactions armed with comprehensive, up-to-date information on demand. Account Summaries is also now foundational to other downstream mechanisms like account planning and executive briefing center (EBC) meetings.
Solution overview
This illustrates our approach to implementing generative AI capabilities across the sales and customer lifecycle. It’s built on diverse data sources and a robust infrastructure layer for data retrieval, prompting, and LLM management. This modular structure provides a scalable foundation for deploying a broad range of AI-powered use cases, beginning with Account Summaries.
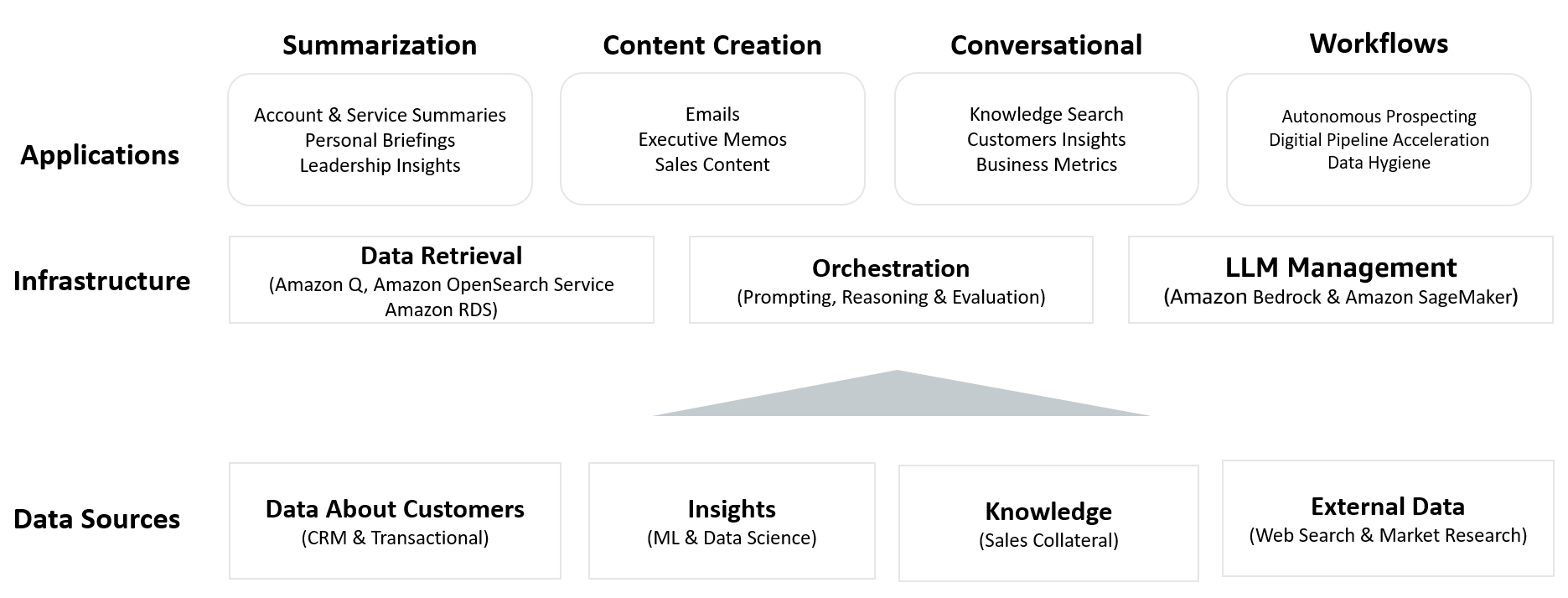
Building generative AI solutions like Account Summaries on AWS offers significant technical advantages, particularly for organizations already using AWS services. You can integrate existing data from AWS data lakes, Amazon Simple Storage Service (Amazon S3) buckets, or Amazon Relational Database Service (Amazon RDS) instances with services such as Amazon Bedrock and Amazon Q. For our Account Summaries use case, we use both Amazon Titan and Anthropic Claude models on Amazon Bedrock, taking advantage of their unique strengths for different aspects of summary generation.
Our approach to model selection and deployment is both strategic and flexible. We carefully choose models based on their specific capabilities and the requirements of each summary section. This allows us to optimize for factors such as accuracy, response time, and cost-efficiency. The architecture we’ve developed enables seamless combination and switching between different models, even within a single summary generation process. This multi-model approach lets us take advantage of the best features of each model, resulting in more comprehensive and nuanced summaries.
This flexible model selection and combination capability, coupled with our existing AWS infrastructure, accelerates time to market, reduces complex data migrations and potential failure points, and allows us to continuously incorporate state-of-the-art language models as they become available.
Our system integrates diverse data sources with sophisticated data indexing and retrieval processes, and utilizes carefully crafted prompting techniques. We’ve also implemented robust strategies to mitigate hallucinations, providing reliability in our generated summaries. Built on AWS with asynchronous processing, the solution incorporates multiple quality assurance measures and is continually refined through a comprehensive feedback loop, all while maintaining stringent security and privacy standards.
In the following sections, we review each component, including data sources, data indexing and retrieval, prompting strategies, hallucination mitigation techniques, quality assurance processes, and the underlying infrastructure and operations.
Data sources
Account Summaries relies on four key categories of information:
- Data about customers – Structured information about the customer’s AWS journey, including service metrics, growth trends, and support history
- ML insights – Insights generated from analyzing patterns in structured business data and unstructured interaction logs
- Internal knowledge bases – Unstructured data like sales plays, case studies, and product information, continuously updated to reflect the latest AWS offerings and best practices
- External data – Real-time news, public financial filings, and industry reports to offer a comprehensive understanding of the customer’s business landscape
By bringing together these diverse data sources, we create a rich, multidimensional view of each account that goes beyond what’s possible with traditional data analysis.
To maintain the integrity of our core data, we do not retain or use the prompts or the resulting account summary for model training. Instead, after a summary is produced and delivered to the seller, the generated content is permanently deleted.
Data indexing and retrieval
We start with indexing and retrieving both structured and unstructured data, which allows us to provide comprehensive summaries that combine quantitative data with qualitative insights.
The indexing process consists of the following stages:
- Document preprocessing – Clean and normalize text from various sources
- Chunking – Break documents into manageable pieces (1,200 tokens with 50-token overlap)
- Vectorization – Convert text chunks into vector representations using an embeddings model
- Storage – Index vectors and metadata in the database for quick retrieval
The retrieval process comprises the following stages:
- Query vectorization – Convert user queries or context into vector representations
- Similarity search – Use k-nearest neighbors (k-NN) to find relevant document chunks
- Metadata filtering – Apply additional filters based on structured data (such as date ranges or product categories)
- Reranking – Use a cross-encoder model to refine the relevance of retrieved chunks
- Context integration – Combine retrieved information with the large language model (LLM) prompt
The following are key implementation considerations:
- Balancing structured and unstructured data – Using structured data to guide and filter searches within unstructured content, and combining quantitative metrics with qualitative insights for comprehensive summaries
- Scalability – Designing our system to handle increasing volumes of data and concurrent requests, and considering partitioning strategies for our growing vector database
- Maintaining data freshness – Implementing strategies to regularly update our index with new information and considered real-time indexing for critical, fast-changing data points
- Continuous relevance tuning – Ongoing refinement of our retrieval process based on user feedback and performance metrics, and experimentation with different embedding models and similarity measures
- Privacy and security – Using row-level security access controls to limit user access to information
By thoughtfully implementing this indexing and retrieval system, we’ve created a powerful foundation for Account Summaries. This approach allows us to dynamically combine structured internal business data with relevant unstructured content, providing our field teams with comprehensive, up-to-date, and context-rich summaries for every customer engagement.
Prompting
Well-crafted prompts enhance the accuracy and relevance of generated responses, reduce hallucinations, and allow for customization based on specific use cases. Ultimately, prompting serves as the critical interface that makes sure Retrieval Augmented Generation (RAG) systems produce coherent, factual, and tailored outputs by effectively using both stored knowledge and the capabilities of LLMs. Prompting plays a crucial role in RAG systems by bridging the gap between retrieved information and user intent. It guides the retrieval process, contextualizes the fetched data, and instructs the language model on how to use this information effectively.
The following diagram illustrates the prompting framework for Account Summaries, which begins by gathering data from various sources. This information is used to build a prompt with relevant context and then fed into an LLM, which generates a response. The final output is a response tailored to the input data and refined through iteration.
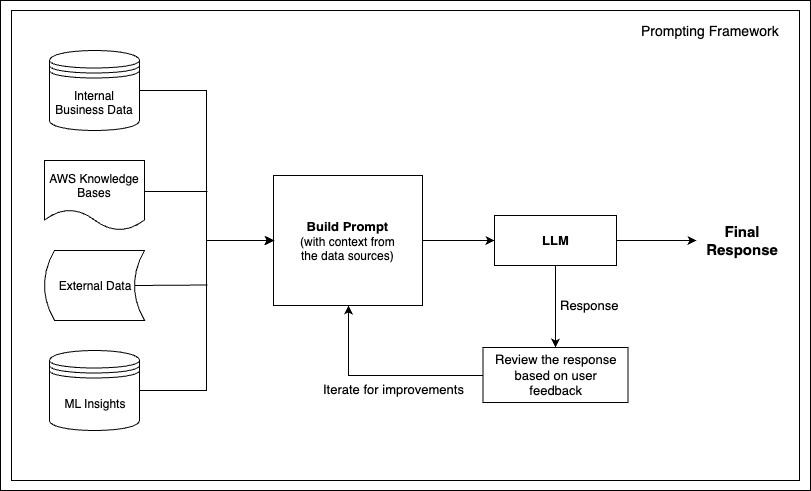
We organize our prompting best practices into two main categories:
- Content and structure:
- Constraint specification – Define content, tone, and format constraints relevant to AWS sales contexts. For example, “Provide a summary that excludes sensitive financial data and maintains a formal tone.”
- Use of delimiters – Employ XML tags to separate instructions, context, and generation areas. For example, <instructions> Please summarize the key points from the following passage: </instructions> <data> [Insert passage here] </data>.
- Modular prompts – Split prompts into section-specific chunks for enhanced accuracy and reduced latency, because it allows the LLM to focus on a smaller context at a time. For example, “Separate prompts for executive summary and opportunity pipeline sections.”
- Role context – Start each prompt with a clear role definition. For example, “You are an AWS Account Manager preparing for a customer meeting.”
- Language and tone:
- Professional framing – Use polite, professional language in prompts. For example, “Please provide a concise summary of the customer’s cloud adoption journey.”
- Specific directives – Include unambiguous instructions. For example, “Summarize in one paragraph” rather than “Provide a short summary.”
- Positive framing – Frame instructions positively. For example, “Write a professional email” instead of “Don’t be unprofessional.”
- Clear restrictions – Specify important limitations upfront. For example, “Respond without speculating or guessing. Don’t make up any statistics.”
Consider the following system design and optimization techniques:
- Architectural considerations:
- Multi-stage prompting – Use initial prompts for data retrieval, followed by specific prompts for summary generation.
- Dynamic templates – Adapt prompt templates based on retrieved customer information.
- Model selection – Balance performance with cost, choosing appropriate models for different summary sections.
- Asynchronous processing – Run LLM calls for different summary sections in parallel to reduce overall latency.
- Quality and improvement:
- Output validation – Implement rigorous fact-checking before relying on generated summaries. For example, “Cross-reference generated figures with golden source business data.”
- Consistency checks – Make sure instructions don’t contradict each other or the provided data. For example, “Review prompts to ensure we’re not asking for detailed financials while also instructing to exclude sensitive data.”
- Step-by-step thinking – For complex summaries, instruct the model to think through steps to reduce hallucinations.
- Feedback and iteration – Regularly analyze performance, gather user feedback, experiment, and iteratively improve prompts and processes.
Multi-model approach
Although crafting effective prompts is crucial, equally important is selecting the right models to process these prompts and generate accurate, relevant summaries. Our multi-model approach is key to achieving this goal. By using multiple models, specifically Amazon Titan and Anthropic Claude on Amazon Bedrock, we’re able to optimize various aspects of summary generation, resulting in more comprehensive, accurate, and tailored outputs.
The selection of appropriate models for different tasks is guided by several key criteria. First, we evaluate the specific capabilities of each model, looking at their unique strengths in handling certain types of queries or data. Next, we assess the model’s accuracy, which is its ability to generate factual and relevant content. And lastly, we consider speed and cost, which are also crucial factors.
Our architecture is designed to allow for flexible model switching and combination. This is achieved through a modular approach where each section of the summary can be generated independently and then combined into a cohesive whole. With continuous performance monitoring and feedback mechanisms in place, we are able to refine our model selection and prompting strategies over time.
As new models become available on Amazon Bedrock, we have a structured evaluation process in place. This involves benchmarking new models against our current selections across various metrics, running A/B tests, and gradually incorporating high-performing models into our production pipeline.
Mitigating hallucinations and enforcing quality
LLMs sometimes hallucinate because they optimize for the most probable text response to a prompt, balancing various elements like syntax, grammar, style, knowledge, reasoning, and emotion. This often leads to trade-offs, resulting in the insertion of invented facts, making the outputs seem convincing but inaccurate. We implemented several strategies to address common types of hallucinations:
- Incomplete data issue – LLMs may invent information when lacking necessary context.
- Solution – We provide comprehensive datasets and explicit instructions to use only provided information. We also preprocess data to remove null points and include conditional instructions for available data points.
- Vague instructions issue – Ambiguous prompts can lead to guesswork and hallucinations.
- Solution – We use detailed, specific prompts with clear and structured instructions to minimize ambiguity.
- Ambiguous context issue – Unclear context can result in plausible but inaccurate details.
- Solution – We clarify context in prompts, specifying exact details required and using XML tags to distinguish between context, tasks, and instructions.
We deployed a multi-faceted approach to provide quality and accuracy with Account Summaries:
- Automated metrics – These automated metrics provide a quantitative foundation for our quality assurance process, allowing us to quickly identify potential issues in generated summaries before they undergo human review:
- Cosine similarity – Measures the similarity between the input dataset and the generated response by calculating the cosine of the angle between their vector representations. This helps make sure the summary content aligns closely with the input data.
- BLEU (Bilingual Evaluation Understudy) – Evaluates the quality of the response by calculating how many n-grams in the response match those in the input data. It focuses on precision, measuring how much of the generated content is present in the reference data.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) – Compares words and phrases present in both the response and input data, assessing how much relevant information from the input is included in the response.
- Numbers checking – Identifies numerical data in both the input and generated documents, determining their intersection and flagging potential hallucinations. This helps catch any fabricated or misrepresented quantitative information in the summaries.
- Human review – The final outputs and the intermediate steps, including prompt formulations and data preprocessing, are part of the human review process. This includes evaluating a set of responses, checking for accuracy, hallucinations, completeness, adherence to constraints, and compliance with security and legal requirements. This collaborative approach makes sure Account Summaries meets the specific needs of our field teams, accurately represents AWS services, and responsibly handles customer information. Our human review process is comprehensive and integrated throughout the development lifecycle of the Account Summaries solution, involving a diverse group of stakeholders:
- Field sellers and the Account Summaries product team – These personas collaborate from the early stages on prompt engineering, data selection, and source validation. AWS data teams make sure the information used is accurate, up to date, and appropriately utilized.
- Application security (AppSec) teams – These teams are engaged to guide, assess, and mitigate potential security risks, making sure the solution adheres to AWS security standards.
- End-users – End-users are required to review content created by the LLM for accuracy prior to using the content.
- Continuous feedback loop – We’ve implemented a robust, multi-channel feedback system to continuously improve Account Summaries:
- In-app feedback – Users can provide feedback at both the summary and individual section levels, allowing for granular insights into the effectiveness of different components.
- Daily seller interactions – Our teams engage in regular conversations (one-on-one and through a dedicated Slack channel) with our field teams, gathering real-time feedback and requests for new features and datasets.
- Proactive follow-up – We personally reach out to and close the loop with every single instance of negative feedback, building trust and creating a cycle of continuous feedback.
This feeds into our refinement process for existing summaries and plays a crucial role in prioritizing our product roadmap. We also make sure this feedback reaches the relevant teams across AWS that manage data and insights. This allows them to address any issues with their models, augment datasets, or refine their insights based on real-world usage and field team needs. Given that our generative AI solution brings together data from various sources, this feedback loop is crucial for improving not just Account Summaries, but also the underlying data and models that feed into it. This approach has been instrumental in maintaining high user satisfaction, driving continuous improvement of Account Summaries.
Infrastructure and operations
The robustness and efficiency of our Account Summaries solution are underpinned by an architecture that uses AWS services to provide scalability, reliability, and security while optimizing for performance. Key components include asynchronous processing to manage response times, a multi-tiered approach to handling requests, and strategic use of services like AWS Lambda and Amazon DynamoDB. We’ve also implemented comprehensive monitoring and alerting systems to maintain high availability and quickly address any issues. The following diagram illustrates this architecture.
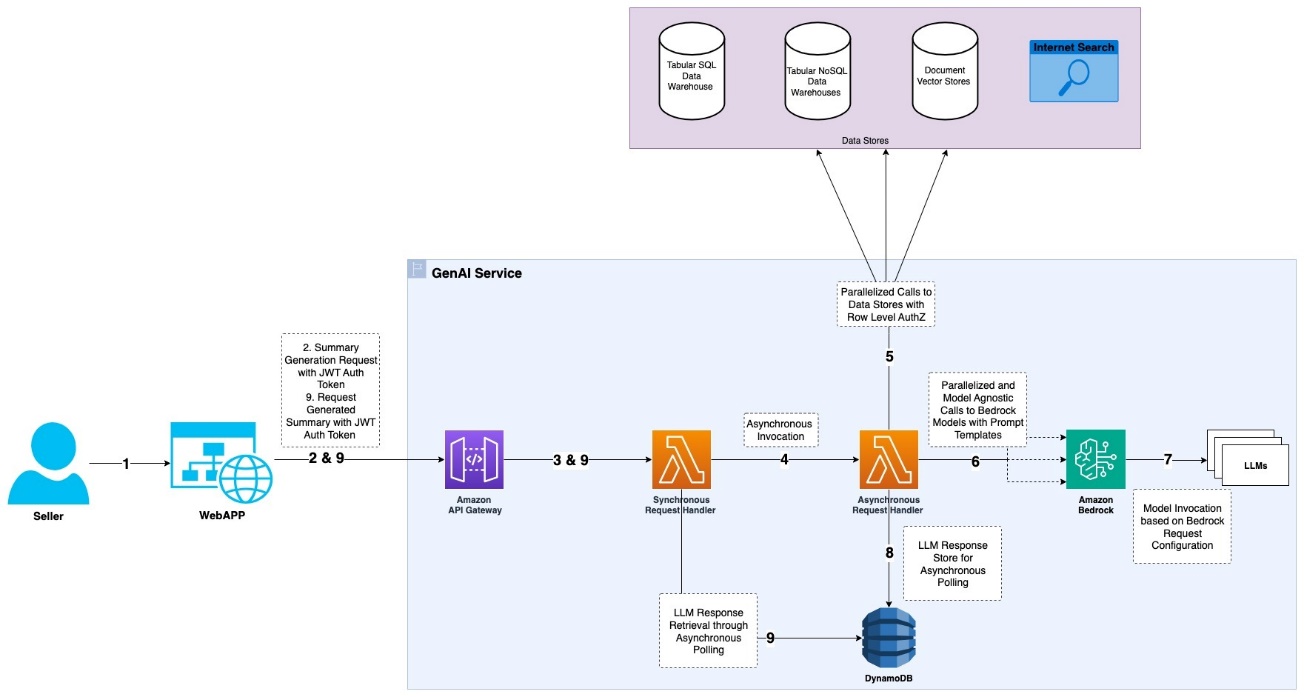
In the following subsections, we outline our API design, authentication mechanisms, response time optimization strategies, and operational practices that collectively enable us to deliver high-quality, timely account summaries at scale.
API design
Account summary generation requests are handled asynchronously to eliminate client wait times for responses. This approach addresses potential delays from downstream data sources and Amazon Bedrock, which can extend response times to several seconds. Two Lambda functions manage a seller’s summarization request: Synchronous Request Handler and Asynchronous Request Handler.
When a seller initiates a summarization request through the web application interface, the request is routed to the Synchronous Request Handler Lambda function. The function generates a requestId, validates the input provided by the seller, invokes the Asynchronous Request Handler function asynchronously, and sends an acknowledgment to the seller along with the requestId for tracking the request’s progress.
The Asynchronous Request Handler function gathers data from various data sources in parallel. It then invokes the Amazon Bedrock LLM in parallel, using the LLM model configuration and a prompt template populated with the gathered data. Amazon Bedrock invokes the appropriate LLM models based on the configuration to generate summarized content. For this use case, we utilize both the Amazon Titan and Anthropic Claude models, taking advantage of their unique strengths for different aspects of the summary generation. The Asynchronous Request Handler function stores results in a DynamoDB database along with the generated requestId.
Finally, the web application periodically polls for the summarized account summary using the generated requestId. The Synchronous Request Handler function retrieves the summarized content from DynamoDB and responds to the seller with the summary when the request is satisfied.
Authentication
The seller is authenticated in the web application using a centralized authentication system. All requests to the generative AI service are accompanied by a JWT, generated from the authentication system. The user’s authorization to access the generative AI service is based on their identity, which is verified using the JWT. When the generative AI service gathers data from various data sources, it uses the user’s identity, using row-level security by restricting access to only the data that the user is authorized to access.
Response time optimization
To enhance response times, we utilize a smaller LLM model such as Anthropic Claude Instant on Amazon Bedrock, which is known for its faster response rates. Larger models are reserved for prompts requiring more in-depth insights. The account summary is composed of multiple sections, each generated by running several prompts independently and in parallel. Data fetching for these prompts is also conducted in parallel to minimize response time.
Operational practices
All failures within the account summary are tracked through operational metrics dashboards and alerts. On-call schedules are in place to address these issues promptly. The team continuously monitors and strives to improve response times. For each major feature release, load tests are conducted to make sure predicted request rates remain within the limits for all downstream resources.
Building a production use case: Lessons learned
Our experience with implementing generative AI at scale offers valuable insights for organizations embarking on a similar journey:
- Pick the right first use case – One of the most common questions we’ve received is how we prioritized and landed on where to start. Although this may seem trivial, in retrospect it had a significant impact in earning trust with the organization. Launching a transformative technology like this at scale needs to be successful—and for that, it must be “correct” and useful.
- Prioritize use cases effectively – We evaluated using the following factors:
- Business impact – There are many interesting applications of generative AI, but we prioritized this use case because field teams spend a significant amount of time researching information and knew that even small improvements at scale would have significant impact.
- Data availability – The most critical aspect of any generative AI use case is the quality and reliability of the underlying data. We identified and assessed the availability and trustworthiness of the data sources required for Account Summaries, making sure it was accurate, up to date, and had the right access permissions in place. We also started with the data we already had, and over time integrated additional datasets and brought in external data.
- Tech readiness – We evaluated the maturity and capabilities of the generative AI technologies available to us at the time. LLMs had demonstrated exceptional performance in tasks such as text summarization and generation, which aligned perfectly with the requirements of Account Summaries.
- Foster continuous learning – In the early stages of our generative AI journey, we encouraged our teams to experiment and build prototypes across various domains. This hands-on experience allowed our developers and data scientists to gain practical knowledge and understanding of the capabilities and limitations of generative AI. We continue this tradition even today because we know how fast new capabilities are being developed and we need our teams to keep pace with this change so we can build the best products for our field teams.
- Embrace iterative development – Generative AI product development is inherently iterative, requiring a continuous cycle of experimentation and refinement. Our development process revolved around crafting and fine-tuning prompts that would generate accurate, relevant, and actionable insights. We engaged in extensive prompt engineering, experimenting with different prompt structures, models, and output formats to achieve the desired results.
- Implement effective enablement and change management – We implemented a phased approach to deployment, starting with a small group of early adopters and gradually expanding to the wider organization. We established channels for users to provide feedback, report issues, and suggest improvements, fostering a culture of continuous improvement. We focused on nurturing a culture that embraces AI-assisted work, emphasizing that the technology is a tool to enhance field capabilities.
- Establish clear metrics and KPIs – We defined specific, measurable outcomes to gauge the success of Account Summaries. These metrics included user adoption rates, retention, time saved per summary generated, and impact on customer engagements. Regular assessment of these key performance indicators (KPIs) guided our ongoing development efforts.
- Foster cross-functional collaboration – The success of our Account Summaries solution relied heavily on collaboration between various teams, including data scientists, engineers, and sales representatives across AWS. This cross-functional approach make sure all aspects of the solution were thoroughly considered and optimized.
Conclusion
This post is the first in a series that explores how generative AI and ML are revolutionizing our field teams’ work and customer engagements. In upcoming posts, we dive into various use cases that transform different aspects of the sales journey, including:
- AI sales assistant powered by Amazon Q – We’ll explore our AI sales assistant, available across different modalities and seamlessly integrating with our other systems. You’ll learn how it answers questions, generates content, and facilitates bidirectional interactions, all while continuously using internal and external data to deliver timely, personalized insights.
- Autonomous agents for prospecting and customer engagement – We’ll showcase how AI-powered agents are transforming prospecting, opportunity progression, and customer engagement to drive efficiency and effectiveness.
We’re excited about the potential of these technologies to automate tasks, provide recommendations, and free up time for strategic interactions. We encourage you to explore these possibilities, experiment with AWS AI services, and embark on your own transformation journey. Stay tuned for our upcoming posts, where we’ll continue to unfold the story of how AI is reshaping the Sales & Marketing organization at AWS.
About the Authors

Rupa Boddu is the Principal Tech Product Manager leading Generative AI strategy and development for the AWS Sales and Marketing organization. She has successfully launched AI/ML applications across AWS and collaborates with executive teams of AWS customers to shape their AI strategies. Her career spans leadership roles across startups and regulated industries, where she has driven cloud transformations, led M&A integrations, and held global leadership positions encompassing COO responsibilities, sales, software development, and infrastructure.
 Raj Aggarwal is the GM of GenAI & Revenue Acceleration for the AWS GTM organization. Raj is responsible for developing the Gen AI strategy and products to transform field functions, GTM motions, and the seller and customer journeys across the global AWS Sales & Marketing organization. His team has built and launched high-impact, production applications at-scale, and served as a key design partner for many of Amazon’s GenAI products. Prior to this, Raj built and exited two companies. As Founder/CEO of Localytics, the leading mobile analytics & messaging provider, he grew it to $25M ARR with 200+ employees.
Raj Aggarwal is the GM of GenAI & Revenue Acceleration for the AWS GTM organization. Raj is responsible for developing the Gen AI strategy and products to transform field functions, GTM motions, and the seller and customer journeys across the global AWS Sales & Marketing organization. His team has built and launched high-impact, production applications at-scale, and served as a key design partner for many of Amazon’s GenAI products. Prior to this, Raj built and exited two companies. As Founder/CEO of Localytics, the leading mobile analytics & messaging provider, he grew it to $25M ARR with 200+ employees.
 Asa Kalavade leads AWS Field Experiences, overseeing tools and processes for the AWS GTM organization across all roles and customer engagement stages. Over the past two years, she led a transformation that consolidated hundreds of disparate systems into a streamlined, role-based experience, incorporating generative AI to reimagine the customer journey. Previously, as GM for the AWS hybrid storage portfolio, Asa launched several key services, including AWS File Gateway, AWS Transfer Family, and AWS DataSync. Before joining AWS, she founded two venture-backed startups in Boston.
Asa Kalavade leads AWS Field Experiences, overseeing tools and processes for the AWS GTM organization across all roles and customer engagement stages. Over the past two years, she led a transformation that consolidated hundreds of disparate systems into a streamlined, role-based experience, incorporating generative AI to reimagine the customer journey. Previously, as GM for the AWS hybrid storage portfolio, Asa launched several key services, including AWS File Gateway, AWS Transfer Family, and AWS DataSync. Before joining AWS, she founded two venture-backed startups in Boston.
Source link
lol