24
May
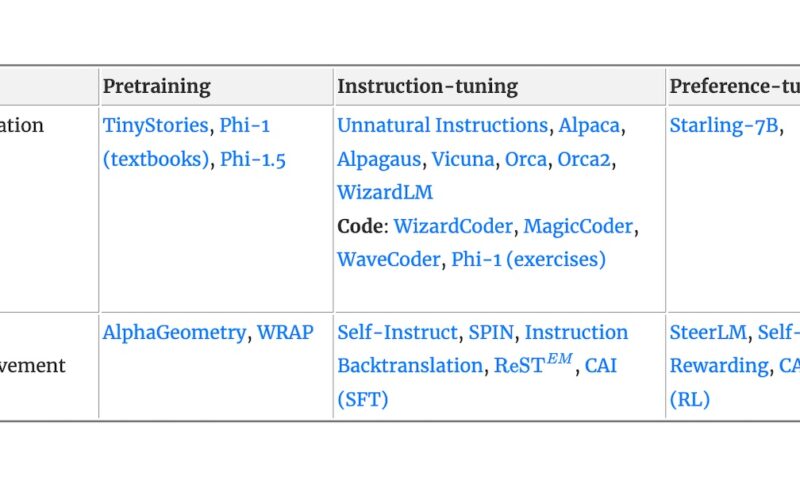
It is increasingly viable to use synthetic data for pretraining, instruction-tuning, and preference-tuning. Synthetic data refers to data generated via a model or simulated environment, instead of naturally occurring on the internet or annotated by humans. Relative to human annotation, it’s faster and cheaper to generate task-specific synthetic data. Furthermore, the quality and diversity of synthetic data often exceeds that of human annotators, leading to improved performance and generalization when models are finetuned on synthetic data. Finally, synthetic data sidesteps privacy and copyright concerns by avoiding reliance on user data or possibly copyrighted content. There are two main approaches to…