Foundation Models, Transformers and Time-Series. Statisticians and econometricians have been searching for the Holy Grail of time-series forecasting (TSF) for more than 40 years. “Classical” models like ARIMA still work remarkably well in some TSF scenarios. But today, the cool stuff is all about transformer-based, DL & foundation models for TSF. How “good” are these new DL models for TSF? How do we evaluate these models? Do these new models really achieve SOTA performance as some papers claim? Are DL researchers cherrypicking ts datasets to easily fit a SOTA TSF DL model?…
Real world time-series data is complex, messy, and it has a lot of subtleties like: randomness of errors, trend, seasonality, linearity, and stability… Compiling a solid, large ts dataset that suits the pre-training of a large DL model is hard and expensive. Most time series data come with huge noise and poor context. Since transfer learning is one of the pillars of foundation models: How do we figure out what ”knowledge” can be actually transferred across different time series so that the foundation model learns?
But first let’s see what’s the very latest in transformer-based, DL and foundations models for TSF.
A new Foundation Model for TSF v.3. A group of Google researchers recently introduced their latest time-series foundation model for forecasting. The researchers claim that the model has out-of-the-box zero-shot capability and near SOTA performance on a variety of public datasets. Paper: A Decoder-only Foundation Model for Time-series Forecasting
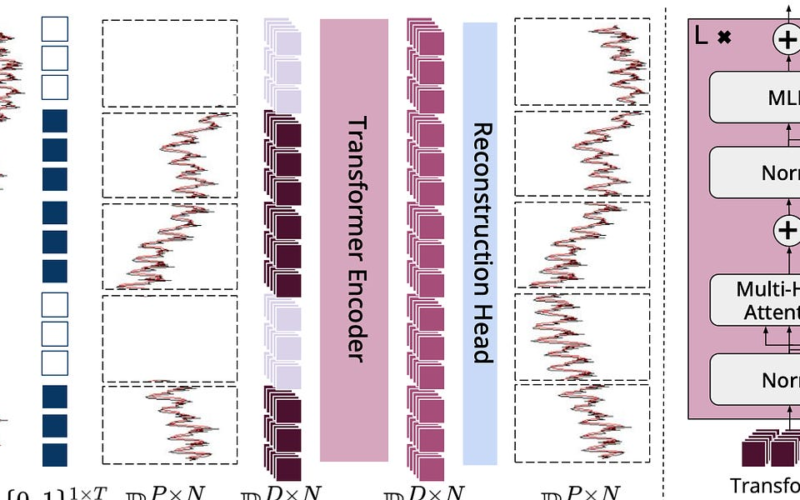
A new open source Foundation Model for TSF. A few days ago, a group of researchers working at ServiceNow, open sourced Lag-Llama: the first open-source foundation model for time series forecasting. Checkout the repo, paper and notebooks here: Lag-Llama: Foundation Models for Probabilistic Time Series Forecasting.
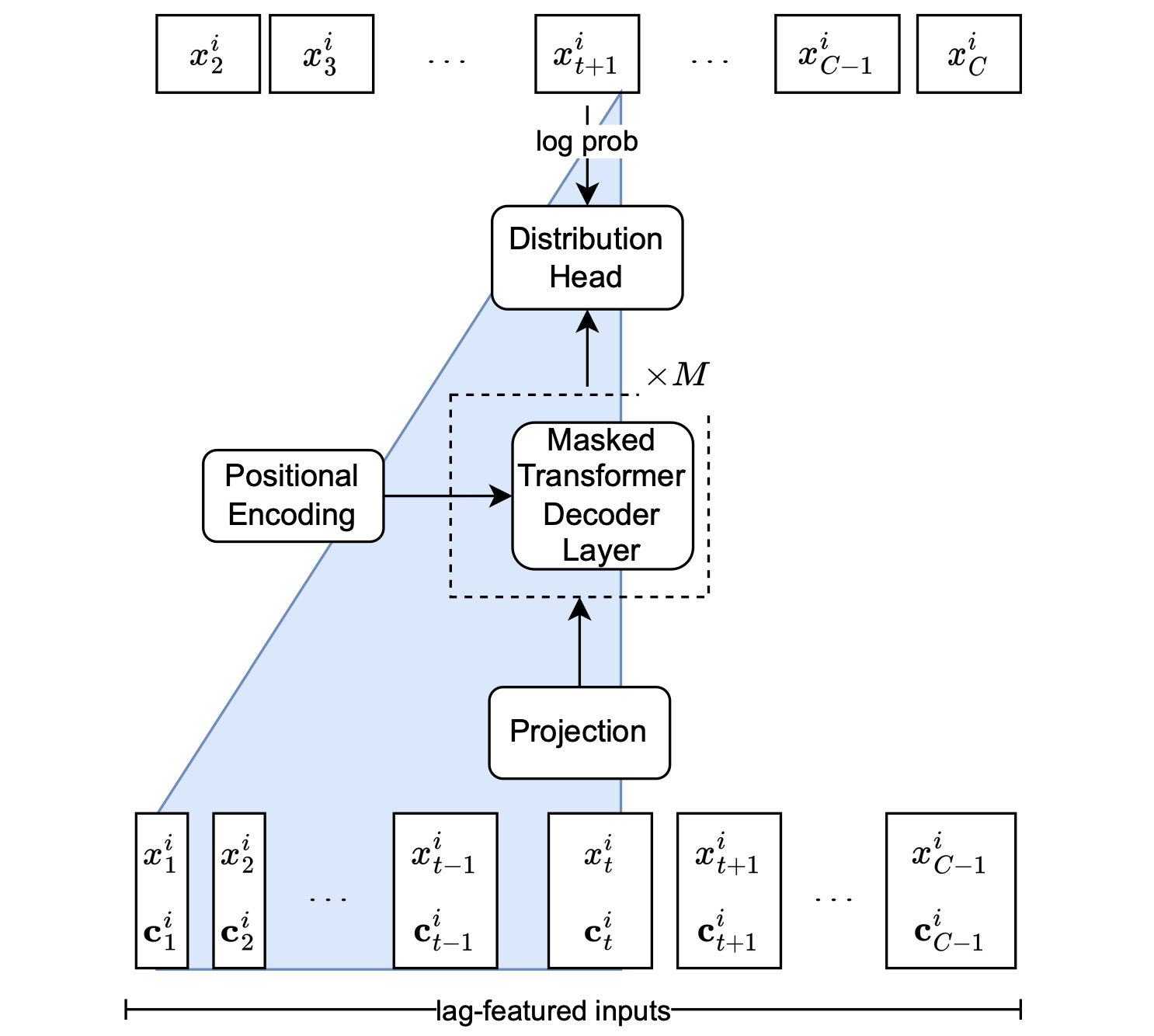
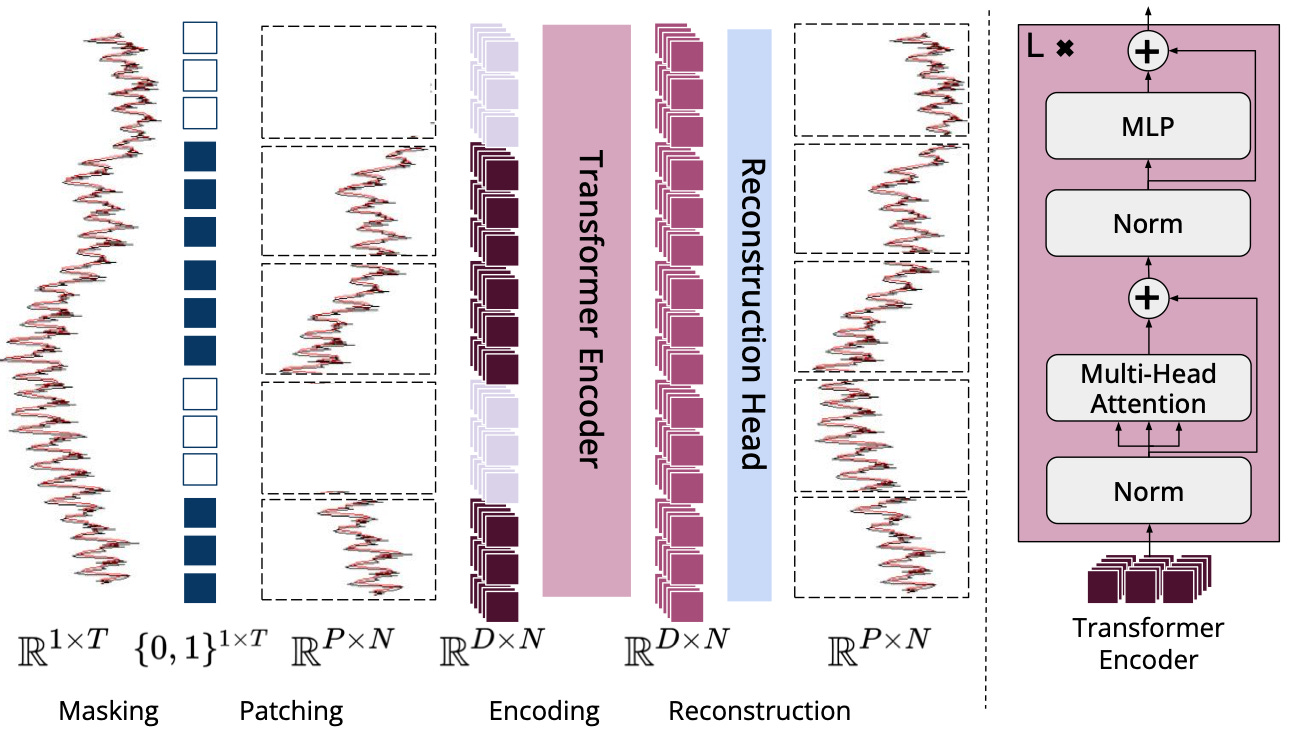
A new family of open Foundation Models for TSF. This week, researchers at CMU introduced MOMENT. The paper describes how the model addresses the challenges of pre-training large models on time-series. Checkout the paper, and official Pycode implementation: MOMENT: A Family of Open Time-series Foundation Models.
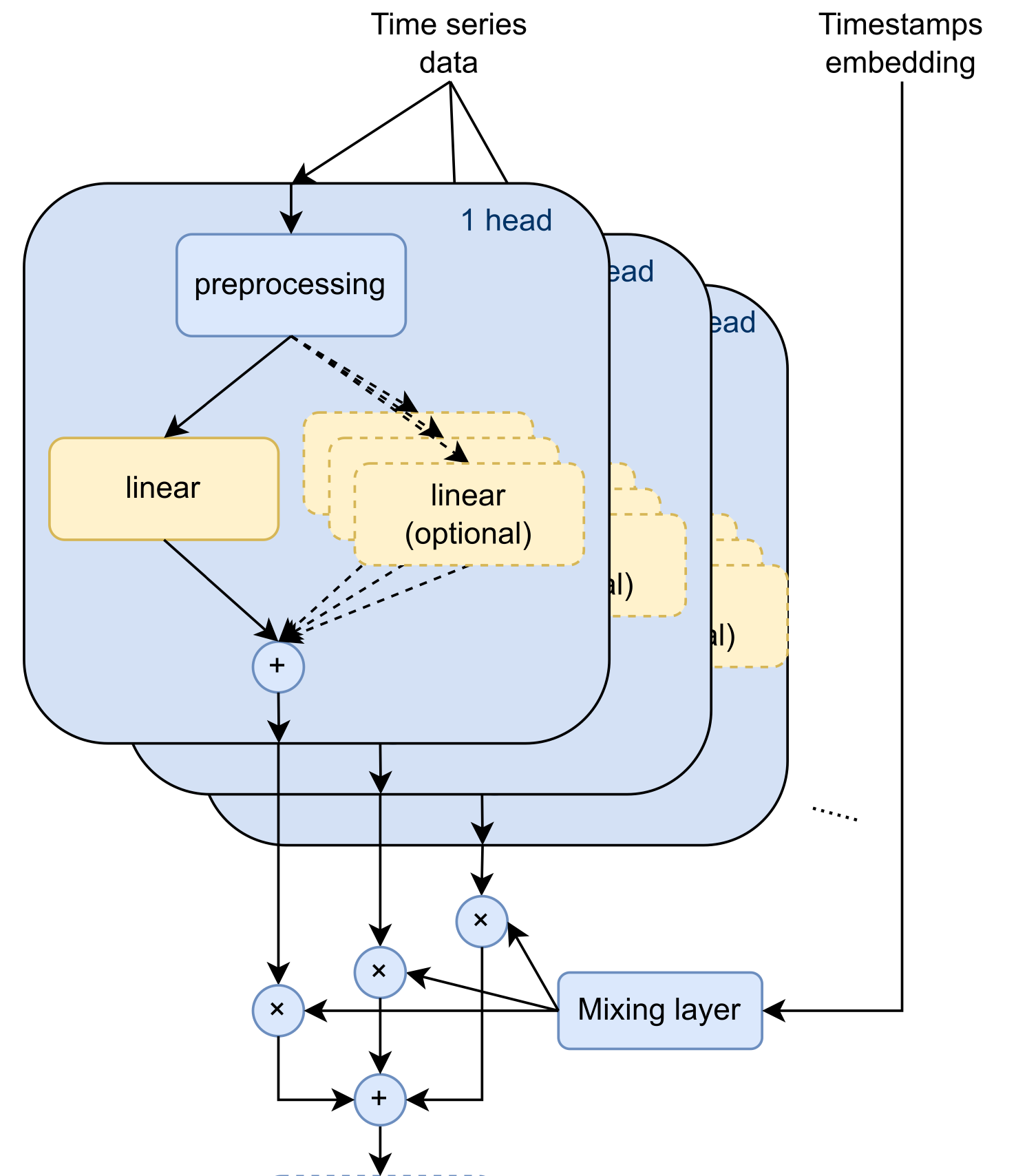
Mixture-of-Experts for Long-term TSF. Near SOTA, or SOTA Linear-centric models for TSF are not able to adapt their prediction rules to periodic changes in time series patterns. To address this challenge, a group of Microsoft researchers proposed Mixture-of-Linear-Experts (MoLE): a Mixture-of-Experts-style augmentation for linear-centric models. The researchers claim that MoLE achieves SOTA in almost 70% of evaluations and datasets. Paper: Mixture-of-Linear-Experts for Long-term Time Series Forecasting
And now a few food for thought snippets below:
Have a nice week.
-
Beyond Self-Attention: How a Small Model Predicts the Next Token
-
[brilliant 🙂 ]The World’s Most Responsible AI Model (blog, demo)
-
Odyssey 2024 – Emotions Recognition Challenge with SSL Models
-
[watch] Fully Autonomous Androids Run by a Vision NNet in Real-time
-
InstaGen: Improving Object Detection with AI Generated Synth Dataset
-
Ego-Exo4D- Large-scale Multi-modal, Multi-view, Video Dataset
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol