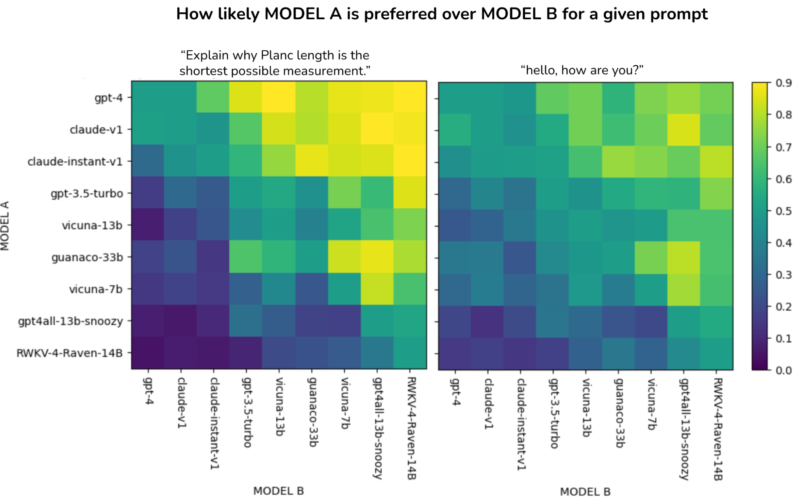
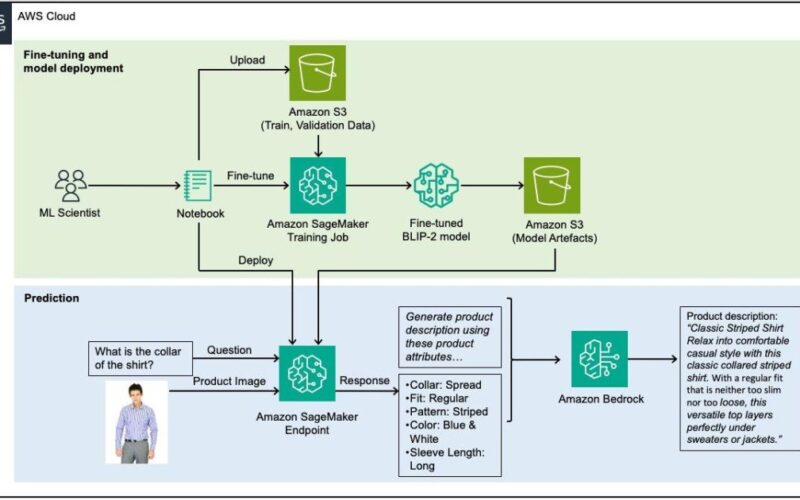
23
May
Last year, the team began experimenting with a tiny model that uses only a single layer of neurons. (Sophisticated LLMs have dozens of layers.) The hope was that in the simplest possible setting they could discover patterns that designate features. They ran countless experiments with no success. “We tried a whole bunch of stuff, and nothing was working. It looked like a bunch of random garbage,” says Tom Henighan, a member of Anthropic’s technical staff. Then a run dubbed “Johnny”—each experiment was assigned a random name—began associating neural patterns with concepts that appeared in its outputs.“Chris looked at it, and…