Vision-Language Models Booming. VLMs are experiencing a boom. Large foundation models like OpenAI GPT-4o, Anthropic Claude 3.5 Sonnet, and Google Gemini Pro 1.5 keep showing amazing vision-language capabilities and still dominate the benchmarks. But in a race to democratise VLMs at an efficient cost of operation -while maintaining performance- there is a new type of emerging, small, versatile, specialised VLMs that are becoming very powerful. And that is great!
Start here: The best intro to VLMs, 2024. Probably – by far- the best introduction to VLMs. A mega paper in the format of a pdf book, published by Meta AI, NYU, MILA, MIT and several other unis. Paper: An Introduction to Vision-Language Modelling.
Recommended: Tutorial on VLMs CVPR June 2024. This tutorial covers the latest approaches and theories on 1) Learning VLMs for multimodal understanding and generation 2) Benchmarking and evaluating VLMs and 3) Agents and other Advanced Systems based on Vision Foundation Model. All the slides and video sessions from the tutorial here: Recent Advances in Vision Foundation Models.
Trend: Small but powerful VLMs. This an unstoppable trend: we’re starting to see some amazing, small -even tiny- VLMs that are very powerful. Some are even full open-source, or at least open/open weights, and in some cases achieve SOTA in several benchmarks. Here are 5 small VLMs you should know:
LLaVA-Next (interleaved). Key feature: An image-text interleaved format that unifies multi-image, video, and 3D tasks in one model with excellent performance. Released in 0.5b, 7b, and 7b-dpo versions, it achieves SOTA in many benchmarks, and leads the open source VLMs. Checkout the repo, demo, and blog here: LLaVA-NeXT: Open Large Multimodal Models.
PaliGemma. Key feature: It takes both images and text as inputs and can answer questions about images with detail and context efficiently. PaliGemma is an open, lightweight VLM based on the more powerful PaLI-3 family of VLMs from Google. You can get the base, pre-trained PaliGemma and PaliGemma-FT fine-tuned version. Sonu posted a nice in-depth review of PaliGemma and how to fine-tune it.
Phi-3 Vision. Key feature: Very strong multi-modal, high quality reasoning trained on dense text and image data. Phi-3 Vision is based on the latest family of Phi-3 models released by Microsoft. You can get the latest model version released, Phi-3-Vision-128K-Instruct, which achieves SOTA in several benchmarks with quite a long context. Sam recently published a nice review, testing the model with some real world cases.
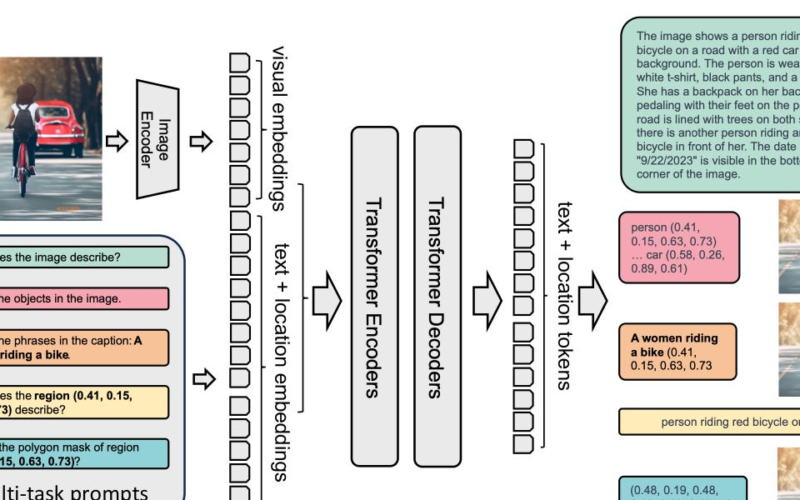
Florence-2. Key feature: a unified, prompt-based representation for a variety of vision and vision-language tasks. Published by Microsoft, Florence-2 was designed to take text-prompts as task instructions and generate desirable results in text forms, whether it be captioning, object detection, grounding or segmentation. Paper: Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks. The team at Roboflow just released a in-depth tutorial on fine-tuning Florence-2.
InternLM-XComposer 2.5. Key feature: Ultra-high resolution & fine-gained image and video understanding in a small model with long context. This VLM supports 96K long-context input and output. It achieves GPT-4V level capabilities in many benchmarks with just a 7B LLM backend. Repo, demo and technical report: InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output. Two days ago, Fahd published a good review on this model and some of its installation pains.
NVIDIA VLMs playground. NVIDIA just released a nice demo-playground for several of these VLMs above. Try it here: NVIDA VLMs.
A new multi-modal model benchmark. Reflecting the trend in VLMs, a week ago or so, LMSYS.org -the well known benchmark for AI Models- introduced a new multi-model benchmark that covers vision-language/ multi-modal capabilities. Still early days, but most of the multi-modal models covered are closed, proprietary models. Blogpost: The Multi-Modal Arena is here.
Have a nice week.
-
AutoGluon ML Beats 99% of Data Scientists with 4 Lines of Code
-
Berkeley AI Hackathon 2024: All the Winners & Karpathy’s Keynote
-
Gradient Boosting like LLMs: Zero-shot Forecasting with ML models
-
SMAT: Meta-Tuning for Few-shot Generalisation with Sparse MoEs
-
A Benchmark of Tabular ML in-the-Wild with Real-world Datasets
-
MIT Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol