
Mix, Bind & Merge OS Small AI Models FTW! Y2024: The year that open-source, small AI model-combos beat the big boys? The open source AI community and small AI startups are releasing a plethora of open-source, small AI models that are matching or -in some instances- even outperforming AI Titans’ huge models. I’m rooting for the open-source AI community!
These new os small models are leveraging supper efficient techniques like quantisation and fine-tuning with QLoRA, and fine-tuning with DPO. There’s a whole new range of open-source tools like LLamaFactory designed to easily, efficiently fine-tune these os models.
Using e.g. the free LM Studio – and thanks to The Bloke- you can easily download pretty much any quantised, gguf-ied (llama.cpp) version of these os small AI models, and run them securely in your laptop for free. Do checkout LM Studio, it’s really fantastic.
And now, using new techniques to mix, bind and merge these os small models, you can quickly achieve amazing results at very low cost. The possibilities are endless! Read how this guy built a fully local voice assistant to control his smart home using Mixtral MoE model.
Mixtral Sparse Mixture of Experts (SMoE): The paper. A week ago, Mistral finally released the Mixtral paper. Mixtral has 8 feedforward blocks (i.e. experts,) and was trained with a context size of 32k tokens. And the Mixtral 8x7B-Instruct version, surpasses GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B models. Paper: Mixtral of Experts. This is a nice vid explainer of the paper: The New Mixtral 8X7B Paper is GENIUS!!!

Mixtral and its new model friends. The Mistral and Mixtral models have inspired a whole new range of super efficient, small MoEs models that are popping up everywhere like:
-
phixtral-2x2_8 is the first Mixure of Experts (MoE) made with two Microsoft Phi-2 models, inspired by Mixtral-8x7B architecture. It performs better than each individual expert.
-
Marcoro14-7B-slerp. This is a merge of the Mistral-7B-Merge-14-v0.1 and Marcoroni-7B-v3 models made with mergekit
-
Beyonder-4x7B-v2. This model is a MoE model made with mergekit. This model is competitive with Mixtral-8x7B-Instruct-v0.1 on the Open LLM Leaderboard, while only having 4 experts instead of 8.
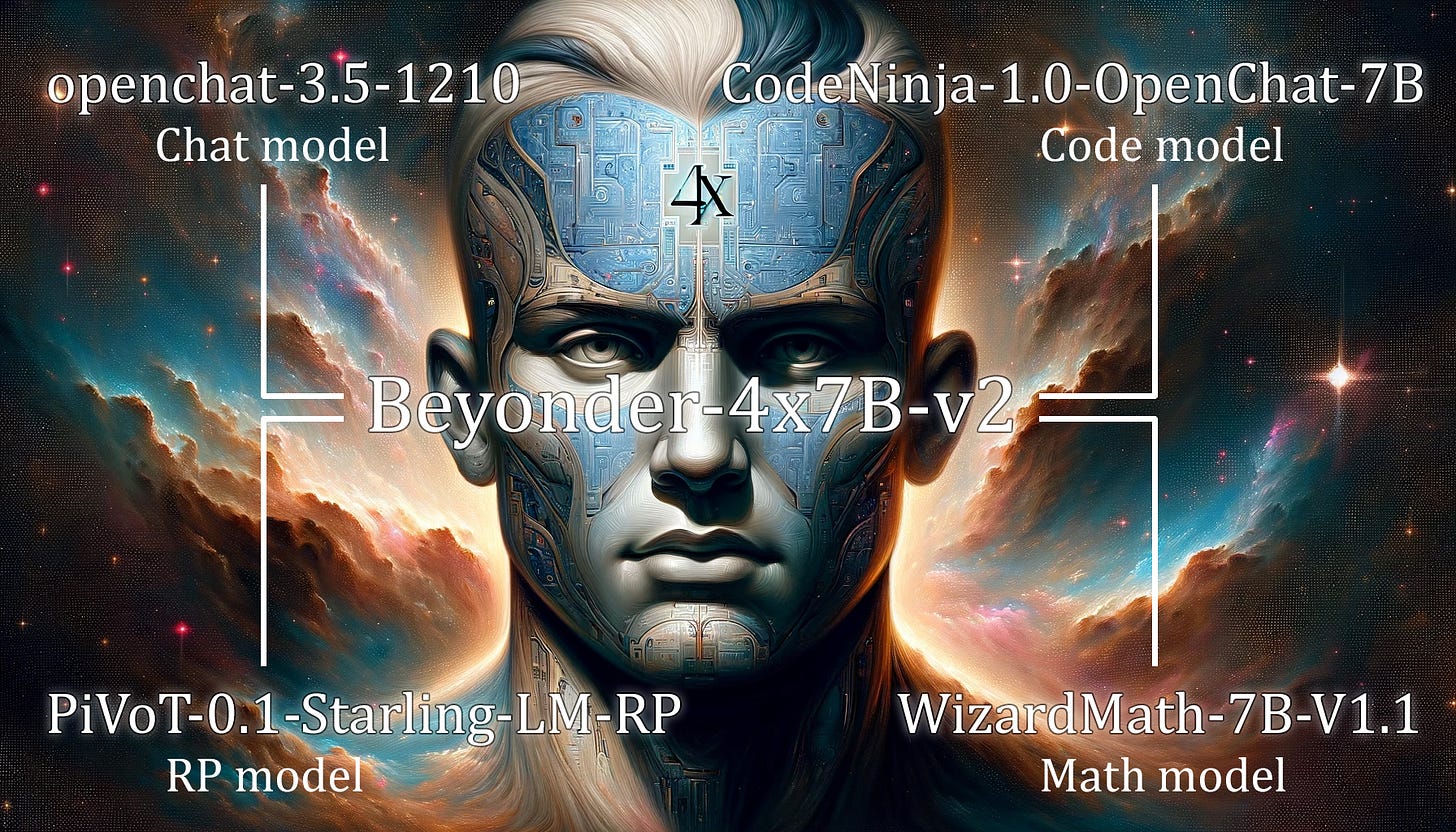

A novel MoEs architecture. DeepSeekMoE 16B is a new Mixture-of-Experts (MoEs) model with 16.4B params and trained on 2T tokens. Its innovative MoE architecture involves two key strategies: fine-grained expert segmentation and shared experts isolation. It can be deployed on a single GPU with 40GB of mem without the need for quantization. Checkout the repo, paper: DeepSeekMoE: Towards Ultimate Expert Specialisation in MoEs LMs.

A new model combo: State Space Models (SSMs)+ MoEs. State Space Models (checkout this intro to SSMs) are starting to challenge Transformers. At the same time, Mixture of Experts (MoEs) are pushing Transformer model performance to new SOTA levels. In this paper, a group of Polish researchers introduce MoE-Mamba, a model that combines SSMs & MoEs. Paper: MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts.

Mixturing linear experts for long term time-series forecasting. Reasearchers at MSFT just introduced a Mixture-of-Linear-Experts (MoLE) model for long-term time series forecasting (LTSF). MoLE models can achieve SOTA LTSF in several benchmarks. Paper: Mixture-of-Linear-Experts for Long-term Time Series Forecasting.
Model blending small models can outperform larger models. Can a combination of smaller models collaboratively achieve comparable or enhanced performance relative to a singular LM? Researchers at UCL & Cambridge Uni just introduced Blending: When blending smaller models synergistically, they can potentially outperform or match the capabilities of much larger models. Paper: Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM.
Model merging small models delivers awesome performance. Model merging is a new technique that combines two or more LLMs into a single model. Model merging is not the same as MoEs models. In this great blogpost, Maxime introduces the concept of merging models with four different methods. And then, he brilliantly shows how merging smallish models can deliver top performing results. Blogpost: How to merge LLMs with mergekit.

Have a nice week.
-
[tutorial] Open Interpreter: Opensource “OpenAI Code Interpreter”
-
[notebook] ImageBind: Multimodal Joint Embedding for Img, Vid, Txt, Aud
-
[tutorial] How to Fine-tune Nearly SOTA MSFT Phi-2 2.7B with QLoRA
-
Bytedance LEGO: A Robust, Multi-modal, Grounding Model (code, demo, paper)
-
[paper explainer] DPO Beats RLHF + PPO: Your LM is Secretly a Reward Model
-
AgentSearch-V1: 1 Billion Embeddings from 50 million HQ Docs
-
Let’s Go Shopping (LGS): 15M img-txt Pairs from e-Commerce Websites
-
MIT & MetaAI CruxEval: A Dataset for Evaluating Python Coding & Reasoning
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol