So far, bigger and bigger language models have proven more and more capable. But does the past predict the future?
One popular view is that we should expect the trends that have held so far to continue for many more orders of magnitude, and that it will potentially get us to artificial general intelligence, or AGI.
This view rests on a series of myths and misconceptions. The seeming predictability of scaling is a misunderstanding of what research has shown. Besides, there are signs that LLM developers are already at the limit of high-quality training data. And the industry is seeing strong downward pressure on model size. While we can’t predict exactly how far AI will advance through scaling, we think there’s virtually no chance that scaling alone will lead to AGI.
Research on scaling laws shows that as we increase model size, training compute, and dataset size, language models get “better”. The improvement is truly striking in its predictability, and holds across many orders of magnitude. This is the main reason why many people believe that scaling will continue for the foreseeable future, with regular releases of larger, more powerful models from leading AI companies.
But this is a complete misinterpretation of scaling laws. What exactly is a “better” model? Scaling laws only quantify the decrease in perplexity, that is, improvement in how well models can predict the next word in a sequence. Of course, perplexity is more or less irrelevant to end users — what matters is “emergent abilities”, that is, models’ tendency to acquire new capabilities as size increases.
Emergence is not governed by any law-like behavior. It is true that so far, increases in scale have brought new capabilities. But there is no empirical regularity that gives us confidence that this will continue indefinitely.
Why might emergence not continue indefinitely? This gets at one of the core debates about LLM capabilities — are they capable of extrapolation or do they only learn tasks represented in the training data? The evidence is incomplete and there is a wide range of reasonable ways to interpret it. But we lean toward the skeptical view. On benchmarks designed to test the efficiency of acquiring skills to solve unseen tasks, LLMs tend to perform poorly.
If LLMs can’t do much beyond what’s seen in training, at some point, having more data no longer helps because all the tasks that are ever going to be represented in it are already represented. Every traditional machine learning model eventually plateaus; maybe LLMs are no different.
Another barrier to continued scaling is obtaining training data. Companies are already using all the readily available data sources. Can they get more?
This is less likely than it might seem. People sometimes assume that new data sources, such as transcribing all of YouTube, will increase the available data volume by another order of magnitude or two. Indeed, YouTube has a remarkable 150 billion minutes of video. But considering that most of that has little or no usable audio (it is instead music, still images, video game footage, etc.), we end up with an estimate that is much less than the 15 trillion tokens that Llama 3 is already using — and that’s before deduplication and quality filtering of the transcribed YouTube audio, which is likely to knock off at least another order of magnitude.
People often discuss when companies will “run out” of training data. But this is not a meaningful question. There’s always more training data, but getting it will cost more and more. And now that copyright holders have wised up and want to be compensated, the cost might be especially steep. In addition to dollar costs, there could be reputational and regulatory costs because society might push back against data collection practices.
We can be certain that no exponential trend can continue indefinitely. But it can be hard to predict when a tech trend is about to plateau. This is especially so when the growth stops suddenly rather than gradually. The trendline itself contains no clue that it is about to plateau.
{kind=link}
Two famous examples are CPU clock speeds in the 2000s and airplane speeds in the 1970s. CPU manufacturers decided that further increases to clock speed were too costly and mostly pointless (since CPU was no longer the bottleneck for overall performance), and simply decided to stop competing on this dimension, which suddenly removed the upward pressure on clock speed. With airplanes, the story is more complex but comes down to the market prioritizing fuel efficiency over speed.
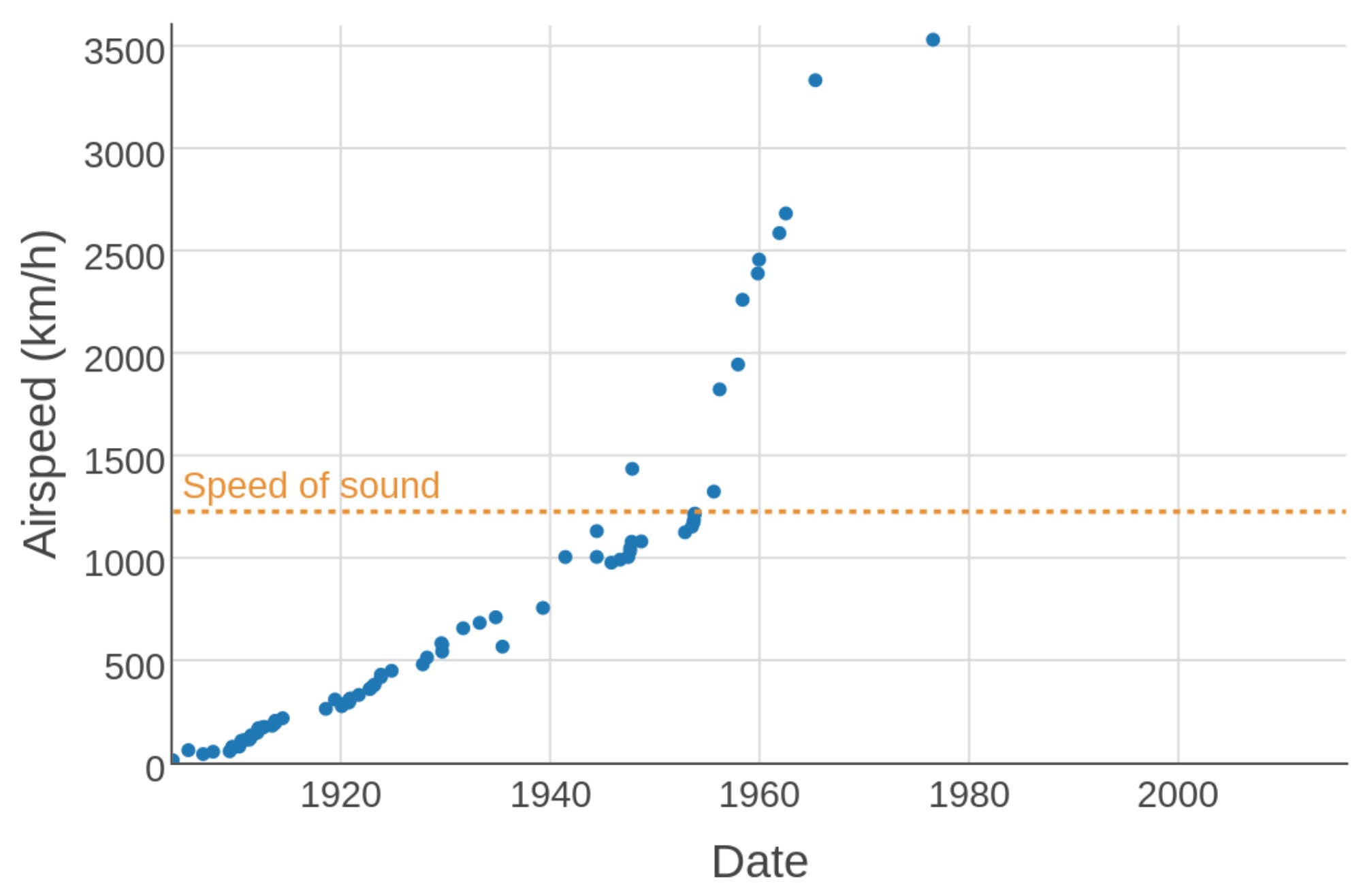
With LLMs, we may have a couple of orders of magnitude of scaling left, or we may already be done. As with CPUs and airplanes, it is ultimately a business decision and fundamentally hard to predict in advance.
On the research front, the focus has shifted from compiling ever-larger datasets to improving the quality of training data. Careful data cleaning and filtering can allow building equally powerful models with much smaller datasets.
Synthetic data is often suggested as the path to continued scaling. In other words, maybe current models can be used to generate training data for the next generation of models.
But we think this rests on a misconception — we don’t think developers are using (or can use) synthetic data to increase the volume of training data. This paper has a great list of uses for synthetic data for training, and it’s all about fixing specific gaps and making domain-specific improvements like math, code, or low-resource languages. Similarly, Nvidia’s recent Nemotron 340B model, which is geared at synthetic data generation, targets alignment as the primary use case. There are a few secondary use cases, but replacing current sources of pre-training data is not one of them. In short, it’s unlikely that mindless generation of synthetic training data will have the same effect as having more high-quality human data.
There are cases where synthetic training data has been spectacularly successful, such as AlphaGo, which beat the Go world champion in 2016, and its successors AlphaGo Zero and AlphaZero. These systems learned by playing games against themselves; the latter two did not use any human games as training data. They used a ton of calculation to generate somewhat high-quality games, used those games to train a neural network, which could then generate even higher-quality games when combined with calculation, resulting in an iterative improvement loop.
Self-play is the quintessential example of “System 2 –> System 1 distillation”, in which a slow and expensive “System 2” process generates training data to train a fast and cheap “System 1” model. This works well for a game like Go which is a completely self-contained environment. Adapting self-play to domains beyond games is a valuable research direction. There are important domains like code generation where this strategy may be valuable. But we certainly can’t expect indefinite self-improvement for more open-ended tasks, say language translation. We should expect domains that admit significant improvement through self-play to be the exception rather than the rule.
Historically, the three axes of scaling — dataset size, model size, and training compute — have progressed in tandem, and this is known to be optimal. But what will happen if one of the axes (high-quality data) becomes a bottleneck? Will the other two axes, model size and training compute, continue to scale?
Based on current market trends, building bigger models does not seem like a wise business move, even if it would unlock new emergent capabilities. That’s because capability is no longer the barrier to adoption. In other words, there are many applications that are possible to build with current LLM capabilities but aren’t being built or adopted due to cost, among other reasons. This is especially true for “agentic” workflows which might invoke LLMs tens or hundreds of times to complete a task, such as code generation.
In the past year, much of the development effort has gone into producing smaller models at a given capability level. Frontier model developers no longer reveal model sizes, so we can’t be sure of this, but we can make educated guesses by using API pricing as a rough proxy for size. GPT-4o costs only 25% as much as GPT-4 does, while being similar or better in capabilities. We see the same pattern with Anthropic and Google. Claude 3 Opus is the most expensive (and presumably biggest) model in the Claude family, but the more recent Claude 3.5 Sonnet is both 5x cheaper and more capable. Similarly, Gemini 1.5 Pro is both cheaper and more capable than Gemini 1.0 Ultra. So with all three developers, the biggest model isn’t the most capable!
Training compute, on the other hand, will probably continue to scale for the time being. Paradoxically, smaller models require more training to reach the same level of performance. So the downward pressure on model size is putting upward pressure on training compute. In effect, developers are trading off training cost and inference cost. The earlier crop of models such as GPT-3.5 and GPT-4 was under-trained in the sense that inference costs over the model’s lifetime are thought to dominate training cost. Ideally, the two should be roughly equal, given that it is always possible to trade off training cost for inference cost and vice versa. In a notable example of this trend, Llama 3 used 20 times as many training FLOPs for the 8 billion parameter model as the original Llama model did at roughly the same size (7 billion).
One sign consistent with the possibility that we won’t see much more capability improvement through scaling is that CEOs have been greatly tamping down AGI expectations. Unfortunately, instead of admitting they were wrong about their naive “AGI in 3 years” predictions, they’ve decided to save face by watering down what they mean by AGI so much that it’s meaningless now. It helped that AGI was never clearly defined to begin with.
Instead of viewing generality as a binary, we can view it as a spectrum. Historically, the amount of effort it takes to get a computer to program a new task has decreased. We can view this as increasing generality. This trend began with the move from special-purpose computers to Turning machines. In this sense, the general-purpose nature of LLMs is not new.
This is the view we take in the AI Snake Oil book, which has a chapter dedicated to AGI. We conceptualize the history of AI as a punctuated equilibrium, which we call the ladder of generality (which isn’t meant to imply linear progress). Instruction-tuned LLMs are the latest step in the ladder. An unknown number of steps lie ahead before we can reach a level of generality where AI can perform any economically valuable job as effectively as any human (which is one definition of AGI).
Historically, standing on each step of the ladder, the AI research community has been terrible at predicting how much farther you can go with the current paradigm, what the next step will be, when it will arrive, what new applications it will enable, and what the implications for safety are. That is a trend we think will continue.
A recent essay by Leopold Aschenbrenner made waves due to its claim that “AGI by 2027 is strikingly plausible”. We haven’t tried to give a point-by-point rebuttal here — most of this post was drafted before Aschenbrenner’s essay was released. His arguments for his timeline are entertaining and thought provoking, but fundamentally an exercise in trendline extrapolation. Also, like many AI boosters, he conflates benchmark performance with real-world usefulness.
Many AI researchers have made the skeptical case, including Melanie Mitchell, Yann LeCun, Gary Marcus, Francois Chollet, and Subbarao Kambhampati and others.
Dwarkesh Patel gives a nice overview of both sides of the debate.
Acknowledgements. We are grateful to Matt Salganik, Ollie Stephenson, and Benedikt Ströbl for feedback on a draft.
Source link
lol