GPT (Generative Pretrained Transformer) models have changed the landscape of the NLP in the last few years. In 2024, we are seeing complex and close-sourced models like OpenAI’s ChatGPT-3.5 & ChatGPT-4, Anthropic’s Claude, and Google’s Bard. However, the beginnings of these Transformer models were simpler and open-source. Vaswani et al. introduced the Transformer architecture. After that, two more seminal papers by OpenAI, GPT-1 and GPT-2 laid the foundation of almost all the NLP innovations to date. In this article, we will discuss the GPT-1 and GPT-2 models in detail along with their contributions and results.
We will cover the following topics in this article
- We will start with the importance of GPT-1 and GPT-2 papers.
- This will lead to the discussion of the architecture of both the models and the differences between them.
- Next, we will cover the pretraining methodology of both models.
- Finally, we will discuss their zero-shot performance for several tasks.
This article will also form the basis of several future posts where will fine-tune models like GPT-2, OPT, and many other pretrained Language Models.
Why are GPT-1 and GPT-2 Important?
The release of GPT-1 and GPT-2 marked some important milestones in the world of Language Models.
GPT-1 was introduced by OpenAI researchers in the paper named Improving Language Understanding by Generative Pre-Training in 2018. Following that, GPT-2 was introduced in Language Models are Unsupervised Multitask Learners in 2019.
Following are some of the interesting observations about the approach of the papers.
- GPT-1 and GPT-2 were the last open-source GPT models from OpenAI (as of writing this).
- The papers talk about the architecture, dataset, and pretraining strategy.
- These two papers and the codebase provide some interesting insights into zero-shot prompts and performance for various tasks. We will discuss these in detail in the later phase of the article.
It is rarer nowadays for organizations to open-source, disclose the dataset, and talk about training strategy unless the entire project is open-source, like the Llama models by Meta (we will talk about these in detail in future posts).
The Architecture of GPT-1 and GPT-2
Both GPT-1 and GPT-2 are pretrained Transformer based Language Models. The primary objective of both is next word prediction.
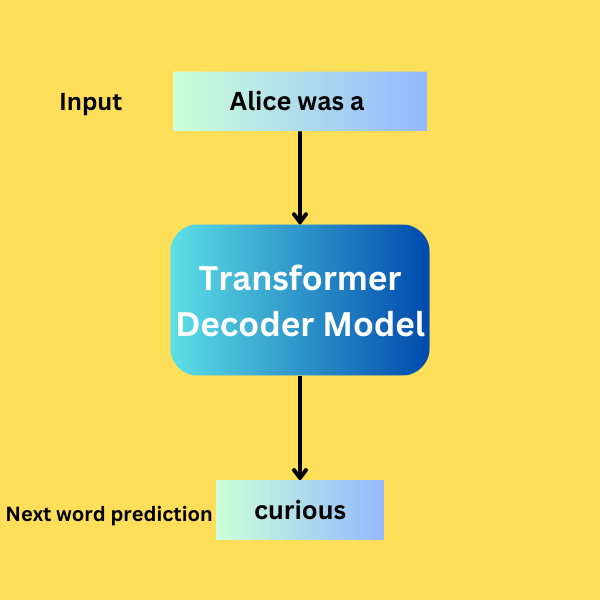
The models follow almost the same decoder architecture as described in the Attention is All You Need paper. As these are next word prediction models, they do not require an encoder that is used for Sequence-to-Sequence prediction tasks like language translation. However, these Transformer models are excellent at text generation.
Following is the decoder architecture from the Attention is All You Need paper.
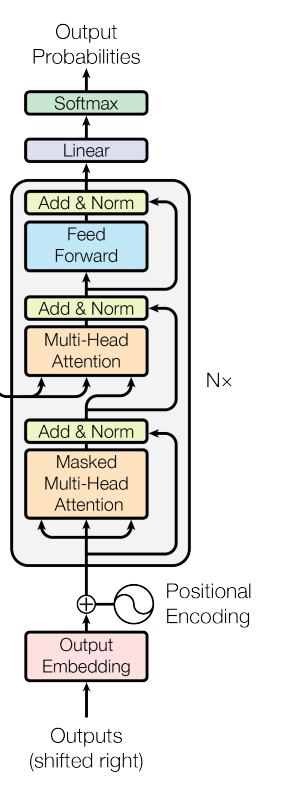
GPT-1 contains 12 such Transformer Decoder blocks with positional embedding before that. GPT-2 follows the same architecture with architectural differences in terms of scale.
The original code was implemented in TensorFlow by OpenAI. However, we will refer to the Hugging Face transformers library to talk about the implementation details.
Implementation Details and Differences Between GPT-1 and GPT-2
GPT-1 follows the original Transformer decoder almost exactly, i.e. a masked attention decoder that prevents the model from attending to padded tokens. There is only one model in the family with approximately 116.5 million parameters.
Furthermore, GPT-1 uses the post-normalization as described in the first version of the Transformer paper by Vaswani et al.
Coming to GPT-2, there are some stark differences. First of all, GPT-2 uses pre-normalization that indicates the usage of Layer Normalization before attention and feed forward blocks. This leads to better stability during training and also uses a higher starting learning rate. GPT-2 also contains 4 implementations in the original codebase according to scale.
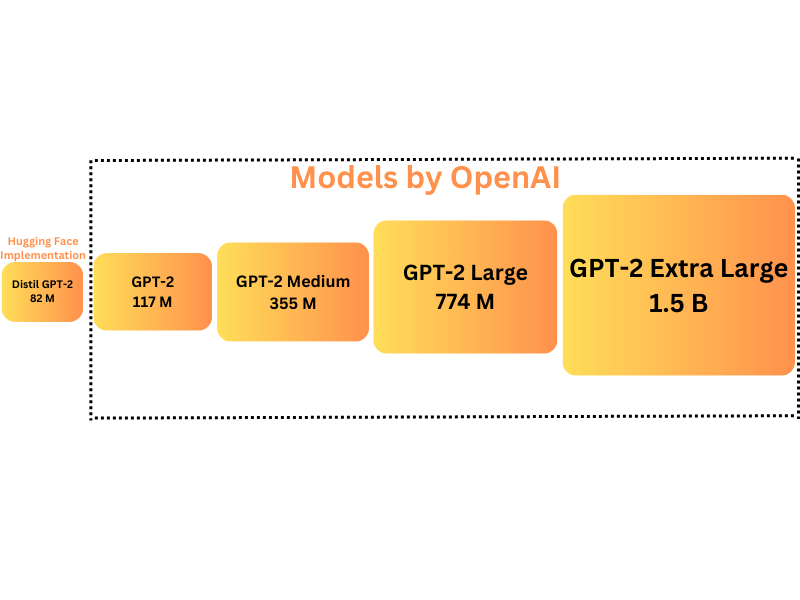
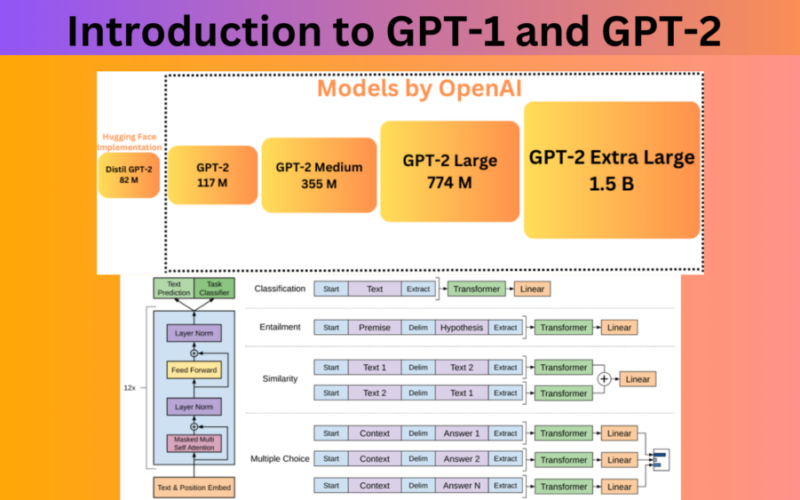
The smallest GPT-2 model is roughly the same size as GPT-1. The GPT-2 Medium model contains around 355 million parameters. GPT-2 Large contains 774 million parameters and GPT-2 Extra Large contains 1.5 billion parameters. In addition to these, the transformers library contains an additional Distil GPT model which is the smallest with 82 million parameters.
One interesting observation is the usage of 1D Convolutional layer instead of the Linear layer in both models. The 1D Convolutions are part of the Attenion block and the MLP (Multi-Layer Perceptron) block. These 1D Convolution blocks are capable of dealing with sequences just like the Linear layers.
Architectural Details
Going into a bit more detail of the GPT-1 architecture. It is a 12-layer decoder-only model with 12 attention heads. It has an embedding dimension of 768 and uses a vocabulary of 40478 unique words. According to the original paper, it was trained on a sequence length of 512.
The base GPT-2 model has a very similar architecture. However, the sequence length is 1024 which helps in capturing a longer context. As discussed earlier, it uses pre-normalization unlike GPT-1. Furthermore, the vocabulary is increased to 50257 unique words.
As the model sizes keep increasing in the GPT-2 family, the embedding dimensions become 1024, 1280, and 1600 respectively. Also, the number of decoder layers is 24, 36, and 48 respectively in each of the later models. The following image from the GPT-2 paper summarizes the same for each model.
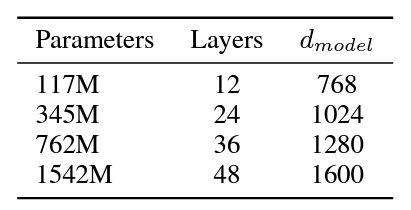
Pretraining Methodologies
In this section, we will briefly discuss the pretraining strategy and datasets for both the language models.
GPT-1
The pretraining technique of text generation models is perhaps the most important part. It has a large impact on the model, overall, and to a large extent also determines how the model will perform when fine-tuned on different tasks.
In general, the pretraining does not require labeled datasets. Just text documents are enough, and we train the model in an unsupervised manner to predict the next token/word. Commonly, we call this unsupervised pretraining.
Although nowadays, language models are pretrained on terabytes of internet-scale data, GPT-1 was trained on just the BookCorpus dataset which is a collection of 7000 books spanning somewhere around 3-5 gigabytes. Today, we can easily download this dataset from Hugging Face.
GPT-2
GPT-2 uses a larger and more diverse dataset for pretraining. The authors crawl a new dataset from the internet, WebText. The final dataset contains around 8 million text documents and is around 40 GB in size.
Unfortunately, the original WebText dataset is not open-source. However, efforts from the community led to the creation of the OpenWebText corpus which is a similar scale dataset available to everyone for experimentation and training.
Training on large datasets can be compute-intensive, and expensive, and requires specialized code for parallelism and efficiency. That’s why it is worth taking a moment to thank the authors, researchers, and open-source contributors who release the model weights upon which we can build and fine-tune.
Zero-Shot Strategies and Performance for GPT-2
The GPT-2 paper share some interesting insights on how we should structure the input text/sentences for different tasks in a zero-shot manner.
The primary takeaway from the GPT-2 paper is that Language Models, after pretraining, are good at multiple tasks without fine-tuning. This means that we should be able to use the same model for different language tasks. Although this is more common today and systems like ChatGPT work well, GPT-2 was not that good for all tasks.
Text Summarization
In the GPT-2 paper, after pretraining, the authors check the zero-shot performance of the model for text summarization. Because GPT-2 is a text generation model, the input has to be carefully curated. For pretraining, preparing the input data is simpler as the model just needs to see the words till position p and has to predict the word at position p+1.
However, for summarization, each input sample has to precede the summarized sequence. To induce summarization behavior, after each sample, the authors append TL;DR: (task hint) and then the summary. although it may not be perfect, a lot of material online follows the same format. Following this, the authors find that this approach works quite well.
Furthermore, the GPT-2 model falls behind by 6.2 points in the ROUGE score when we remove the task hint. This shows that NLP models (and autoregressive models in general) are sensitive to input data. Also, it is worthwhile to note that this approach, although works well, is not able to beat the previous state-of-the-art.
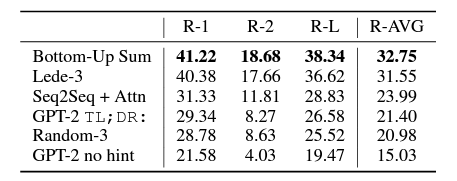
Language Translation
Language Translation is another common real-world task with several use cases. Here, the authors first give several inputs of language translation pairs in the following manner:
english sentence = french sentence
Then a final prompt is given to the model as english sentence =, expecting the model to output the French sentence.
On WMT-14 English to French translation, the GPT-2 (largest) model performs slightly worse than the then current state-of-the-art model.
For French to English translation, with a BLEU score of 11.5, although it surpasses several other unsupervised architectures, it falls behind the best one which has a BLEU score of 33.5.
This is still impressive because only 10 MB of the 40 GB data contained French text while pretraining.
Question Answering
For zero-shot question answering, the authors follow the format of answer the question, document, question, answer. The experiment was performed on the Natural Questions dataset which was not a part of the WebText pretraining dataset.
For this task, the paper shares the performance of both, the smallest and the largest GPT-2 model. The smallest GPT-2 model answers less than 1% of the questions correctly even for the most common questions.
On the same questions, the largest GPT-2 model answers the question correctly 5.3 times more. This shows that larger models tend to perform better on several zero-shot tasks compared to smaller models with the same architecture. Most probably, this is one of the first instances where OpenAI researchers may have figured out to go for the 175 billion parameter GPT-3 model as their next objective.
Further Reading
The GPT-2 paper covers a lot more material in its Appendix section including perplexity of the models, scaling performance, and different prompt-answer performance. I highly recommend going through them.
In future articles, we will try to fine-tune GPT-2 models for several of the tasks mentioned above for zero-shot performance. We can check how the model performs when we fine-tune for these tasks.
Furthermore, you can read the following NLP articles covering a wide range of topics:
Summary and Conclusion
We discussed the GPT-1 and GPT-2 models and papers in the article. Starting from a brief on the architecture of both to the zero-shot performance of GPT-2 on several tasks, we covered some important parts. Hopefully, this provides some insights into your research and training process as well. I hope that this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
References
Liked it? Take a second to support Sovit Ranjan Rath on Patreon!

Source link
lol