22
May
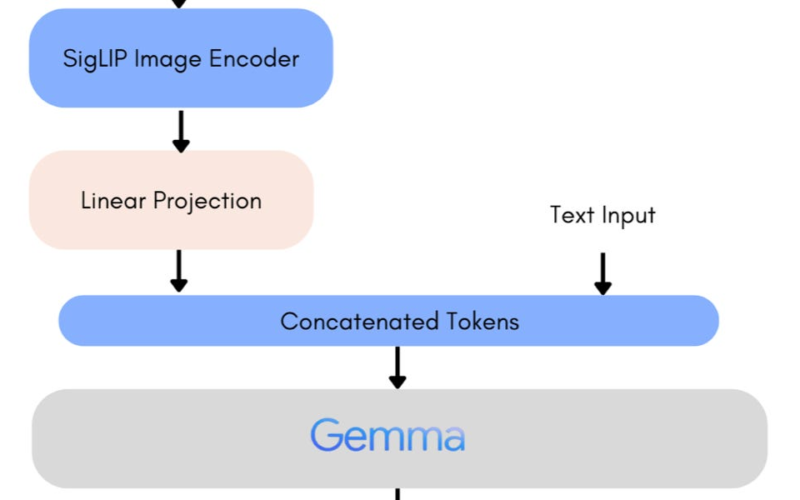
Quantized LoRA, more commonly known as QLoRA is a combination of quantization and Low Rank Adaptation for fine-tuning LLMs. Simply put, LoRa is a technique to adapt Large Language Models to specific tasks without making them forget their pretraining knowledge. In QLoRa, we load the pretrained model weights in quantized format, say 4-bit (INT4). However, the adapter (LoRA) layers are loaded in full precision, FP16 or FP32. This reduces the memory (GPU) consumption by a great extent making fine tuning possible on low resource hardware. To this end, in this article, we will be fine tuning the Phi 1.5 model…