AI World Models and Video. My world vision model for waking up at 4am to travel overseas is frankly a bit fuzzy and unreliable. But What’s an AI world model? My 2 cents explainer: It’s a model that builds an internal representation of a real-world, physical, [human] environment, and uses that to predict or simulate future events within that environment.
Until recently, research in AI world models has been very much focused on video games and Reinforcement Learning. But now, the boom of GenAI and large multi-modal models have triggered a new trend in AI world models based on large scale video understanding. But How good are these GenAI models in representing, understanding and predicting the world? Is GenAI the “right” approach for building AI world models? Let’s see…
OpenAI announced Sora, a new GenAI video model for world simulation. For starters, the Sora demos look really impressive. Checkout the link below. Sora is a closed, generative AI text-to-video, transformed-based model that -according to OpenAI researchers- was developed to “understand and simulate the physical world in motion.” Obviously, OpenAI is a closed-doors, AI commercial ops disguised as “AI for improving & saving humanity.” You can read the Sora blogpost and the “technical report” here: Video Generation models as World Simulators But as usual, you won’t get deep technical details in that, as OpenAI is not much about fully opening and sharing their research.
Generative AI models don’t understand the physical world. Generative AI models can produce impressively realistic images and videos like the ones above from Sora. But this paper demonstrates that GenAI images/videos have geometric features different from those of real images/videos. The researchers conclude that current Gen AI models cannot reliably reproduce geometric properties of the real world. Paper: Shadows Don’t Lie and Lines Can’t Bend! Generative Models don’t know Projective Geometry…for now

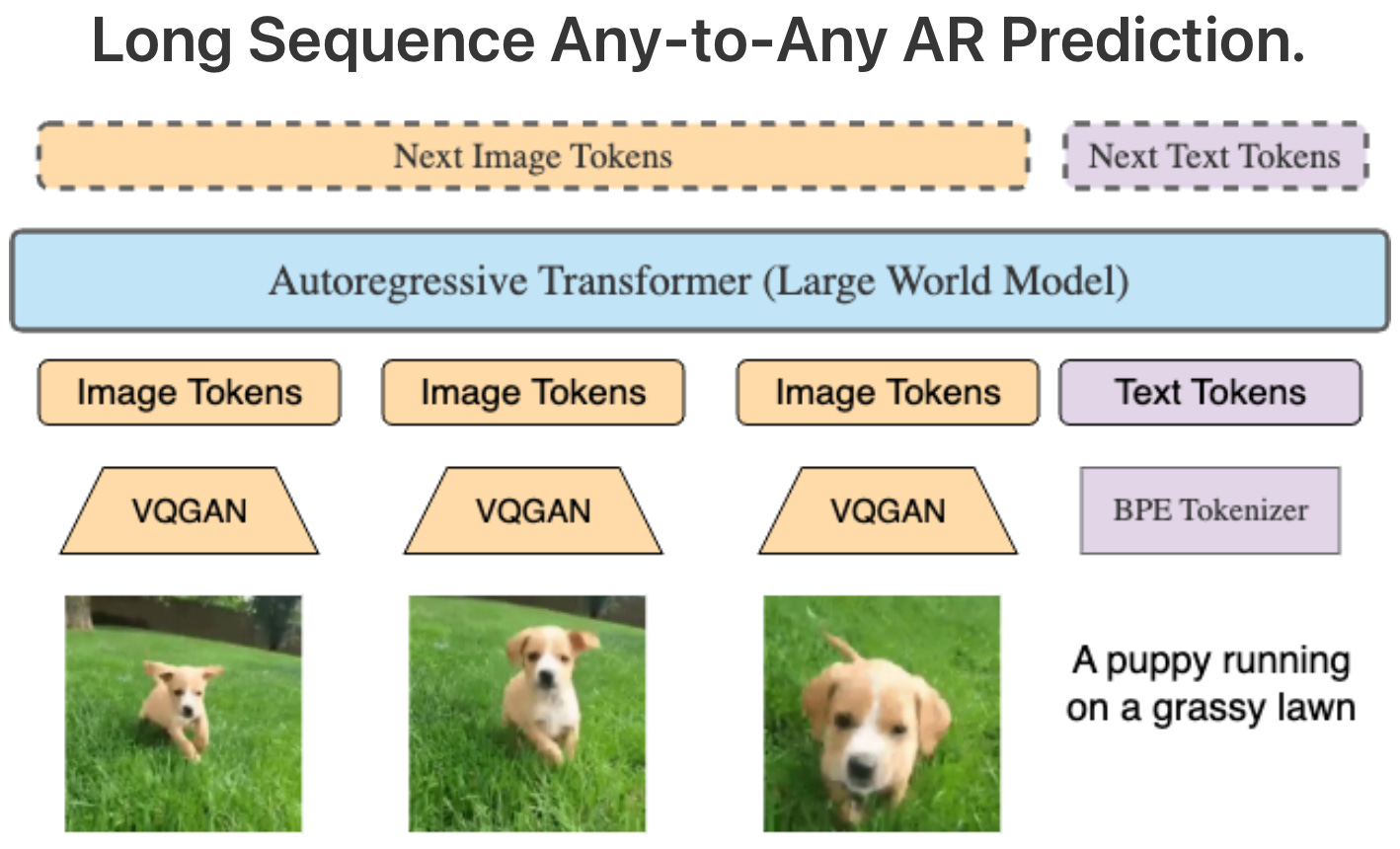
UC Berkeley open sources new Large World Model (LWM). Learning from millions of tokens of video and language sequences has huge challenges due to memory constraints, computational complexity, and limited datasets. To address these challenges, a group of top researchers at UCBerkeley just open sourced LWM, a video model trained on millions-length multimodal sequences. By open sourcing the model -unlike OpenAI- this group of researchers just opened the door for developing more powerful video models that can better understand human knowledge and the multimodal real world. Checkout the paper, model code, and demos: World Model on Million-Length Video and Language with RingAttention.
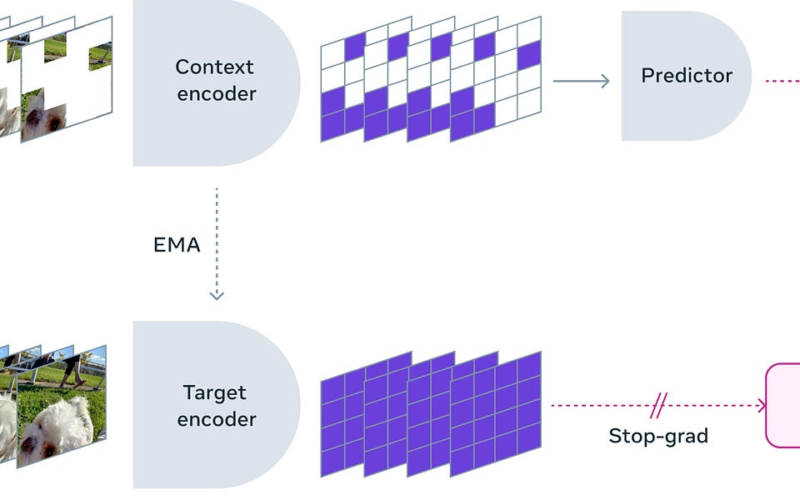
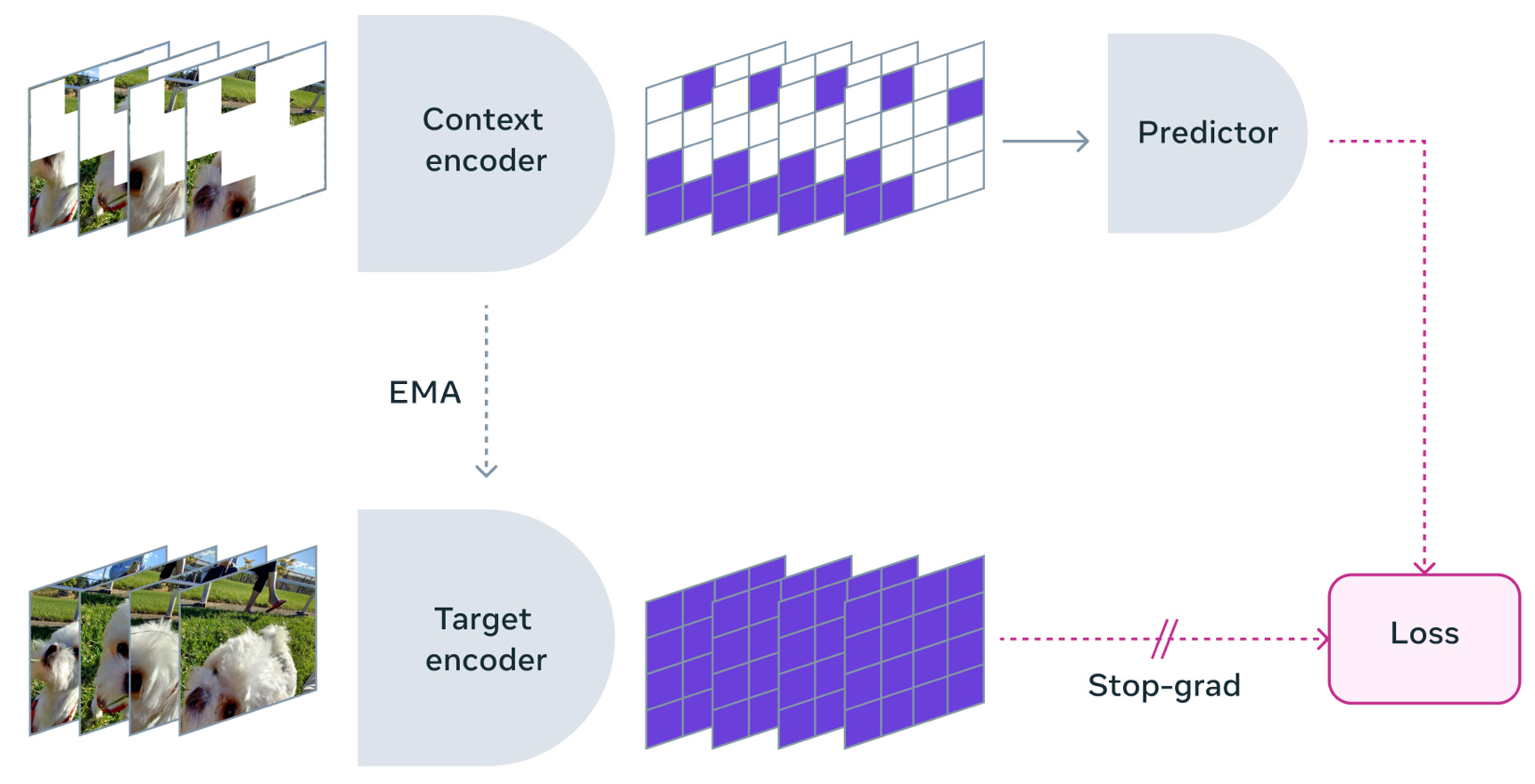
Meta AI V-JEPA: A new non-GenAI model for world understanding. Yann LeCun has been a very vocal, great advocate of exposing the limitations of Generative AI, Transformers, and VAE-based models. In Yann’s view, those models are limited in terms of: self-learning, self-adaptation, self-planning and in general developing world models in the way humans do. Released under Creative Commons research license, V-JEPA is a new kind of non-generative, self-supervised learning video model that learns by predicting missing or masked spatio-temporal regions in a video in a learned space. V-JEPA is clearly a new, fresh step towards a more grounded model understanding of the world. Blogpost, paper and code: The next step toward Yann LeCun’s vision of advanced machine intelligence (AMI).
Have a nice week.
-
Phidata Toolkit – Build AI Assistants Using Function Calling
-
An Open Foundation Model for Human-like, Expressive Text2Speech
-
BCG AgentKit: Rapidly Build High-quality Agent Apps, MIT license
-
On FlashAttention and Sparsity, Quantisation, & Efficient Inference
-
[free e-book] Stanford Speech & Language Processing (Feb 2024)
-
[free e-book] The Mathematical Engineering of Deep Learning (Feb 2024)
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol