The Google AI Blast . This week OpenAI released a new closed model called GPT-4o (as in omni): Hello GPT-4o, a model that can reason across audio, vision, and text in real time. It seems the model performance in many benchmarks wasn’t as good as many AI pundits expected.
And while many people in the AI community were befuddled and discussing the “flirtatiousness” aspects of GPT-4o, then Google came in and blasted a massive AI storm including SOTA models, new powerful open models, and pretty amazing tools. Here’s my summary on what Google released:
Gemini 1.5 Pro model updates: Lots of improvements in coding, reasoning, translation, multimodality and much more. Some key updates include:
-
multimodal prompting to prompt the model with any text, image, audio, and video data
-
custom function calling to enable real-time interactions with external world
-
systems instructions to steer the behaviour of the model based on specific requirements or use cases
-
context caching to reduce the cost of requests that contain repeat content with high input token counts
-
Notably, an extended context size to 2 million tokens! Google researchers say Gemini Pro 1.5 has perfect retrieval (>99%) up to at least 10M tokens, massively beating Claude 3.0 (200k) and GPT-4 Turbo (128k).
If you’re interested to know more read the technical report: Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Also checkout this video demoing Gemini’s new extended long context
New Gemini 1.5 Flash model: The new, smaller Gemini 1.5 Flash model is optimised for high-volume, high-frequency tasks at scale, is more cost-efficient to serve. Use it when narrower or high-frequency tasks require fast model’s response and time matters the most. It features a 1 million a long context window. Check this video on Getting started with Gemini Flash.
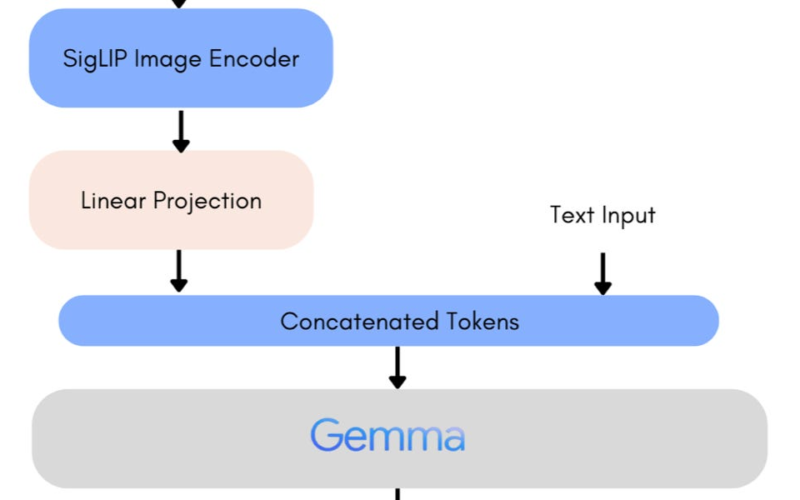
A new, open Vision-Language Model. PaliGemma is a powerful open VLM inspired by PaLI-3 model. Built on open components including the SigLIP vision model and the Gemma language model, PaliGemma is designed for class-leading fine-tune performance on a wide range of vision-language tasks. This includes image and short video captioning, visual question answering, understanding text in images, object detection, and object segmentation. Checkout this review by the Hugging Face team: PaliGemma – Google’s Cutting-Edge Open Vision Language Model.
Announced new Gemma 2 open model. A 27 billion parameter model that delivers performance comparable to Mistral and Llama 3 70B at less than half the size. According to Google, this breakthrough efficiency sets a new standard in the open model landscape. Gemma 2, a 27B-parameter open model, launching in June.
Project Astra: Universal interactive AI Agents. An advanced seeing-and-talking responsive AI agent. The agent uses real-time multi-modality, remembers what it sees and hears to understand context and takes action. It’s also quite proactive, teachable and personal, and has few delays. Checkout this amazing video demo:
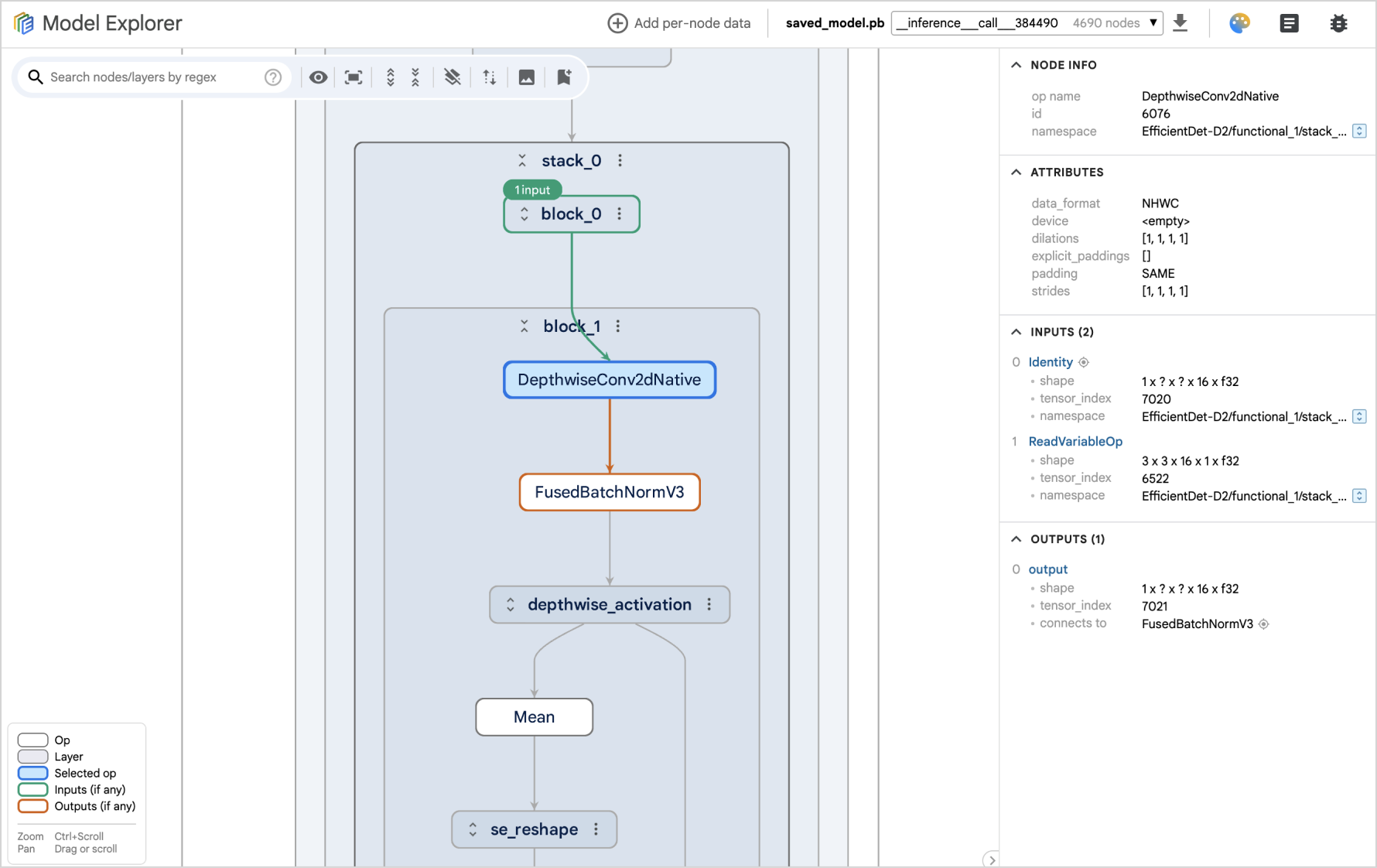
New ML Model Explorer, a powerful graph visualisation tool that helps one understand, debug, and optimise ML models. It specializes in visualizing large graphs in an intuitive, hierarchical format, but works well for smaller models as well. Blogpost: Model Explorer: Graph visualization for large model development.
A new AI Safety framework. A set of protocols for proactively identifying future AI capabilities that could cause severe harm and putting in place mechanisms to detect and mitigate them. The focus is on severe risks resulting from powerful capabilities at the model level, such as exceptional agency or sophisticated cyber capabilities. Blogpost: Introducing the Frontier Safety Framework.
A new Generative AI Toolkit that includes a series of tools to develop and evaluate robust, safe AI apps. It includes an LLM comparator and an interpretability tool. See: Responsible Generative AI Toolkit.
A new AI Developer competition. Build an AI App that integrates with Gemini API. Compete for your share of $1 million in cash prizes. Read more about the competition rules, submission guidelines, prizes, and timeline here: Google Gemini API Developer Competition.
Alice’s Adventures in Wonderland reimagined by GenAI. A set of beautiful interactive stories created by 5 artists using GenAI. Link: Infinite Wonderland.

Have a nice week.
-
All Neural Nets are Converging to a Platonic Model of Reality
-
The 1st Interpretable DL Model that Works for Time Series Forecasting
-
NVIDIA ChatQA-1.5 Surpasses GPT-4 on Conversational QA & RAG
-
Chessdream – A Free AI that Generates Realistic Chess Positions
-
[comedy] The Daily Show: “New GPT-4o is Sounding Really Horny”
-
Parler-TTS Mini: Expresso – Natural, Consistent, AI Speech with Emotions
-
VILA- An OSS Vision-Language Model for Video & Multi-image Understanding
-
[free tutorial] Planning & Reasoning in LLMs (videos & slides)
-
MAMBA from Scratch: RNNs are Better and Faster than Transformers
-
Meta AI – Chameleon: Mixed-Modal Early-Fusion FMs that Beat GPT4-V
-
DeepMind – CAT3D: Create Anything in 3D with Multi-View Diffusion Models
-
DataBricks AI – LoRA Learns Less and Forgets Less (Underperforms Fine-tuning)
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol