23
May
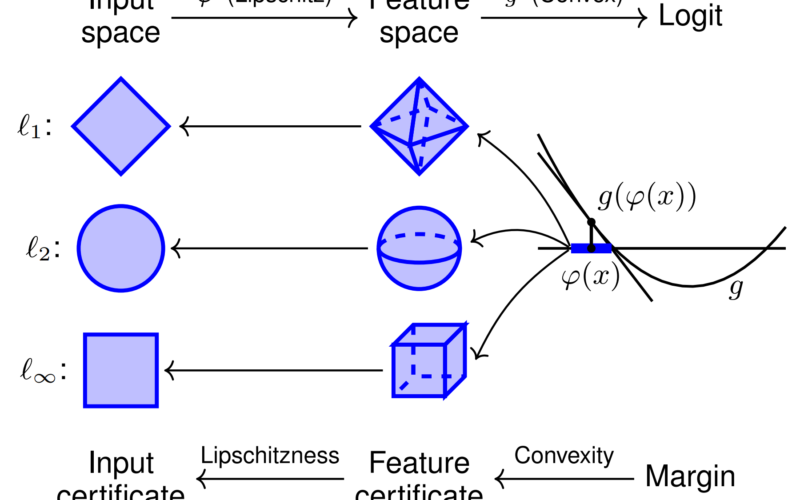
Asymmetric Certified Robustness via Feature-Convex Neural Networks TLDR: We propose the asymmetric certified robustness problem, which requires certified robustness for only one class and reflects real-world adversarial scenarios. This focused setting allows us to introduce feature-convex classifiers, which produce closed-form and deterministic certified radii on the order of milliseconds. Figure 1. Illustration of feature-convex classifiers and their certification for sensitive-class inputs. This architecture composes a Lipschitz-continuous feature map $varphi$ with a learned convex function $g$. Since $g$ is convex, it is globally underapproximated by its tangent plane at $varphi(x)$, yielding certified norm balls in the feature space. Lipschitzness of $varphi$…