Building a deployment pipeline for generative artificial intelligence (AI) applications at scale is a formidable challenge because of the complexities and unique requirements of these systems. Generative AI models are constantly evolving, with new versions and updates released frequently. This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources. Constructing robust data pipelines that can handle this workload reliably and efficiently at scale is a considerable challenge. Monitoring the performance, bias, and ethical implications of generative AI models in production environments is a crucial task.
Achieving this at scale necessitates significant investments in resources, expertise, and cross-functional collaboration between multiple personas such as data scientists or machine learning (ML) developers who focus on developing ML models and machine learning operations (MLOps) engineers who focus on the unique aspects of AI/ML projects and help improve delivery time, reduce defects, and make data science more productive. In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams.
SageMaker Pipelines
You can use SageMaker Pipelines to define and orchestrate the various steps involved in the ML lifecycle, such as data preprocessing, model training, evaluation, and deployment. This streamlines the process and provides consistency across different stages of the pipeline. SageMaker Pipelines can handle model versioning and lineage tracking. It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions.
The SageMaker Pipelines decorator feature helps convert local ML code written as a Python program into one or more pipeline steps. Because Amazon Bedrock can be accessed as an API, developers who don’t know Amazon SageMaker can implement an Amazon Bedrock application or fine-tune Amazon Bedrock by writing a regular Python program.
You can write your ML function as you would for any ML project. After being tested locally or as a training job, a data scientist or practitioner who is an expert on SageMaker can convert the function to a SageMaker pipeline step by adding a @step decorator.
Solution overview
SageMaker Model Building Pipelines is a tool for building ML pipelines that takes advantage of direct SageMaker integration. Because of this integration, you can create a pipeline for orchestration using a tool that handles much of the step creation and management for you.
As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads. SageMaker Pipelines is integrated with SageMaker, so you don’t need to interact with any other AWS services. You also don’t need to manage any resources because SageMaker Pipelines is a fully managed service, which means that it creates and manages resources for you. Amazon SageMaker Studio offers an environment to manage the end-to-end SageMaker Pipelines experience. The solution in this post shows how you can take Python code that was written to preprocess, fine-tune, and test a large language model (LLM) using Amazon Bedrock APIs and convert it into a SageMaker pipeline to improve ML operational efficiency.
The solution has three main steps:
- Write Python code to preprocess, train, and test an LLM in Amazon Bedrock.
- Add
@stepdecorated functions to convert the Python code to a SageMaker pipeline. - Create and run the SageMaker pipeline.
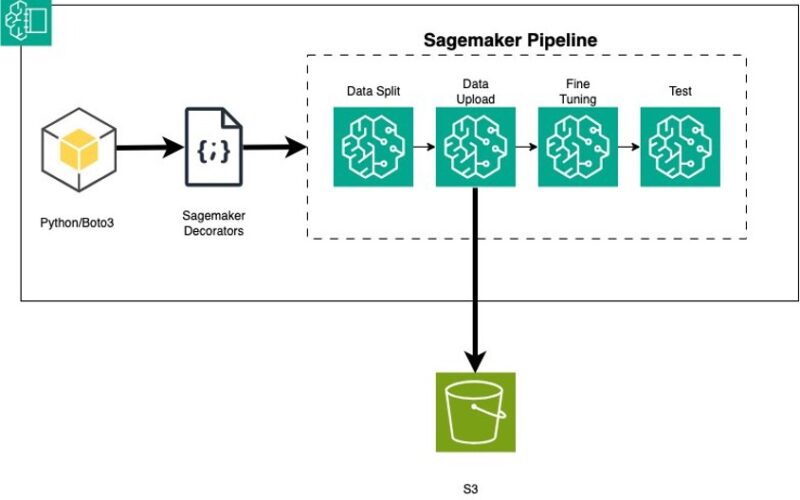
The following diagram illustrates the solution workflow.
Prerequisites
If you just want to view the notebook code, you can view the notebook on GitHub.
If you’re new to AWS, you first need to create and set up an AWS account. Then you will set up SageMaker Studio in your AWS account. Create a JupyterLab space within SageMaker Studio to run the JupyterLab application.
When you’re in the SageMaker Studio JupyterLab space, complete the following steps:
- On the File menu, choose New and Terminal to open a new terminal.
- In the terminal, enter the following code:
- You will see the folder caller
amazon-sagemaker-examplesin the SageMaker Studio File Explorer pane. - Open the folder
amazon-sagemaker-examples/sagemaker-pipelines/step-decorator/bedrock-examples. - Open the notebook
fine_tune_bedrock_step_decorator.ipynb.
This notebook contains all the code for this post, and you can run it from beginning to end.
Explanation of the notebook code
The notebook uses the default Amazon Simple Storage Service (Amazon S3) bucket for the user. The default S3 bucket follows the naming pattern s3://sagemaker-{Region}-{your-account-id}. If it doesn’t already exist, it will be automatically created.
It uses the SageMaker Studio default AWS Identity and Access Management (IAM) role for the user. If your SageMaker Studio user role doesn’t have administrator access, you need to add the necessary permissions to the role.
For more information, refer to the following:
It creates a SageMaker session and gets the default S3 bucket and IAM role:
Use Python to preprocess, train, and test an LLM in Amazon Bedrock
To begin, we need to download data and prepare an LLM in Amazon Bedrock. We use Python to do this.
Load data
We use the CNN/DailyMail dataset from Hugging Face to fine-tune the model. The CNN/DailyMail dataset is an English-language dataset containing over 300,000 unique news articles as written by journalists at CNN and the Daily Mail. The raw dataset includes the articles and their summaries for training, validation, and test. Before we can use the dataset, it must be formatted to include the prompt. See the following code:
Split data
Split the dataset into training, validation, and testing. For this post, we restrict the size of each row to 3,000 words and select 100 rows for training, 10 for validation, and 5 for testing. You can follow the notebook in GitHub for more details.
Upload data to Amazon S3
Next, we convert the data to JSONL format and upload the training, validation, and test files to Amazon S3:
Train the model
Now that the training data is uploaded in Amazon S3, it’s time to fine-tune an Amazon Bedrock model using the CNN/DailyMail dataset. We fine-tune the Amazon Titan Text Lite model provided by Amazon Bedrock for a summarization use case. We define the hyperparameters for fine-tuning and launch the training job:
Create Provisioned Throughput
Throughput refers to the number and rate of inputs and outputs that a model processes and returns. You can purchase Provisioned Throughput to provision dedicated resources instead of on-demand throughput, which could have performance fluctuations. For customized models, you must purchase Provisioned Throughput to be able to use it. See Provisioned Throughput for Amazon Bedrock for more information.
Test the model
Now it’s time to invoke and test the model. We use the Amazon Bedrock runtime prompt from the test dataset along with the ID of the Provisioned Throughput that was set up in the previous step and inference parameters such as maxTokenCount, stopSequence, temperature, and top:
Decorate functions with @step that converts Python functions into a SageMaker pipeline steps
The @step decorator is a feature that converts your local ML code into one or more pipeline steps. You can write your ML function as you would for any ML project and then create a pipeline by converting Python functions into pipeline steps using the @step decorator, creating dependencies between those functions to create a pipeline graph or directed acyclic graph (DAG), and passing the leaf nodes of that graph as a list of steps to the pipeline. To create a step using the @step decorator, annotate the function with @step. When this function is invoked, it receives the DelayedReturn output of the previous pipeline step as input. An instance holds the information about all the previous steps defined in the function that form the SageMaker pipeline DAG.
In the notebook, we already added the @step decorator at the beginning of each function definition in the cell where the function was defined, as shown in the following code. The function’s code will come from the fine-tuning Python program that we’re trying to convert here into a SageMaker pipeline.
Create and run the SageMaker pipeline
To bring it all together, we connect the defined pipeline @step functions into a multi-step pipeline. Then we submit and run the pipeline:
After the pipeline has run, you can list the steps of the pipeline to retrieve the entire dataset of results:
You can track the lineage of a SageMaker ML pipeline in SageMaker Studio. Lineage tracking in SageMaker Studio is centered around a DAG. The DAG represents the steps in a pipeline. From the DAG, you can track the lineage from any step to any other step. The following diagram displays the steps of the Amazon Bedrock fine-tuning pipeline. For more information, refer to View a Pipeline Execution.

By choosing a step on the Select step dropdown menu, you can focus on a specific part of the graph. You can view detailed logs of each step of the pipeline in Amazon CloudWatch Logs.

Clean up
To clean up and avoid incurring charges, follow the detailed cleanup instructions in the GitHub repo to delete the following:
- The Amazon Bedrock Provisioned Throughput
- The customer model
- The Sagemaker pipeline
- The Amazon S3 object storing the fine-tuned dataset
Conclusion
MLOps focuses on streamlining, automating, and monitoring ML models throughout their lifecycle. Building a robust MLOps pipeline demands cross-functional collaboration. Data scientists, ML engineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance. SageMaker Pipelines allows you to create and manage ML workflows while offering storage and reuse capabilities for workflow steps.
In this post, we walked you through an example that uses SageMaker step decorators to convert a Python program for creating a custom Amazon Bedrock model into a SageMaker pipeline. With SageMaker Pipelines, you get the benefits of an automated workflow that can be configured to run on a schedule based on the requirements for retraining the model. You can also use SageMaker Pipelines to add useful features such as lineage tracking and the ability to manage and visualize your entire workflow from within the SageMaker Studio environment.
AWS provides managed ML solutions such as Amazon Bedrock and SageMaker to help you deploy and serve existing off-the-shelf foundation models or create and run your own custom models.
See the following resources for more information about the topics discussed in this post:
About the Authors
 Neel Sendas is a Principal Technical Account Manager at Amazon Web Services. Neel works with enterprise customers to design, deploy, and scale cloud applications to achieve their business goals. He has worked on various ML use cases, ranging from anomaly detection to predictive product quality for manufacturing and logistics optimization. When he isn’t helping customers, he dabbles in golf and salsa dancing.
Neel Sendas is a Principal Technical Account Manager at Amazon Web Services. Neel works with enterprise customers to design, deploy, and scale cloud applications to achieve their business goals. He has worked on various ML use cases, ranging from anomaly detection to predictive product quality for manufacturing and logistics optimization. When he isn’t helping customers, he dabbles in golf and salsa dancing.
 Ashish Rawat is a Senior AI/ML Specialist Solutions Architect at Amazon Web Services, based in Atlanta, Georgia. Ashish has extensive experience in Enterprise IT architecture and software development including AI/ML and generative AI. He is instrumental in guiding customers to solve complex business challenges and create competitive advantage using AWS AI/ML services.
Ashish Rawat is a Senior AI/ML Specialist Solutions Architect at Amazon Web Services, based in Atlanta, Georgia. Ashish has extensive experience in Enterprise IT architecture and software development including AI/ML and generative AI. He is instrumental in guiding customers to solve complex business challenges and create competitive advantage using AWS AI/ML services.
Source link
lol