Beyond GenAI & LLMs. GenAI & LLMs have literally kidnapped the DL/ML space, and pretty much sucked all the investment and top AI minds, as if there is nothing else under the sun. There are literally hundreds of GenAI models out there. Many of these GenAI models have questionable value or are a repeat-rinse-recycle of the same. Checkout this mega spreadsheet: An Annotated and Updated Directory of GenAI Models.
So: Many DL/ML researchers are starting to question the LLM status quo: Shouldn’t we focus $ and brains in new, alt AI/DL paradigms beyond LLMs? And: Do we need so many GenAI models that generate pretty faces and cat images & videos from text? And: How is that helping in to advance the DL/ML field? Here are a few areas that may deserve your attention beyond just LLMs.
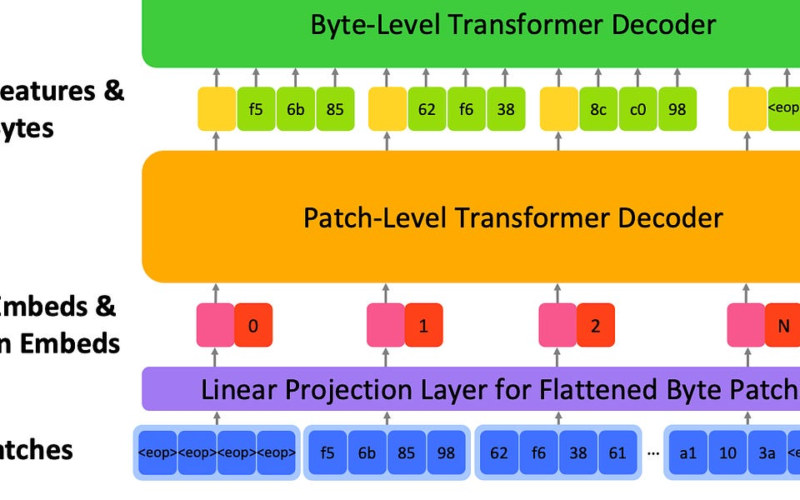
A fresh, new approach beyond next-token prediction. Tokekinsation and token prediction are core elements behind LLMs. However, tokenisation is also one of the root cause of many problems in LLMs. Today most DL approaches ignore bytes and encoding in binary format. Enter bGPT, a new model with next byte prediction that matches specialised models in performance across text, audio, and images modalities. bGPT supports generative modelling via next byte prediction on any type of data, only limited by computational resources. Paper and repo: Beyond Language Models: Byte Models are Digital World Simulators.
More effective Graph Representation Learning (GRL). The aim of GRL is to encode high-dimensional sparse graph-structured data into low-dimensional dense vectors. GRL has evolved significantly in recent years, and it is a central approach in many DL/ML tasks and problems today. Some new exciting stuff is happening in GRL.
A Comprehensive Survey on Deep Graph Representation Learning (Feb 2024) This paper is a very comprehensive survey on SOTA and current deep graph representation learning algorithms and methods. The paper summarises the essential components of GRL and categorises existing and most recent advanced learning paradigms.

Graph Representation Learning [free book]. A great comprehensive review of traditional graph methods, graph learning, embedding graph data, graph neural networks, and deep generative models of graphs.
[new] One-Shot GRL competitive with SOTA DL methods. A novel, simple, fast, and efficient approach for semi-supervised learning on graphs. This approach is competitive with SOTA deep learning methods, without the need for computationally expensive training.
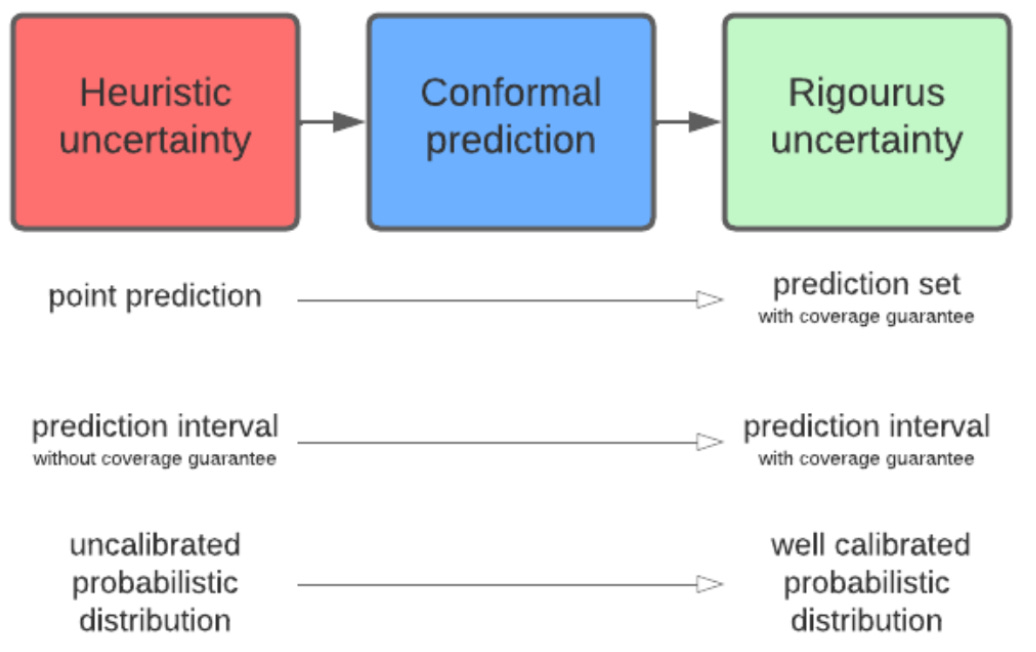
Combining Conformal Prediction with ML. Conformal Prediction is becoming quite popular across ML researchers interested in uncertainty estimation. In ML models, bad predictions with high uncertainty cannot be distinguished from good predictions with high confidence. Enter Conformal Prediction (CP): a model-agnostic, finite-sample size and distribution free uncertainty estimation framework. CP can be applied to all types of models, even pre-trained ones, requiring only the exchangability of the data. Here is a free book: A Intro to Conformal Prediction for Machine Learners.
More efficient DL/ML optimisation methods. The “scale is all you need” trend, and the exponential growth of large models’ size with 10’s of billions of parameters, have triggered a revival in new DL optimisation methods. Optimisation methods and the optimiser used to fit a model are absolutely crucial in DL. Understanding how optimisation works and applying it effectively are key aspects to modern DL.
A Guide to the Math for Deep Learning Optimisation. This is a beautifully written blogpost, in which Tidavar takes a deep dive into the mathematics of optimisers and how they handle the vast complexity within a huge search grid for optimising a deep neural net.
The Math behind Adam Optimiser. The Adam Optimiser is one of the most popular optimisers but few people truly understand its underlying mechanisms and how to best leverage Adam depending on the ML tasks/scenarios. This blogpost afaik, is one of the best, most concise, and clear overviews of The Adam Optimiser.

CoRe: A new, all-in one ML optimiser that beats SOTA optimisation algos (Feb 2024). Researchers at ETH Zurich, just introduced Continual Resilient (CoRe) optimiser. CoRe shows superior performance compared to other state-of-the-art first-order gradient-based optimizers, including Adam.
Have a nice week.
-
[brilliant] Jailbreaking GPT-4 & Others with ASCII Art Attacks
-
Opensourcing Charlie Mnemonic: 1st AI Assistant with Long-Term Memory
-
Deepmind Griffin & Hawk Models: Combining the Best of RNNs & Transformers
-
MS Research – The Era of 1-bit LLMs: All LLMs are in 1.58 Bits
-
UC Berkeley – Approaching Human-Level Forecasting with Language Models
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol