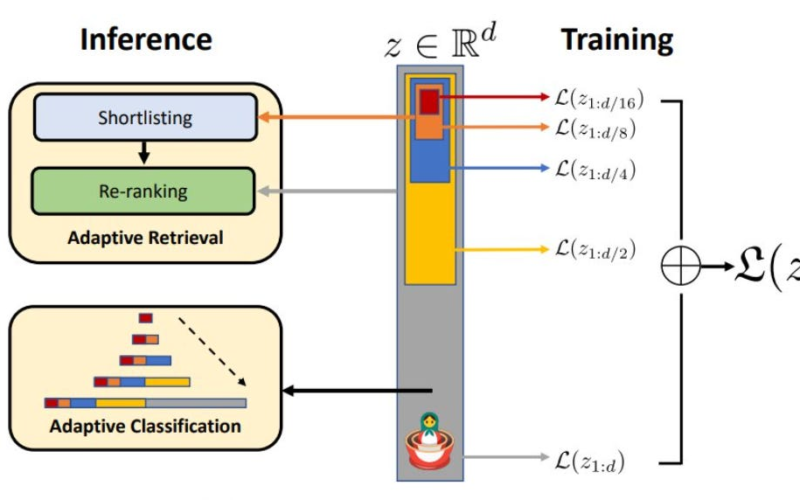
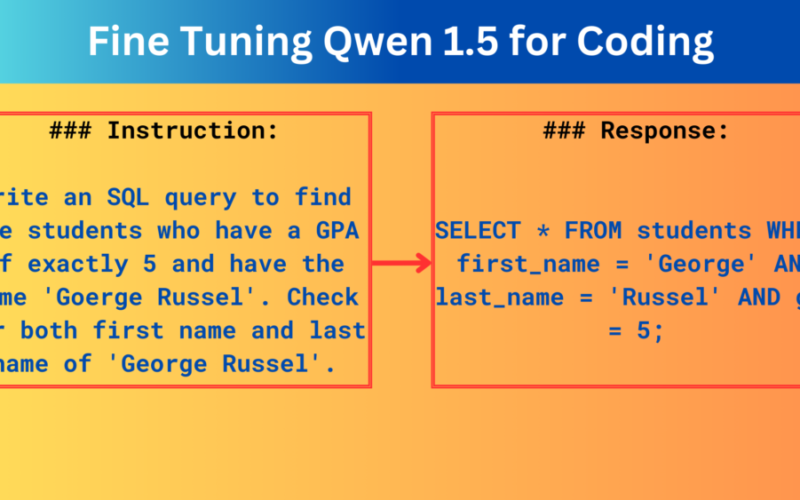
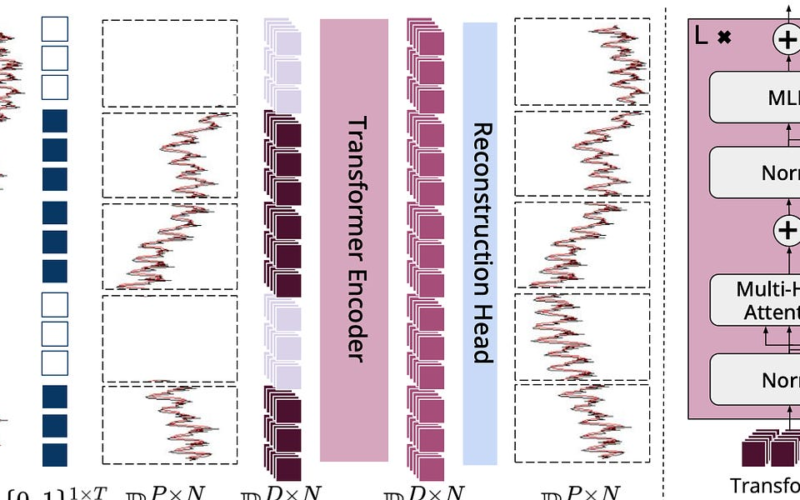
27
May
[Submitted on 3 May 2024] View a PDF of the paper titled Reservoir Computing with Generalized Readout based on Generalized Synchronization, by Akane Ookubo and Masanobu Inubushi View PDF HTML (experimental) Abstract:Reservoir computing is a machine learning framework that exploits nonlinear dynamics, exhibiting significant computational capabilities. One of the defining characteristics of reservoir computing is its low cost and straightforward training algorithm, i.e. only the readout, given by a linear combination of reservoir variables, is trained. Inspired by recent mathematical studies based on dynamical system theory, in particular generalized synchronization, we propose a novel reservoir computing framework with generalized readout,…