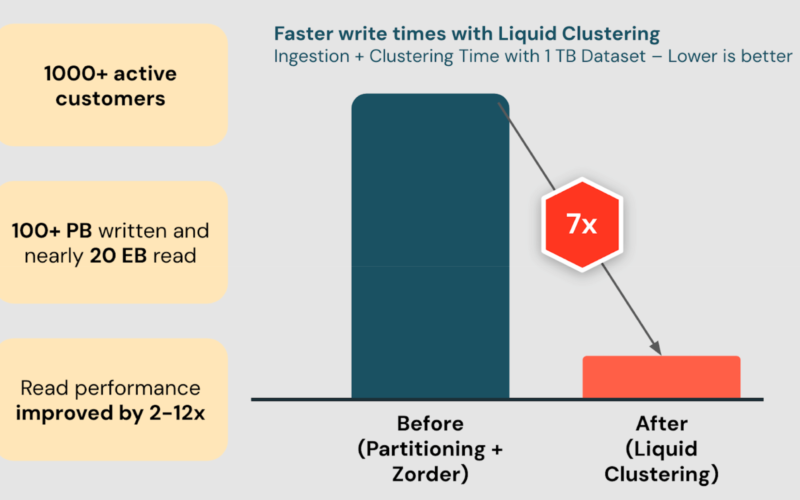
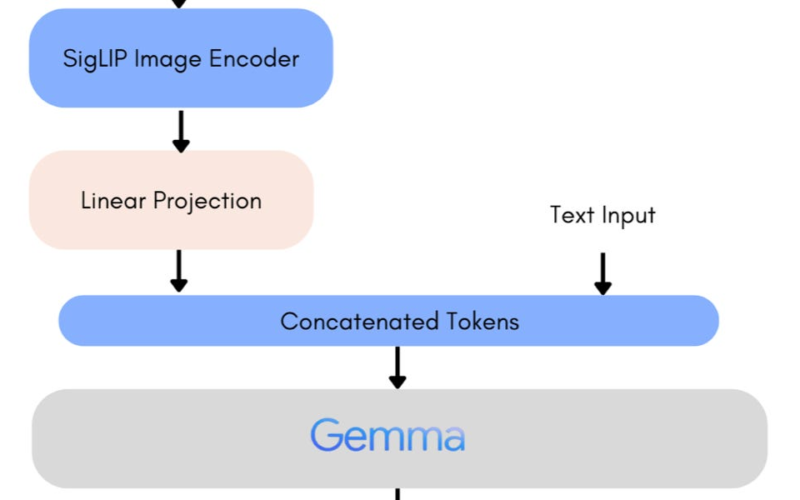
23
May
Diffusion, FM & Pre-Trained AI models for Time-Series. DeepNN-based models are starting to match or even outperform statistical time-series analysis & forecasting methods in some scenarios. Yet, DeepNN-based models for time-series suffer from 4 key issues: 1) complex architecture 2) enormous amount of time required for training 3) high inference costs, and 4) poor context sensitivity.Latest innovative approaches. To address those issues, a new breed of foundation or pre-trained AI models for time-series is emerging. Some of these new AI models use hybrid approaches borrowing from NLP, vision/ image, or physics modelling, like: transformers, diffusion models, KANs and state space…