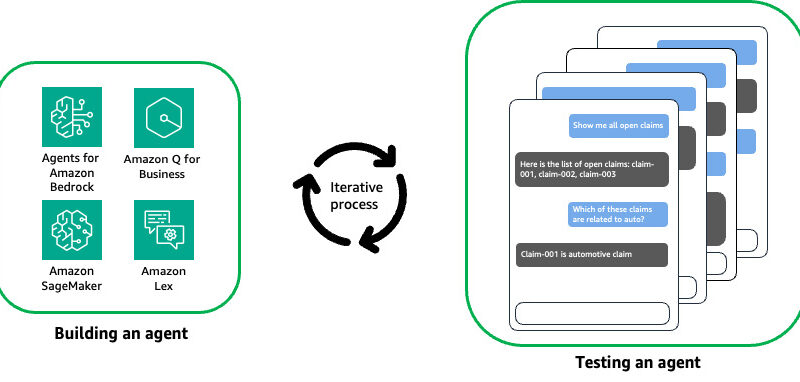
As conversational artificial intelligence (AI) agents gain traction across industries, providing reliability and consistency is crucial for delivering seamless and trustworthy user experiences. However, the dynamic and conversational nature of these interactions makes traditional testing and evaluation methods challenging. Conversational AI agents also encompass multiple layers, from Retrieval Augmented Generation (RAG) to function-calling mechanisms that interact with external knowledge sources and tools. Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. The following are some common pain points in developing conversational AI agents:
- Testing an agent is often tedious and repetitive, requiring a human in the loop to validate the semantics meaning of the responses from the agent, as shown in the following figure.
- Setting up proper test cases and automating the evaluation process can be difficult due to the conversational and dynamic nature of agent interactions.
- Debugging and tracing how conversational AI agents route to the appropriate action or retrieve the desired results can be complex, especially when integrating with external knowledge sources and tools.
Agent Evaluation, an open source solution using LLMs on Amazon Bedrock, addresses this gap by enabling comprehensive evaluation and validation of conversational AI agents at scale.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Agent Evaluation provides the following:
- Built-in support for popular services, including Agents for Amazon Bedrock, Knowledge Bases for Amazon Bedrock, Amazon Q Business, and Amazon SageMaker endpoints
- Orchestration of concurrent, multi-turn conversations with your agent while evaluating its responses
- Configurable hooks to validate actions triggered by your agent
- Integration into continuous integration and delivery (CI/CD) pipelines to automate agent testing
- A generated test summary for performance insights including conversation history, test pass rate, and reasoning for pass/fail results
- Detailed traces to enable step-by-step debugging of the agent interactions
In this post, we demonstrate how to streamline virtual agent testing at scale using Amazon Bedrock and Agent Evaluation.
Solution overview
To use Agent Evaluation, you need to create a test plan, which consists of three configurable components:
- Target – A target represents the agent you want to test
- Evaluator – An evaluator represents the workflow and logic to evaluate the target on a test
- Test – A test defines the target’s functionality and how you want your end-user to interact with the target, which includes:
- A series of steps representing the interactions between the agent and the end-user
- Your expected results of the conversation
The following figure illustrates how Agent Evaluation works on a high level. The framework implements an LLM agent (evaluator) that will orchestrate conversations with your own agent (target) and evaluate the responses during the conversation.

The following figure illustrates the evaluation workflow. It shows how the evaluator reasons and assesses responses based on the test plan. You can either provide an initial prompt or instruct the evaluator to generate one to initiate the conversation. At each turn, the evaluator engages the target agent and evaluates its response. This process continues until the expected results are observed or the maximum number of conversation turns is reached.

By understanding this workflow logic, you can create a test plan to thoroughly assess your agent’s capabilities.
Use case overview
To illustrate how Agent Evaluation can accelerate the development and deployment of conversational AI agents at scale, let’s explore an example scenario: developing an insurance claim processing agent using Agents for Amazon Bedrock. This insurance claim processing agent is expected to handle various tasks, such as creating new claims, sending reminders for pending documents related to open claims, gathering evidence for claims, and searching for relevant information across existing claims and customer knowledge repositories.
For this use case, the goal is to test the agent’s capability to accurately search and retrieve relevant information from existing claims. You want to make sure the agent provides correct and reliable information about existing claims to end-users. Thoroughly evaluating this functionality is crucial before deployment.
Begin by creating and testing the agent in your development account. During this phase, you interact manually with the conversational AI agent using sample prompts to do the following:
- Engage the agent in multi-turn conversations on the Amazon Bedrock console
- Validate the responses from the agent
- Validate all the actions invoked by the agent
- Debug and check traces for any routing failures
With Agent Evaluation, the developer can streamline this process through the following steps:
- Configure a test plan:
- Choose an evaluator from the models provided by Amazon Bedrock.
- Configure the target, which should be a type that Agent Evaluation supports. For this post, we use an Amazon Bedrock agent.
- Define the test steps and expected results. In the following example test plan, you have a claim with the ID
claim-006in your test system. You want to confirm that your agent can accurately answer questions about this specific claim.
- Run the test plan from the command line:
The Agent Evaluation test runner will automatically orchestrate the test based on the test plan, and use the evaluator to determine if the responses from the target match the expected results.
- View the result summary.
A result summary will be provided in markdown format. In the following example, the summary indicates that the test failed because the agent was unable to provide accurate information about the existing claimclaim-006.
- Debug with the trace files of the failed tests.
Agent Evaluation provides detailed trace files for the tests. Each trace file meticulously records every prompt and interaction between the target and the evaluator.For instance, in the_invoke_targetstep, you can gain valuable insights into the rationale behind the Amazon Bedrock agent’s responses, allowing you to delve deeper into the decision-making process:The trace shows that after reviewing the conversation history, the evaluator concludes, “the agent will be unable to answer or assist with this question using only the functions it has access to.” Consequently, it ends the conversation with the target agent and proceeds to generate the test status.
In the
_generate_test_statusstep, the evaluator generates the test status with reasoning based on the responses from the target.The test plan defines the expected result as the target agent accurately providing details about the existing claim
claim-006. However, after testing, the target agent’s response doesn’t meet the expected result, and the test fails. - After identifying and addressing the issue, you can rerun the test to validate the fix. In this example, it’s evident that the target agent lacks access to the claim
claim-006. From there, you can continue investigating and verify ifclaim-006exists in your test system.
Integrate Agent Evaluation with CI/CD pipelines
After validating the functionality in the development account, you can commit the code to the repository and initiate the deployment process for the conversational AI agent to the next stage. Seamless integration with CI/CD pipelines is a crucial aspect of Agent Evaluation, enabling comprehensive integration testing to make sure no regressions are introduced during new feature development or updates. This rigorous testing approach is vital for maintaining the reliability and consistency of conversational AI agents as they progress through the software delivery lifecycle.
By incorporating Agent Evaluation into CI/CD workflows, organizations can automate the testing process, making sure every code change or update undergoes thorough evaluation before deployment. This proactive measure minimizes the risk of introducing bugs or inconsistencies that could compromise the conversational AI agent’s performance and the overall user experience.
A standard agent CI/CD pipeline includes the following steps:
- The source repository stores the agent configuration, including agent instructions, system prompts, model configuration, and so on. You should always commit your changes to provide quality and reproducibility.
- When you commit your changes, a build step is invoked. This is where unit tests should run and validate the changes, including typo and syntax checks.
- When the changes are deployed to the staging environment, Agent Evaluation runs with a series of test cases for runtime validation.
- The runtime validation on the staging environment can help build confidence to deploy the fully tested agent to production.
The following figure illustrates this pipeline.

In the following sections, we provide step-by-step instructions to set up Agent Evaluation with GitHub Actions.
Prerequisites
Complete the following prerequisite steps:
- Follow the GitHub user guide to get started with GitHub.
- Follow the GitHub Actions user guide to understand GitHub workflows and Actions.
- Follow the insurance claim processing agent using Agents for Amazon Bedrock example to set up an agent.
Set up GitHub Actions
Complete the following steps to deploy the solution:
- Write a series of test cases following the agent-evaluation test plan syntax and store test plans in the GitHub repository. For example, a test plan to test an Amazon Bedrock agent target is written as follows, with
BEDROCK_AGENT_ALIAS_IDandBEDROCK_AGENT_IDas placeholders: - Create an AWS Identity and Access Management (IAM) user with the proper permissions:
- The principal must have InvokeModel permission to the model specified in the configuration.
- The principal must have the permissions to call the target agent. Depending on the target type, different permissions are required. Refer to the agent-evaluation target documentation for details.
- Store the IAM credentials (
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEY) in GitHub Actions secrets. - Configure a GitHub workflow as follows:
When you push new changes to the repository, it will invoke the GitHub Action, and an example workflow output is displayed, as shown in the following screenshot.

A test summary like the following screenshot will be posted to the GitHub workflow page with details on which tests have failed.

The summary also provides the reasons for the test failures.

Clean up
Complete the following steps to clean up your resources:
- Delete the IAM user you created for the GitHub Action.
- Follow the insurance claim processing agent using Agents for Amazon Bedrock example to delete the agent.
Evaluator considerations
By default, evaluators use the InvokeModel API with On-Demand mode, which will incur AWS charges based on input tokens processed and output tokens generated. For the latest pricing details for Amazon Bedrock, refer to Amazon Bedrock pricing.
The cost of running an evaluator for a single test is influenced by the following:
- The number and length of the steps
- The number and length of expected results
- The length of the target agent’s responses
You can view the total number of input tokens processed and output tokens generated by the evaluator using the --verbose flag when you perform a run (agenteval run --verbose).
Conclusion
This post introduced Agent Evaluation, an open source solution that enables developers to seamlessly integrate agent evaluation into their existing CI/CD workflows. By taking advantage of the capabilities of LLMs on Amazon Bedrock, Agent Evaluation enables you to comprehensively evaluate and debug your agents, achieving reliable and consistent performance. With its user-friendly test plan configuration, Agent Evaluation simplifies the process of defining and orchestrating tests, allowing you to focus on refining your agents’ capabilities. The solution’s built-in support for popular services makes it a versatile tool for testing a wide range of conversational AI agents. Moreover, Agent Evaluation’s seamless integration with CI/CD pipelines empowers teams to automate the testing process, making sure every code change or update undergoes rigorous evaluation before deployment. This proactive approach minimizes the risk of introducing bugs or inconsistencies, ultimately enhancing the overall user experience.
The following are some recommendations to consider:
- Don’t use the same model to evaluate the results that you use to power the agent. Doing so may introduce biases and lead to inaccurate evaluations.
- Block your pipelines on accuracy failures. Implement strict quality gates to help prevent deploying agents that fail to meet the expected accuracy or performance thresholds.
- Continuously expand and refine your test plans. As your agents evolve, regularly update your test plans to cover new scenarios and edge cases, and provide comprehensive coverage.
- Use Agent Evaluation’s logging and tracing capabilities to gain insights into your agents’ decision-making processes, facilitating debugging and performance optimization.
Agent Evaluation unlocks a new level of confidence in your conversational AI agents’ performance by streamlining your development workflows, accelerating time-to-market, and delivering exceptional user experiences. To further explore the best practices of building and testing conversational AI agent evaluation at scale, get started by trying Agent Evaluation and provide your feedback.
About the Authors
 Sharon Li is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS) based in Boston, Massachusetts. With a passion for leveraging cutting-edge technology, Sharon is at the forefront of developing and deploying innovative generative AI solutions on the AWS cloud platform.
Sharon Li is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS) based in Boston, Massachusetts. With a passion for leveraging cutting-edge technology, Sharon is at the forefront of developing and deploying innovative generative AI solutions on the AWS cloud platform.
 Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.
Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.
 Tony Chen is a Machine Learning Solutions Architect at Amazon Web Services, helping customers design scalable and robust machine learning capabilities in the cloud. As a former data scientist and data engineer, he leverages his experience to help tackle some of the most challenging problems organizations face with operationalizing machine learning.
Tony Chen is a Machine Learning Solutions Architect at Amazon Web Services, helping customers design scalable and robust machine learning capabilities in the cloud. As a former data scientist and data engineer, he leverages his experience to help tackle some of the most challenging problems organizations face with operationalizing machine learning.
 Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
 Curt Lockhart is an AI/ML Specialist Solutions Architect at AWS. He comes from a non-traditional background of working in the arts before his move to tech, and enjoys making machine learning approachable for each customer. Based in Seattle, you can find him venturing to local art museums, catching a concert, and wandering throughout the cities and outdoors of the Pacific Northwest.
Curt Lockhart is an AI/ML Specialist Solutions Architect at AWS. He comes from a non-traditional background of working in the arts before his move to tech, and enjoys making machine learning approachable for each customer. Based in Seattle, you can find him venturing to local art museums, catching a concert, and wandering throughout the cities and outdoors of the Pacific Northwest.
Source link
lol