
New Trends in Vision-Language Models (VLMs.) The evolution of VLMs in recent months has been pretty impressive. Today VLMs exhibit some amazing capabilities. See the two links below on what VLMs can do and how they work:
But still VLMs are facing some challenges for example in terms of: multimodal training datasets, resolution, long-form modality, vision-language integration, and concept understanding. Somewhat along those lines, I see 5 trends happening in VLMs: 1) VLMs run on local environment 2) Emerging VLM videoagents 3) Unified structure learning for VLMs 4) Personalisation of VLMs and 5) Fixing the VLM resolution curse. Let’s see…
VLMs on local environment. In this blogpost, an independent AI researcher writes about playing around with VLMs using only a local environment. Inspired by Phi-2: The surprising power of small LMs– and using Facebook AI AnyMAL multimodality method, the researcher describes in detail the challenges and different architectures until achieving some decent results in a local environment, which are not close to academic SOTA. Blogpost: Findings on VLMs
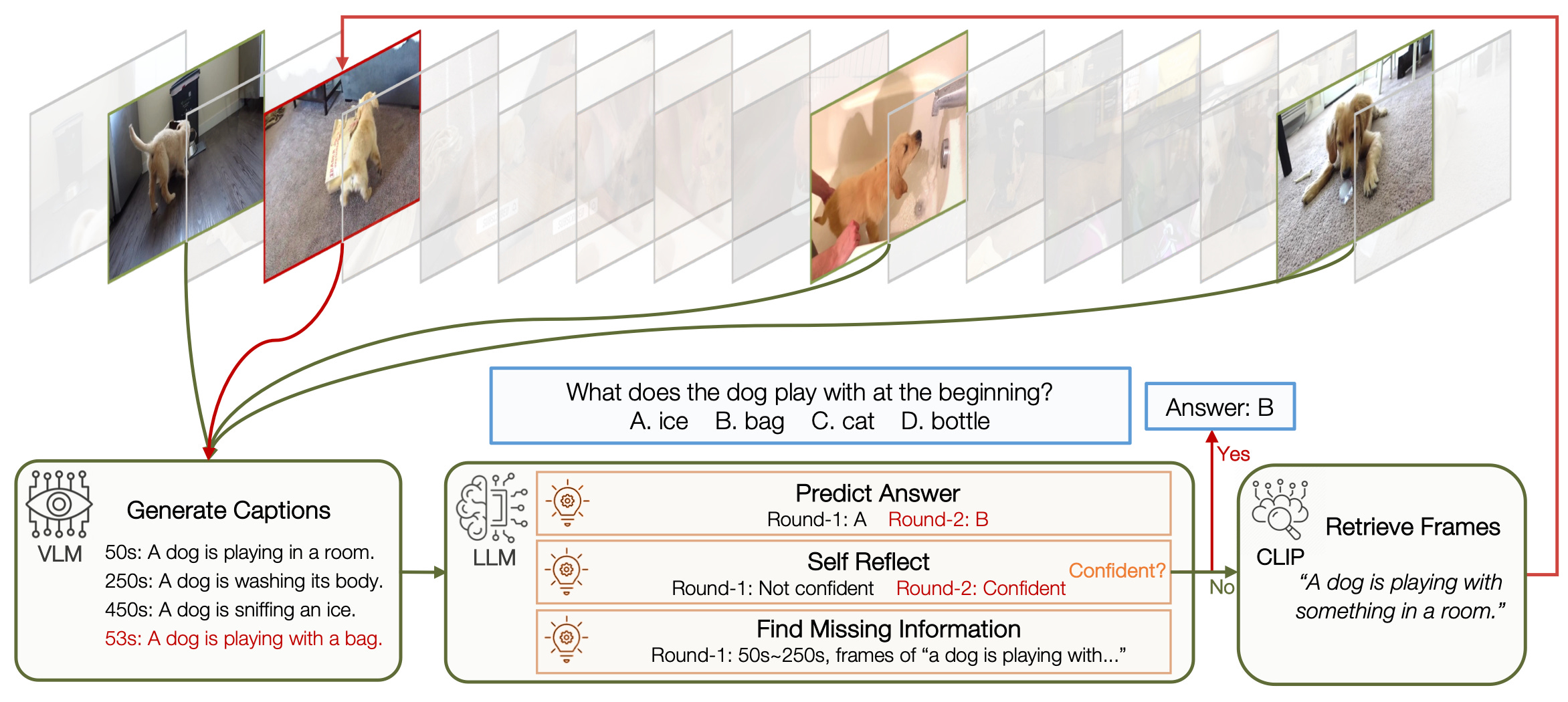
New SOTA in long-form video understanding. Researchers at Standford, introduced a new approach for video understanding. The approach combines an LLM agent, a vision-language model (VLM), and contrastive language-image model (CLIP). The researchers claim this approach is superior to current SOTA in video understanding. Paper: VideoAgent: Long-form Video Understanding with LLM as Agent
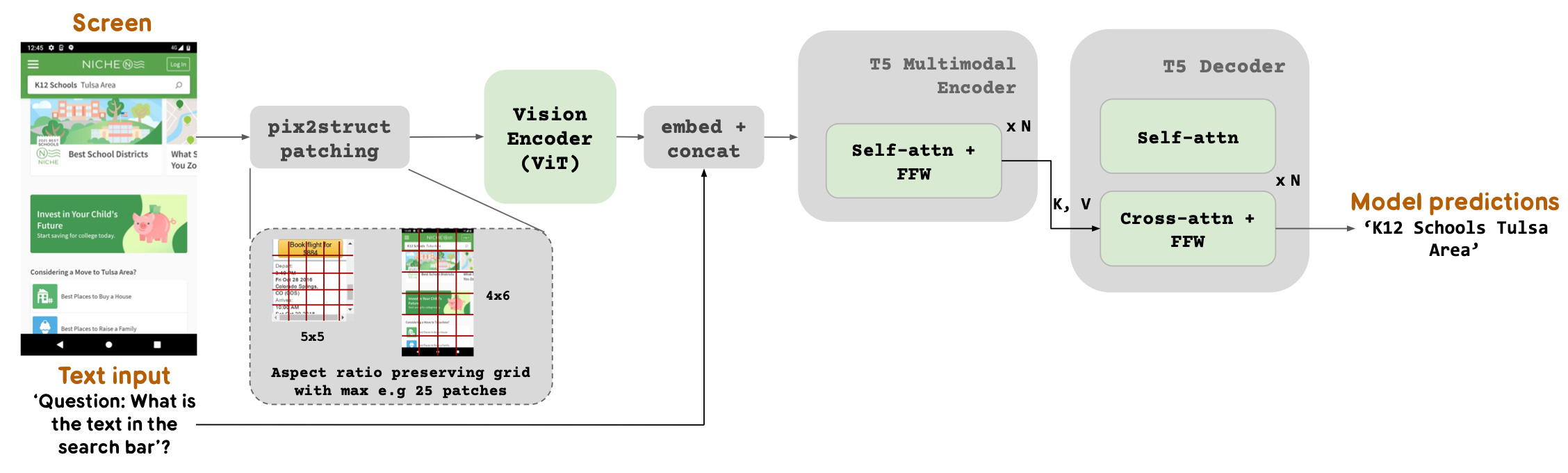
New SOTA in UI & infographics understanding. Researchers at Google, recently introduced a novel vision-language model that specialises in UI and infographics understanding. The model was trained on a unique mixture of datasets containing novel screen annotations, and types and location of UI elements. The researchers claim the model achieves SOTA in UI & infographics understanding. Paper: ScreenAI: A Vision-Language Model for UI and Infographics Understanding
New SOTA in visual document understanding. Researchers at Alibaba just introduced a new model for visual document understanding that uses Unified Structure Learning (USL). The USL model learns on structure-aware parsing tasks and multi-grained text localisation tasks across 5 domains: document, webpage, table, chart, and natural image. The researchers claim the model achieves SOTA. Paper: mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding

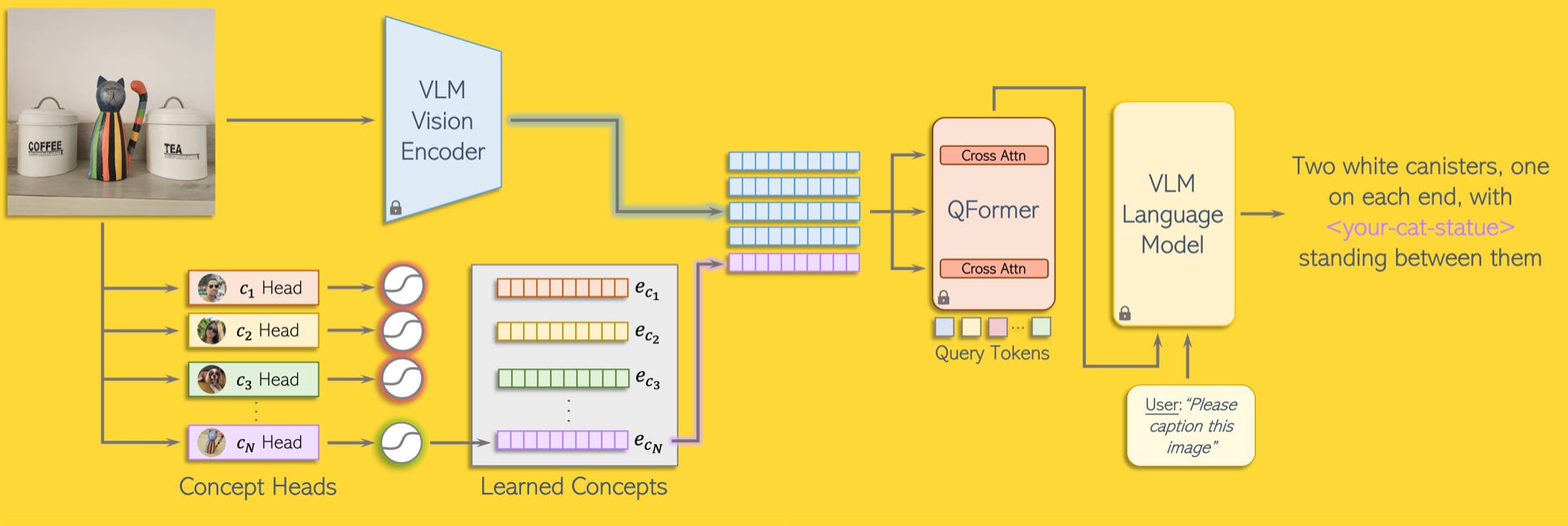
Personalisation of VLMs. Most VLMs lack an understanding of user-concepts. Researchers at Snap et al. just introduced MyVLM, a new way to personalise VLMs. Given a set of images depicting user-specific concepts, the researchers augmented a pretrained vision-language model (VLM) and used concept embeddings to understand and reason over these user concepts. Th researchers applied MyVLM to BLIP-2, LlaVA 1.6 and MiniGPT-v2 models for personalised captioning, visual question-answering, and referring expression comprehension. Checkout the project page, code, data and demos here: MyVLM: Personalising VLMs for User-Specific Queries
Fixing the resolution curse in VLMs. Resolution is a key problem in VLMs. VLMs can’t zoom. They are limited by the resolution of the vision encoder, and usually, it is not super large based on the pre-trained vision encoder. In this blogpost, Alex explains how you can use Visual Search, Visual Cropping and MC-LLaVA to fix this problem. Blogpost: Breaking resolution curse of vision-language models.

Have a nice week.
-
Visualisation of Large-scale Multimodal Datasets with Nomic Atlas
-
Berkeley AIR – A New Approach to Modelling Extremely Large Images
-
Mistral + Snowflake: The New Frontier in SQL Copilot Products
-
Cosmopedia: How to Create Large-scale Synthetic Data for Pre-training
-
Claude-investor: Generative Stocks Investment Recommendations
-
Devika – An Agentic AI Software Engineer that Follows Human Instructions
-
DenseFormer: Faster Transformer Inference with Depth Weighted Averaging
-
LlamaFactory v.2: Unified Efficient Fine-Tuning of 100+ Language Models
-
Google Research- A Bag of Tricks for Few-Shot Class-Incremental Learning
-
Common Corpus: The Largest Public Domain Dataset, 500 Billion Words
-
DROID (Distributed Robot Interaction Dataset), 76K Demonstrations
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Source link
lol